 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamiltonian Monte Carlo Without Detailed Balance
Mar 25, 2016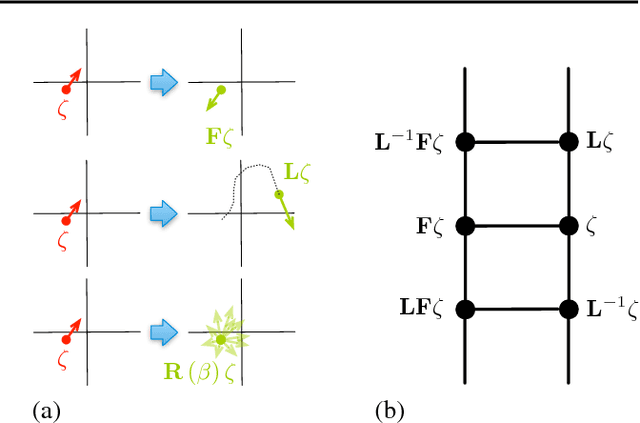
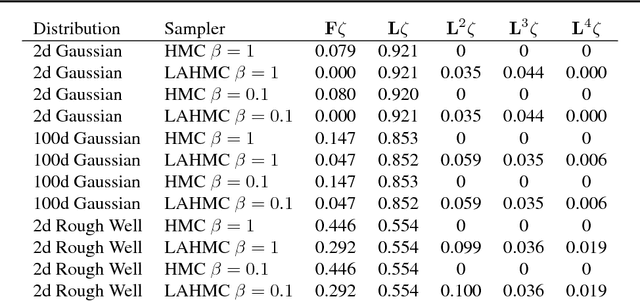
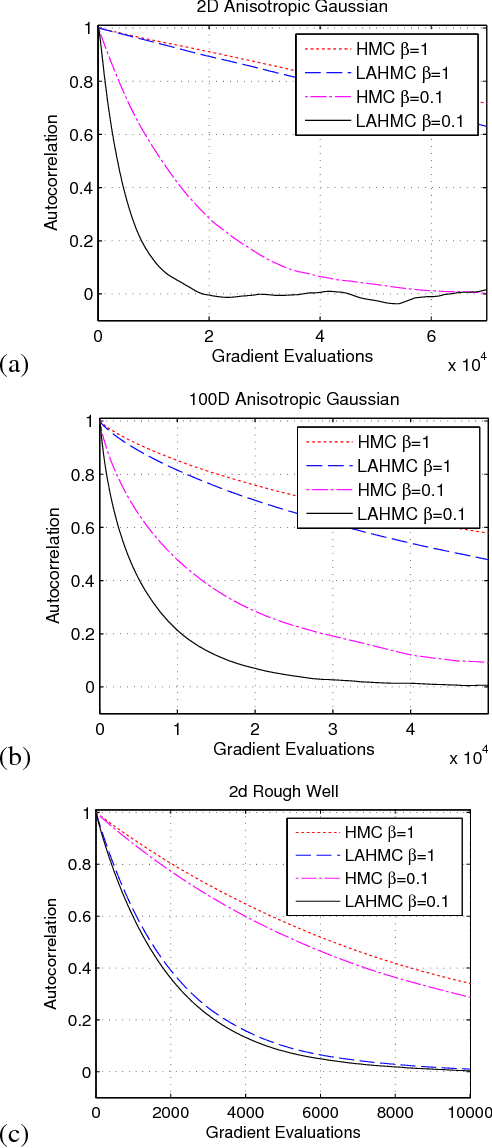
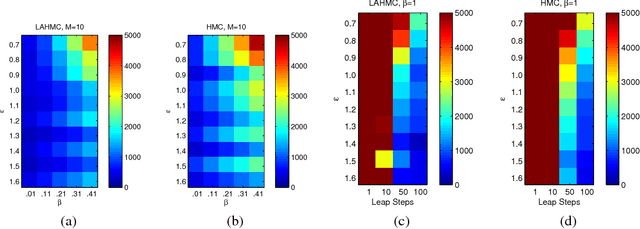
We present a method for performing Hamiltonian Monte Carlo that largely eliminates sample rejection for typical hyperparameters. In situations that would normally lead to rejection, instead a longer trajectory is computed until a new state is reached that can be accepted. This is achieved using Markov chain transitions that satisfy the fixed point equation, but do not satisfy detailed balance. The resulting algorithm significantly suppresses the random walk behavior and wasted function evaluations that are typically the consequence of update rejection. We demonstrate a greater than factor of two improvement in mixing time on three test problems. We release the source code as Python and MATLAB packages.
A universal tradeoff between power, precision and speed in physical communication
Mar 24, 2016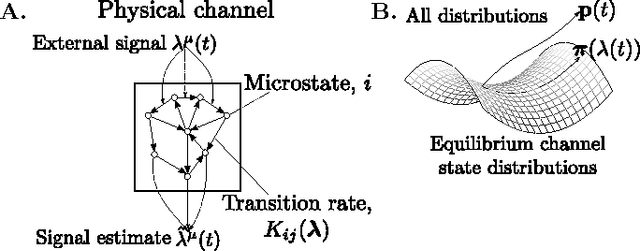
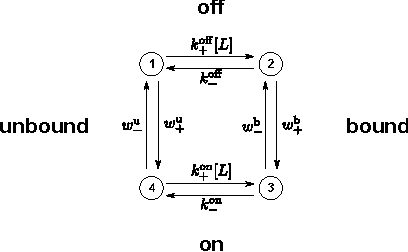
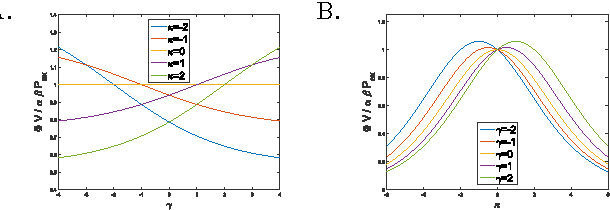
Maximizing the speed and precision of communication while minimizing power dissipation is a fundamental engineering design goal. Also, biological systems achieve remarkable speed, precision and power efficiency using poorly understood physical design principles. Powerful theories like information theory and thermodynamics do not provide general limits on power, precision and speed. Here we go beyond these classical theories to prove that the product of precision and speed is universally bounded by power dissipation in any physical communication channel whose dynamics is faster than that of the signal. Moreover, our derivation involves a novel connection between friction and information geometry. These results may yield insight into both the engineering design of communication devices and the structure and function of biological signaling systems.
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Nov 18, 2015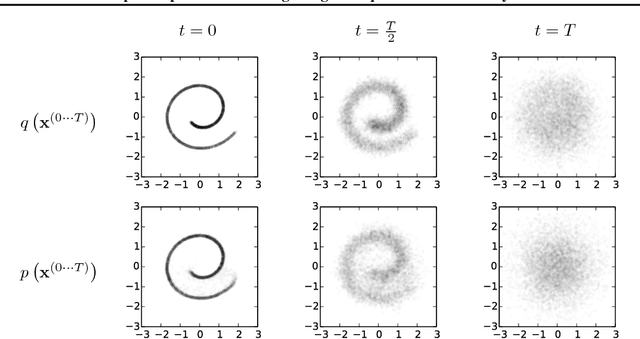

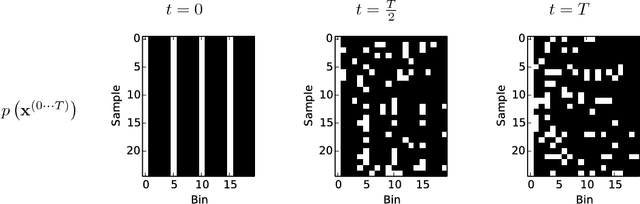

A central problem in machine learning involves modeling complex data-sets using highly flexible families of probability distributions in which learning, sampling, inference, and evaluation are still analytically or computationally tractable. Here, we develop an approach that simultaneously achieves both flexibility and tractability. The essential idea, inspired by non-equilibrium statistical physics, is to systematically and slowly destroy structure in a data distribution through an iterative forward diffusion process. We then learn a reverse diffusion process that restores structure in data, yielding a highly flexible and tractable generative model of the data. This approach allows us to rapidly learn, sample from, and evaluate probabilities in deep generative models with thousands of layers or time steps, as well as to compute conditional and posterior probabilities under the learned model. We additionally release an open source reference implementation of the algorithm.
A Markov Jump Process for More Efficient Hamiltonian Monte Carlo
Oct 11, 2015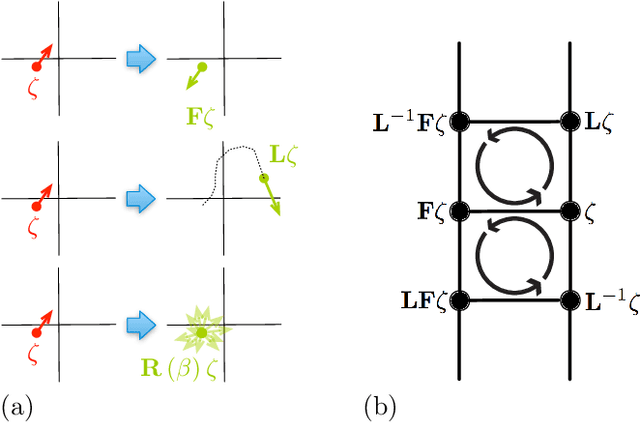
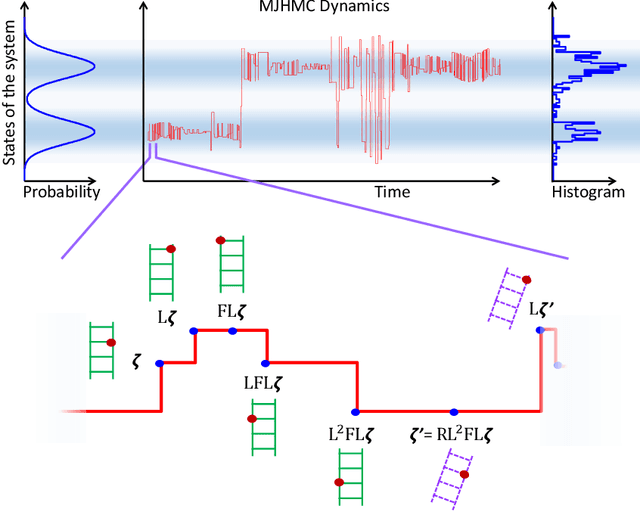
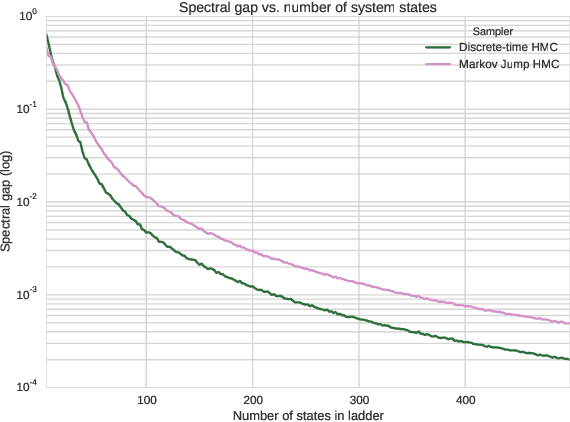
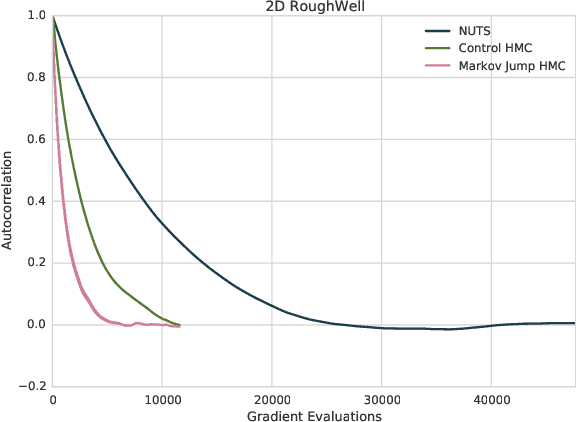
In most sampling algorithms, including Hamiltonian Monte Carlo, transition rates between states correspond to the probability of making a transition in a single time step, and are constrained to be less than or equal to 1. We derive a Hamiltonian Monte Carlo algorithm using a continuous time Markov jump process, and are thus able to escape this constraint. Transition rates in a Markov jump process need only be non-negative. We demonstrate that the new algorithm leads to improved mixing for several example problems, both by evaluating the spectral gap of the Markov operator, and by computing autocorrelation as a function of compute time. We release the algorithm as an open source Python package.
Deep Knowledge Tracing
Jun 19, 2015
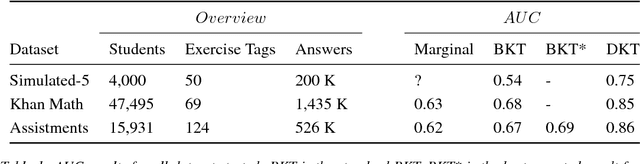
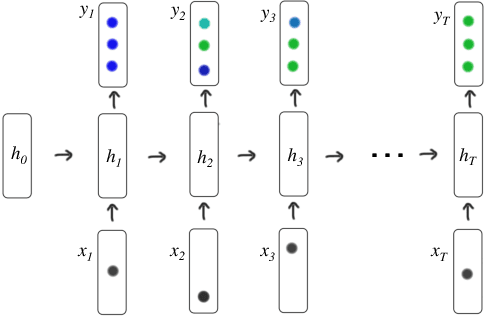
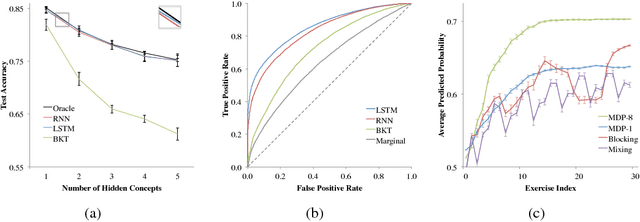
Knowledge tracing---where a machine models the knowledge of a student as they interact with coursework---is a well established problem in computer supported education. Though effectively modeling student knowledge would have high educational impact, the task has many inherent challenges. In this paper we explore the utility of using Recurrent Neural Networks (RNNs) to model student learning. The RNN family of models have important advantages over previous methods in that they do not require the explicit encoding of human domain knowledge, and can capture more complex representations of student knowledge. Using neural networks results in substantial improvements in prediction performance on a range of knowledge tracing datasets. Moreover the learned model can be used for intelligent curriculum design and allows straightforward interpretation and discovery of structure in student tasks. These results suggest a promising new line of research for knowledge tracing and an exemplary application task for RNNs.
Fast large-scale optimization by unifying stochastic gradient and quasi-Newton methods
Nov 30, 2014

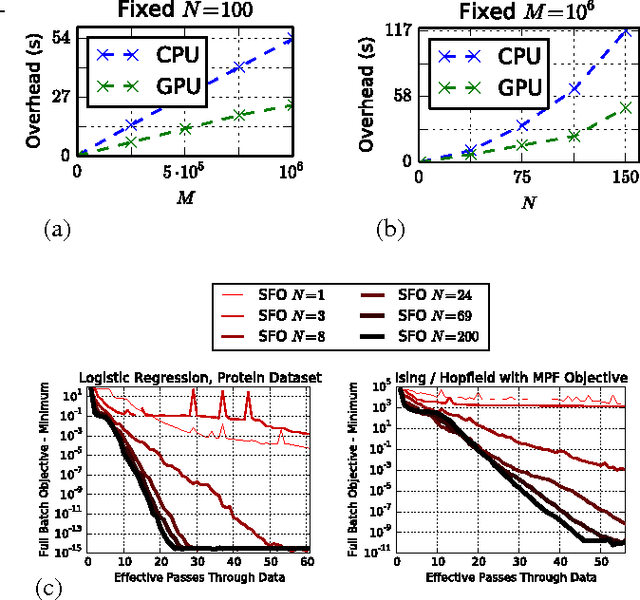
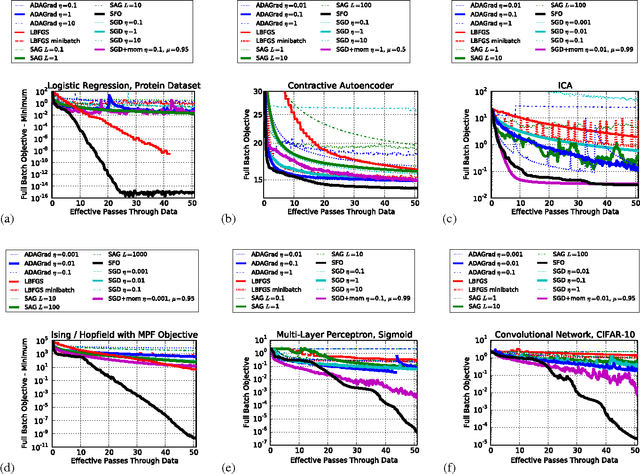
We present an algorithm for minimizing a sum of functions that combines the computational efficiency of stochastic gradient descent (SGD) with the second order curvature information leveraged by quasi-Newton methods. We unify these disparate approaches by maintaining an independent Hessian approximation for each contributing function in the sum. We maintain computational tractability and limit memory requirements even for high dimensional optimization problems by storing and manipulating these quadratic approximations in a shared, time evolving, low dimensional subspace. Each update step requires only a single contributing function or minibatch evaluation (as in SGD), and each step is scaled using an approximate inverse Hessian and little to no adjustment of hyperparameters is required (as is typical for quasi-Newton methods). This algorithm contrasts with earlier stochastic second order techniques that treat the Hessian of each contributing function as a noisy approximation to the full Hessian, rather than as a target for direct estimation. We experimentally demonstrate improved convergence on seven diverse optimization problems. The algorithm is released as open source Python and MATLAB packages.
Analyzing noise in autoencoders and deep networks
Jun 06, 2014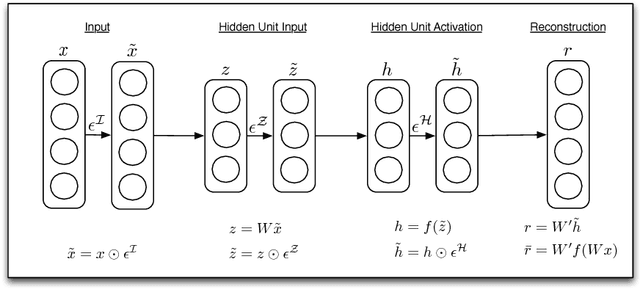

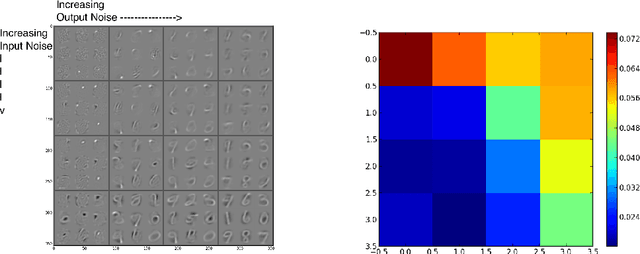

Autoencoders have emerged as a useful framework for unsupervised learning of internal representations, and a wide variety of apparently conceptually disparate regularization techniques have been proposed to generate useful features. Here we extend existing denoising autoencoders to additionally inject noise before the nonlinearity, and at the hidden unit activations. We show that a wide variety of previous methods, including denoising, contractive, and sparse autoencoders, as well as dropout can be interpreted using this framework. This noise injection framework reaps practical benefits by providing a unified strategy to develop new internal representations by designing the nature of the injected noise. We show that noisy autoencoders outperform denoising autoencoders at the very task of denoising, and are competitive with other single-layer techniques on MNIST, and CIFAR-10. We also show that types of noise other than dropout improve performance in a deep network through sparsifying, decorrelating, and spreading information across representations.
Efficient Methods for Unsupervised Learning of Probabilistic Models
May 19, 2012


In this thesis I develop a variety of techniques to train, evaluate, and sample from intractable and high dimensional probabilistic models. Abstract exceeds arXiv space limitations -- see PDF.
Hamiltonian Monte Carlo with Reduced Momentum Flips
May 09, 2012

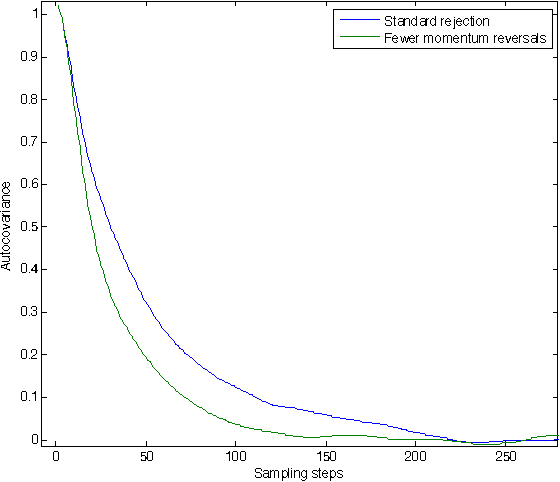
Hamiltonian Monte Carlo (or hybrid Monte Carlo) with partial momentum refreshment explores the state space more slowly than it otherwise would due to the momentum reversals which occur on proposal rejection. These cause trajectories to double back on themselves, leading to random walk behavior on timescales longer than the typical rejection time, and leading to slower mixing. I present a technique by which the number of momentum reversals can be reduced. This is accomplished by maintaining the net exchange of probability between states with opposite momenta, but reducing the rate of exchange in both directions such that it is 0 in one direction. An experiment illustrates these reduced momentum flips accelerating mixing for a particular distribution.
Hamiltonian Annealed Importance Sampling for partition function estimation
May 09, 2012
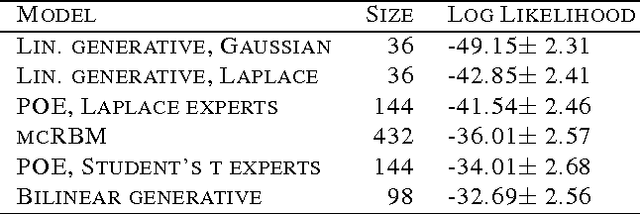


We introduce an extension to annealed importance sampling that uses Hamiltonian dynamics to rapidly estimate normalization constants. We demonstrate this method by computing log likelihoods in directed and undirected probabilistic image models. We compare the performance of linear generative models with both Gaussian and Laplace priors, product of experts models with Laplace and Student's t experts, the mc-RBM, and a bilinear generative model. We provide code to compare additional models.