 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput Switched Affine Networks: An RNN Architecture Designed for Interpretability
Jun 12, 2017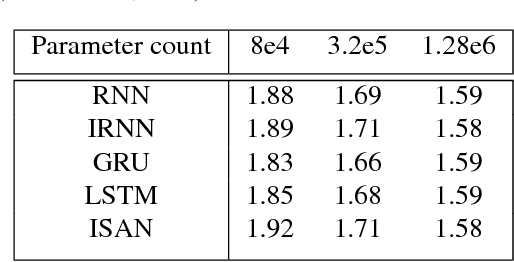
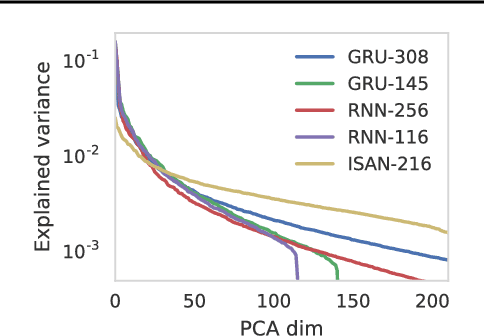
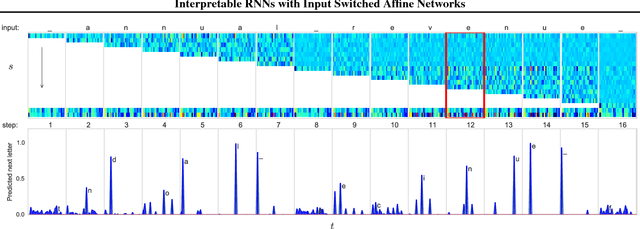
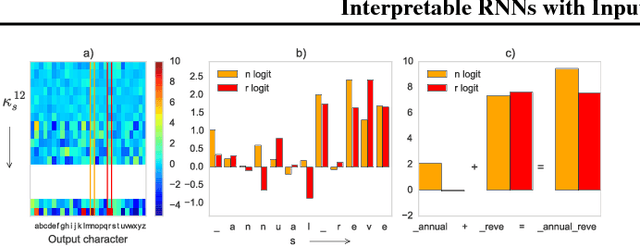
There exist many problem domains where the interpretability of neural network models is essential for deployment. Here we introduce a recurrent architecture composed of input-switched affine transformations - in other words an RNN without any explicit nonlinearities, but with input-dependent recurrent weights. This simple form allows the RNN to be analyzed via straightforward linear methods: we can exactly characterize the linear contribution of each input to the model predictions; we can use a change-of-basis to disentangle input, output, and computational hidden unit subspaces; we can fully reverse-engineer the architecture's solution to a simple task. Despite this ease of interpretation, the input switched affine network achieves reasonable performance on a text modeling tasks, and allows greater computational efficiency than networks with standard nonlinearities.
An Unsupervised Algorithm For Learning Lie Group Transformations
Jun 07, 2017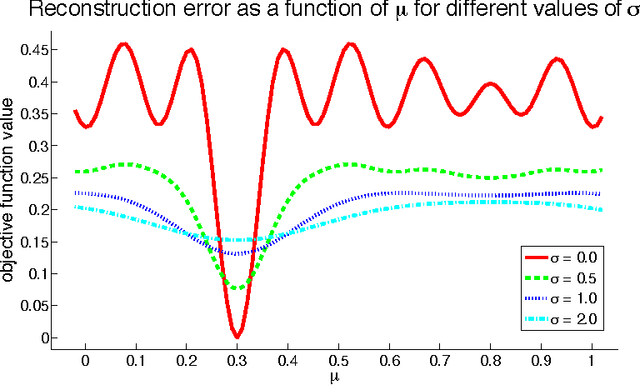
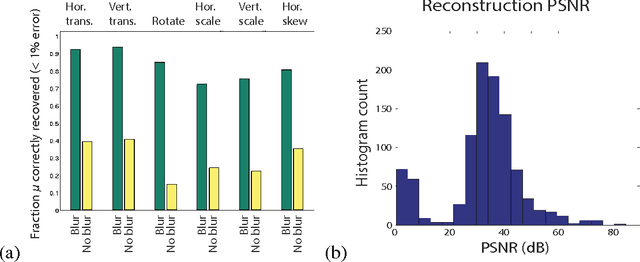


We present several theoretical contributions which allow Lie groups to be fit to high dimensional datasets. Transformation operators are represented in their eigen-basis, reducing the computational complexity of parameter estimation to that of training a linear transformation model. A transformation specific "blurring" operator is introduced that allows inference to escape local minima via a smoothing of the transformation space. A penalty on traversed manifold distance is added which encourages the discovery of sparse, minimal distance, transformations between states. Both learning and inference are demonstrated using these methods for the full set of affine transformations on natural image patches. Transformation operators are then trained on natural video sequences. It is shown that the learned video transformations provide a better description of inter-frame differences than the standard motion model based on rigid translation.
Unrolled Generative Adversarial Networks
May 12, 2017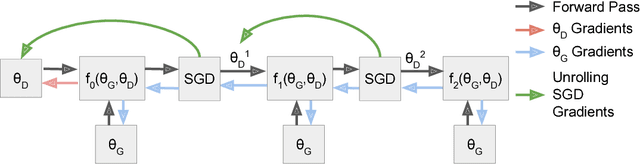

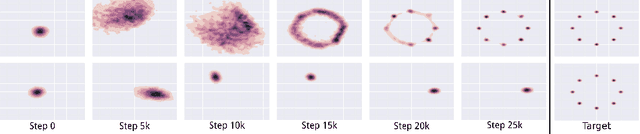

We introduce a method to stabilize Generative Adversarial Networks (GANs) by defining the generator objective with respect to an unrolled optimization of the discriminator. This allows training to be adjusted between using the optimal discriminator in the generator's objective, which is ideal but infeasible in practice, and using the current value of the discriminator, which is often unstable and leads to poor solutions. We show how this technique solves the common problem of mode collapse, stabilizes training of GANs with complex recurrent generators, and increases diversity and coverage of the data distribution by the generator.
Deep Information Propagation
Apr 04, 2017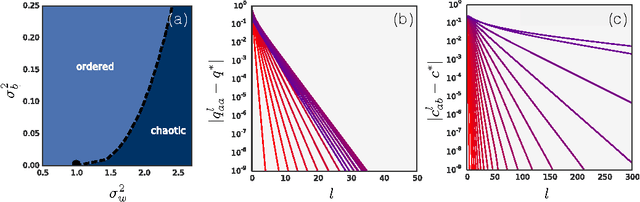
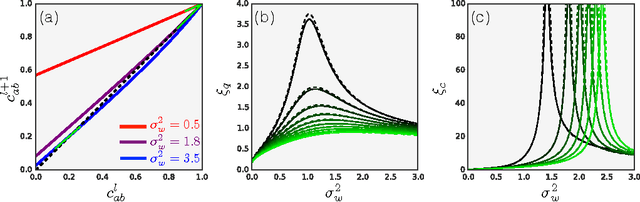
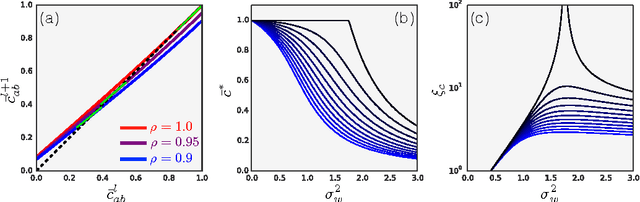
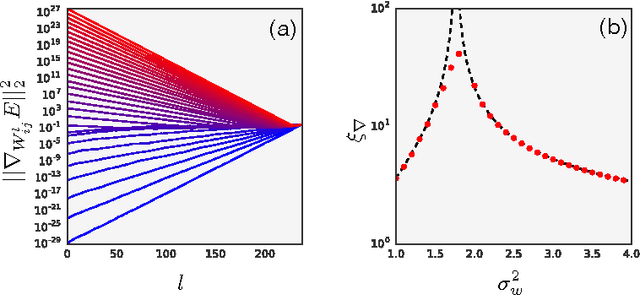
We study the behavior of untrained neural networks whose weights and biases are randomly distributed using mean field theory. We show the existence of depth scales that naturally limit the maximum depth of signal propagation through these random networks. Our main practical result is to show that random networks may be trained precisely when information can travel through them. Thus, the depth scales that we identify provide bounds on how deep a network may be trained for a specific choice of hyperparameters. As a corollary to this, we argue that in networks at the edge of chaos, one of these depth scales diverges. Thus arbitrarily deep networks may be trained only sufficiently close to criticality. We show that the presence of dropout destroys the order-to-chaos critical point and therefore strongly limits the maximum trainable depth for random networks. Finally, we develop a mean field theory for backpropagation and we show that the ordered and chaotic phases correspond to regions of vanishing and exploding gradient respectively.
Capacity and Trainability in Recurrent Neural Networks
Mar 03, 2017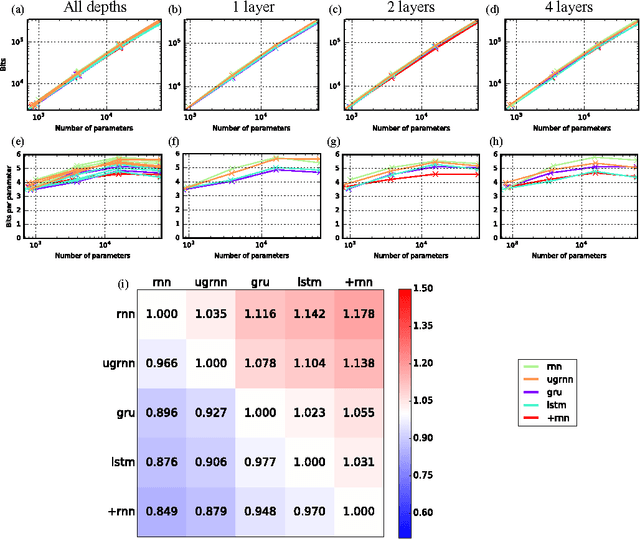
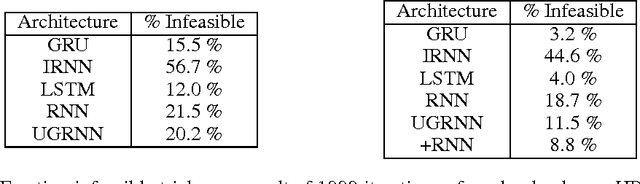
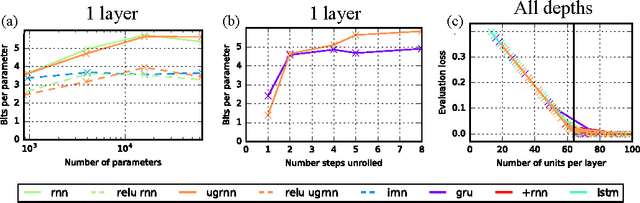
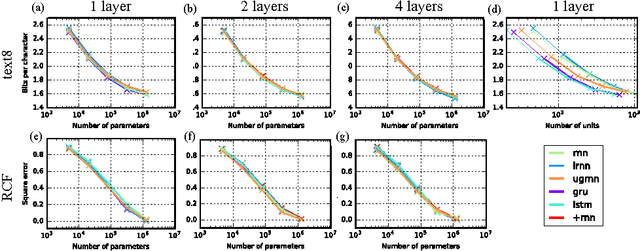
Two potential bottlenecks on the expressiveness of recurrent neural networks (RNNs) are their ability to store information about the task in their parameters, and to store information about the input history in their units. We show experimentally that all common RNN architectures achieve nearly the same per-task and per-unit capacity bounds with careful training, for a variety of tasks and stacking depths. They can store an amount of task information which is linear in the number of parameters, and is approximately 5 bits per parameter. They can additionally store approximately one real number from their input history per hidden unit. We further find that for several tasks it is the per-task parameter capacity bound that determines performance. These results suggest that many previous results comparing RNN architectures are driven primarily by differences in training effectiveness, rather than differences in capacity. Supporting this observation, we compare training difficulty for several architectures, and show that vanilla RNNs are far more difficult to train, yet have slightly higher capacity. Finally, we propose two novel RNN architectures, one of which is easier to train than the LSTM or GRU for deeply stacked architectures.
Density estimation using Real NVP
Feb 27, 2017
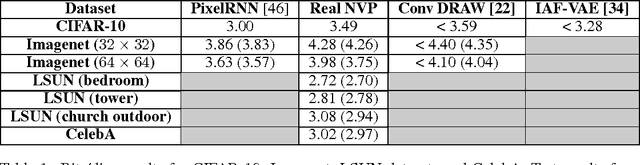


Unsupervised learning of probabilistic models is a central yet challenging problem in machine learning. Specifically, designing models with tractable learning, sampling, inference and evaluation is crucial in solving this task. We extend the space of such models using real-valued non-volume preserving (real NVP) transformations, a set of powerful invertible and learnable transformations, resulting in an unsupervised learning algorithm with exact log-likelihood computation, exact sampling, exact inference of latent variables, and an interpretable latent space. We demonstrate its ability to model natural images on four datasets through sampling, log-likelihood evaluation and latent variable manipulations.
Improved generator objectives for GANs
Dec 08, 2016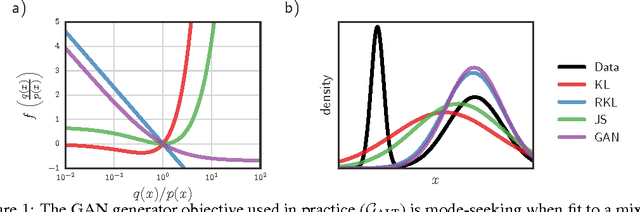
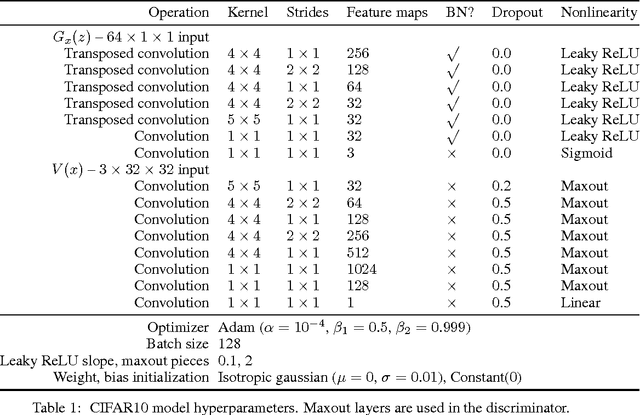

We present a framework to understand GAN training as alternating density ratio estimation and approximate divergence minimization. This provides an interpretation for the mismatched GAN generator and discriminator objectives often used in practice, and explains the problem of poor sample diversity. We also derive a family of generator objectives that target arbitrary $f$-divergences without minimizing a lower bound, and use them to train generative image models that target either improved sample quality or greater sample diversity.
Survey of Expressivity in Deep Neural Networks
Nov 24, 2016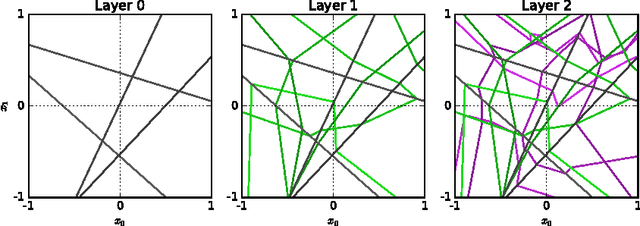

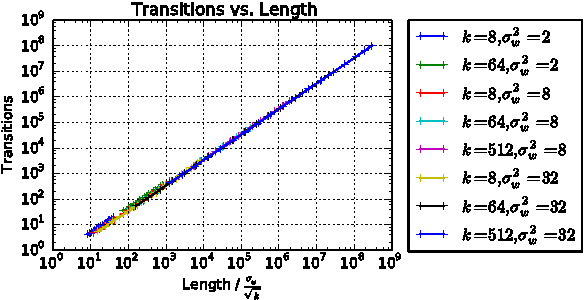
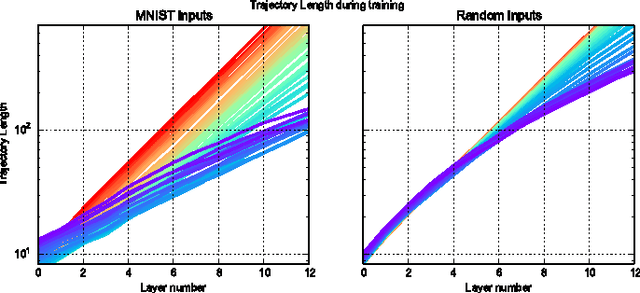
We survey results on neural network expressivity described in "On the Expressive Power of Deep Neural Networks". The paper motivates and develops three natural measures of expressiveness, which all display an exponential dependence on the depth of the network. In fact, all of these measures are related to a fourth quantity, trajectory length. This quantity grows exponentially in the depth of the network, and is responsible for the depth sensitivity observed. These results translate to consequences for networks during and after training. They suggest that parameters earlier in a network have greater influence on its expressive power -- in particular, given a layer, its influence on expressivity is determined by the remaining depth of the network after that layer. This is verified with experiments on MNIST and CIFAR-10. We also explore the effect of training on the input-output map, and find that it trades off between the stability and expressivity.
Note on Equivalence Between Recurrent Neural Network Time Series Models and Variational Bayesian Models
Jun 18, 2016We observe that the standard log likelihood training objective for a Recurrent Neural Network (RNN) model of time series data is equivalent to a variational Bayesian training objective, given the proper choice of generative and inference models. This perspective may motivate extensions to both RNNs and variational Bayesian models. We propose one such extension, where multiple particles are used for the hidden state of an RNN, allowing a natural representation of uncertainty or multimodality.
Exponential expressivity in deep neural networks through transient chaos
Jun 17, 2016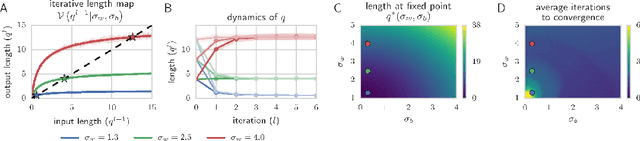
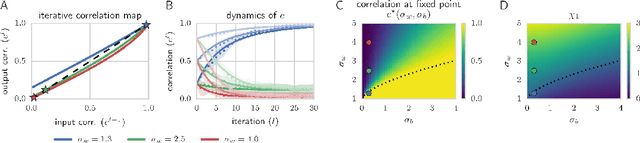
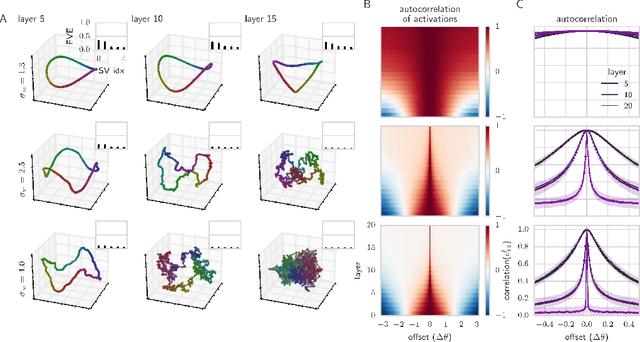
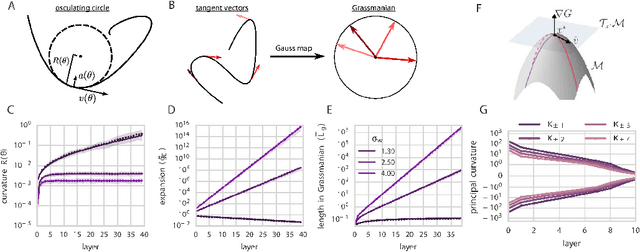
We combine Riemannian geometry with the mean field theory of high dimensional chaos to study the nature of signal propagation in generic, deep neural networks with random weights. Our results reveal an order-to-chaos expressivity phase transition, with networks in the chaotic phase computing nonlinear functions whose global curvature grows exponentially with depth but not width. We prove this generic class of deep random functions cannot be efficiently computed by any shallow network, going beyond prior work restricted to the analysis of single functions. Moreover, we formalize and quantitatively demonstrate the long conjectured idea that deep networks can disentangle highly curved manifolds in input space into flat manifolds in hidden space. Our theoretical analysis of the expressive power of deep networks broadly applies to arbitrary nonlinearities, and provides a quantitative underpinning for previously abstract notions about the geometry of deep functions.