 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning using Guided Observability
Apr 22, 2021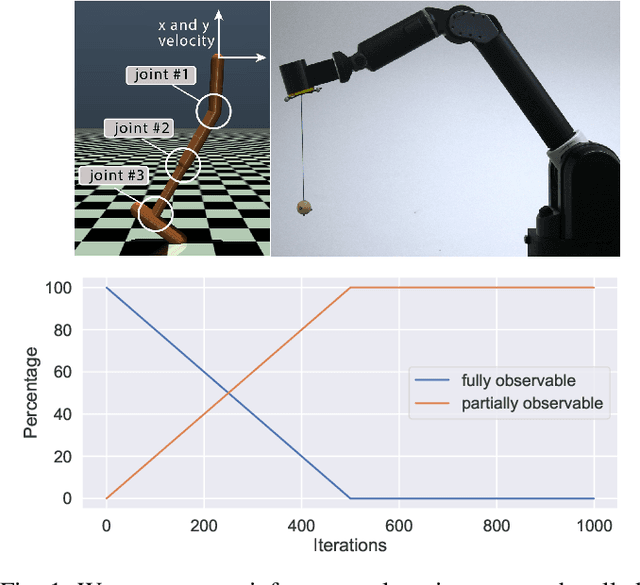

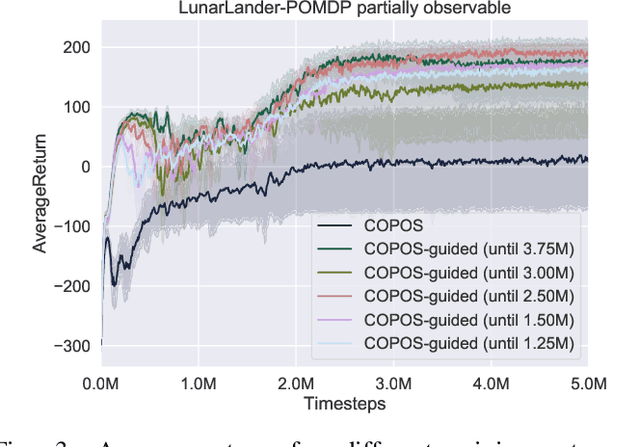
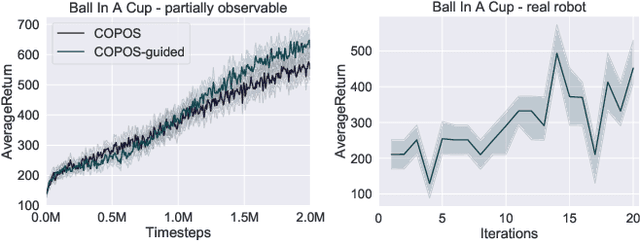
Due to recent breakthroughs, reinforcement learning (RL) has demonstrated impressive performance in challenging sequential decision-making problems. However, an open question is how to make RL cope with partial observability which is prevalent in many real-world problems. Contrary to contemporary RL approaches, which focus mostly on improved memory representations or strong assumptions about the type of partial observability, we propose a simple but efficient approach that can be applied together with a wide variety of RL methods. Our main insight is that smoothly transitioning from full observability to partial observability during the training process yields a high performance policy. The approach, called partially observable guided reinforcement learning (PO-GRL), allows to utilize full state information during policy optimization without compromising the optimality of the final policy. A comprehensive evaluation in discrete partially observableMarkov decision process (POMDP) benchmark problems and continuous partially observable MuJoCo and OpenAI gym tasks shows that PO-GRL improves performance. Finally, we demonstrate PO-GRL in the ball-in-the-cup task on a real Barrett WAM robot under partial observability.
Distributionally Robust Trajectory Optimization Under Uncertain Dynamics via Relative-Entropy Trust Regions
Mar 29, 2021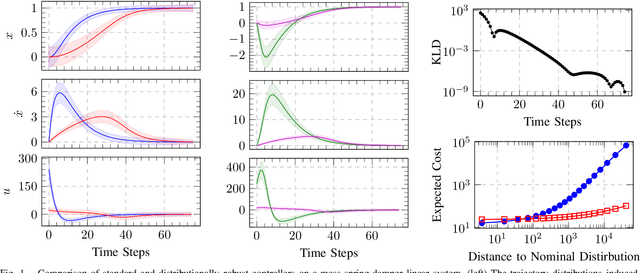
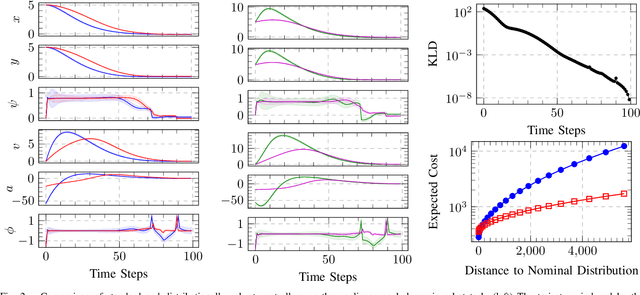
Trajectory optimization and model predictive control are essential techniques underpinning advanced robotic applications, ranging from autonomous driving to full-body humanoid control. State-of-the-art algorithms have focused on data-driven approaches that infer the system dynamics online and incorporate posterior uncertainty during planning and control. Despite their success, such approaches are still susceptible to catastrophic errors that may arise due to statistical learning biases, unmodeled disturbances or even directed adversarial attacks. In this paper, we tackle the problem of dynamics mismatch and propose a distributionally robust optimal control formulation that alternates between two relative-entropy trust region optimization problems. Our method finds the worst-case maximum-entropy Gaussian posterior over the dynamics parameters and the corresponding robust optimal policy. We show that our approach admits a closed-form backward-pass for a certain class of systems and demonstrate the resulting robustness on linear and nonlinear numerical examples.
SKID RAW: Skill Discovery from Raw Trajectories
Mar 26, 2021
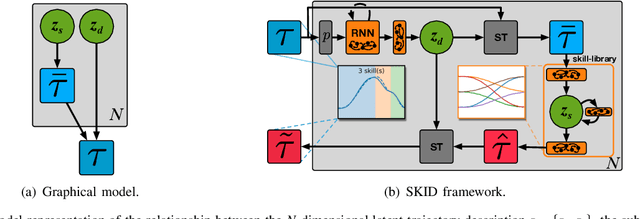
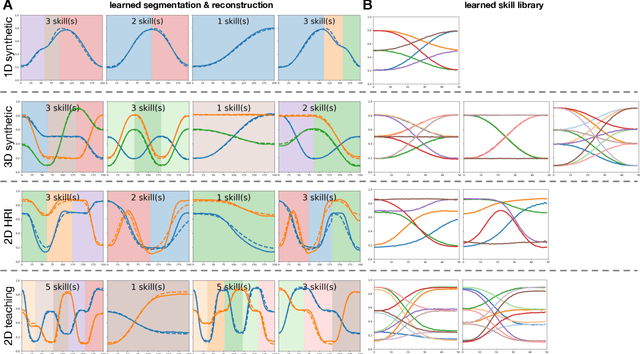
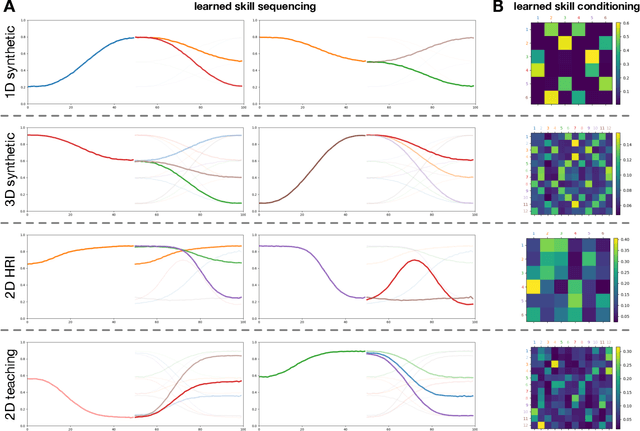
Integrating robots in complex everyday environments requires a multitude of problems to be solved. One crucial feature among those is to equip robots with a mechanism for teaching them a new task in an easy and natural way. When teaching tasks that involve sequences of different skills, with varying order and number of these skills, it is desirable to only demonstrate full task executions instead of all individual skills. For this purpose, we propose a novel approach that simultaneously learns to segment trajectories into reoccurring patterns and the skills to reconstruct these patterns from unlabelled demonstrations without further supervision. Moreover, the approach learns a skill conditioning that can be used to understand possible sequences of skills, a practical mechanism to be used in, for example, human-robot-interactions for a more intelligent and adaptive robot behaviour. The Bayesian and variational inference based approach is evaluated on synthetic and real human demonstrations with varying complexities and dimensionality, showing the successful learning of segmentations and skill libraries from unlabelled data.
Model Predictive Actor-Critic: Accelerating Robot Skill Acquisition with Deep Reinforcement Learning
Mar 25, 2021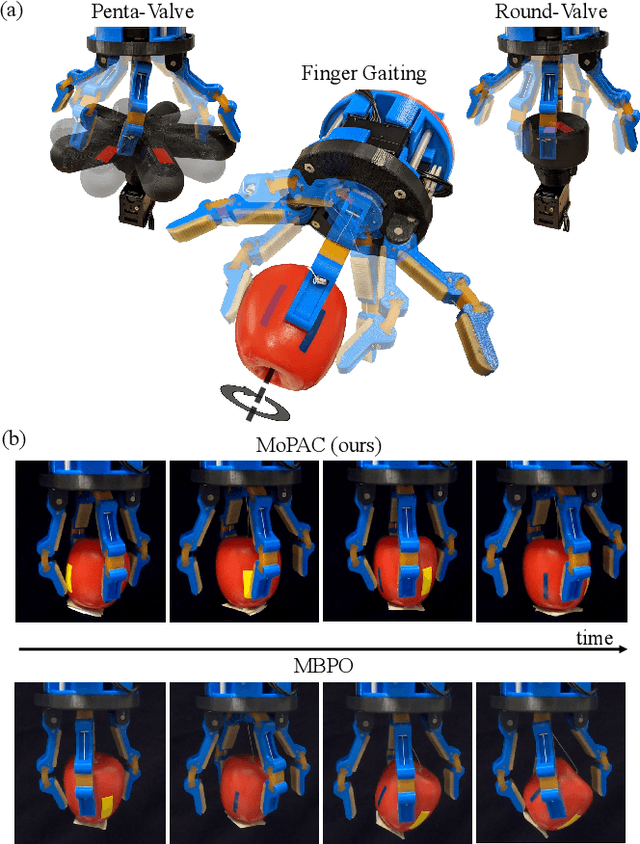
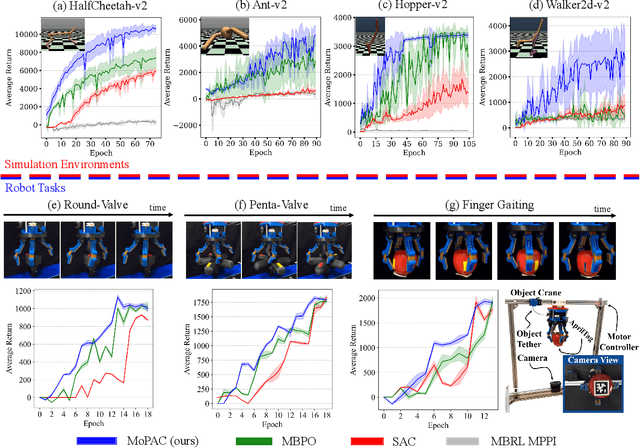
Substantial advancements to model-based reinforcement learning algorithms have been impeded by the model-bias induced by the collected data, which generally hurts performance. Meanwhile, their inherent sample efficiency warrants utility for most robot applications, limiting potential damage to the robot and its environment during training. Inspired by information theoretic model predictive control and advances in deep reinforcement learning, we introduce Model Predictive Actor-Critic (MoPAC), a hybrid model-based/model-free method that combines model predictive rollouts with policy optimization as to mitigate model bias. MoPAC leverages optimal trajectories to guide policy learning, but explores via its model-free method, allowing the algorithm to learn more expressive dynamics models. This combination guarantees optimal skill learning up to an approximation error and reduces necessary physical interaction with the environment, making it suitable for real-robot training. We provide extensive results showcasing how our proposed method generally outperforms current state-of-the-art and conclude by evaluating MoPAC for learning on a physical robotic hand performing valve rotation and finger gaiting--a task that requires grasping, manipulation, and then regrasping of an object.
Advancing Trajectory Optimization with Approximate Inference: Exploration, Covariance Control and Adaptive Risk
Mar 10, 2021
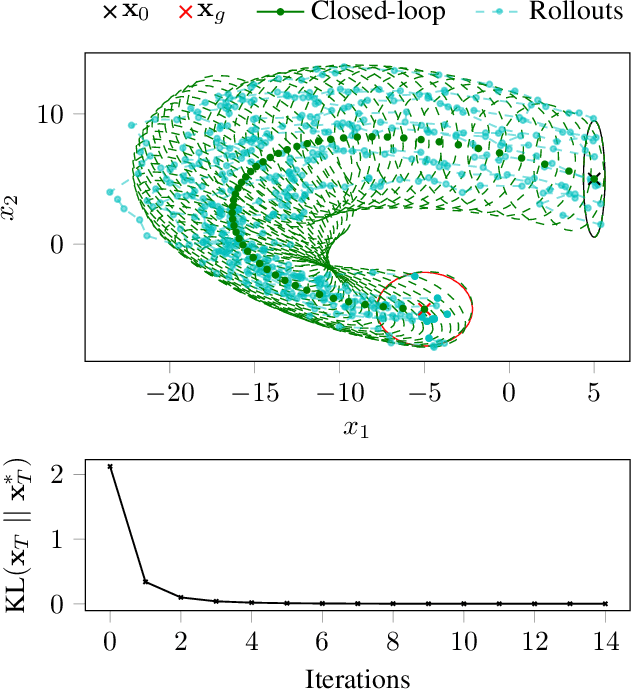
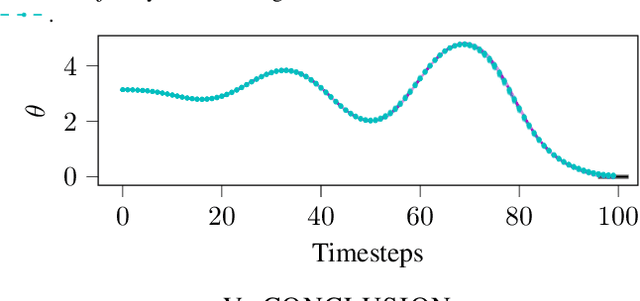

Discrete-time stochastic optimal control remains a challenging problem for general, nonlinear systems under significant uncertainty, with practical solvers typically relying on the certainty equivalence assumption, replanning and/or extensive regularization. Control as inference is an approach that frames stochastic control as an equivalent inference problem, and has demonstrated desirable qualities over existing methods, namely in exploration and regularization. We look specifically at the input inference for control (i2c) algorithm, and derive three key characteristics that enable advanced trajectory optimization: An `expert' linear Gaussian controller that combines the benefits of open-loop optima and closed-loop variance reduction when optimizing for nonlinear systems, inherent adaptive risk sensitivity from the inference formulation, and covariance control functionality with only a minor algorithmic adjustment.
Extended Task and Motion Planning of Long-horizon Robot Manipulation
Mar 09, 2021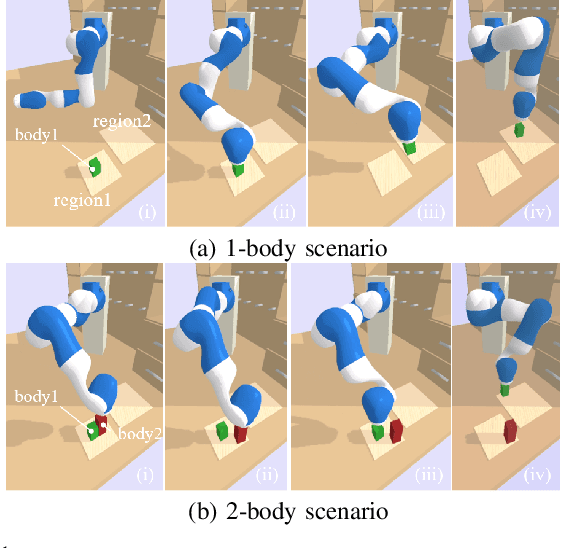
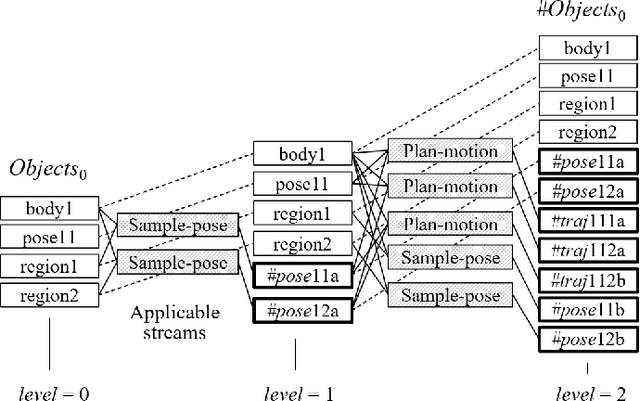
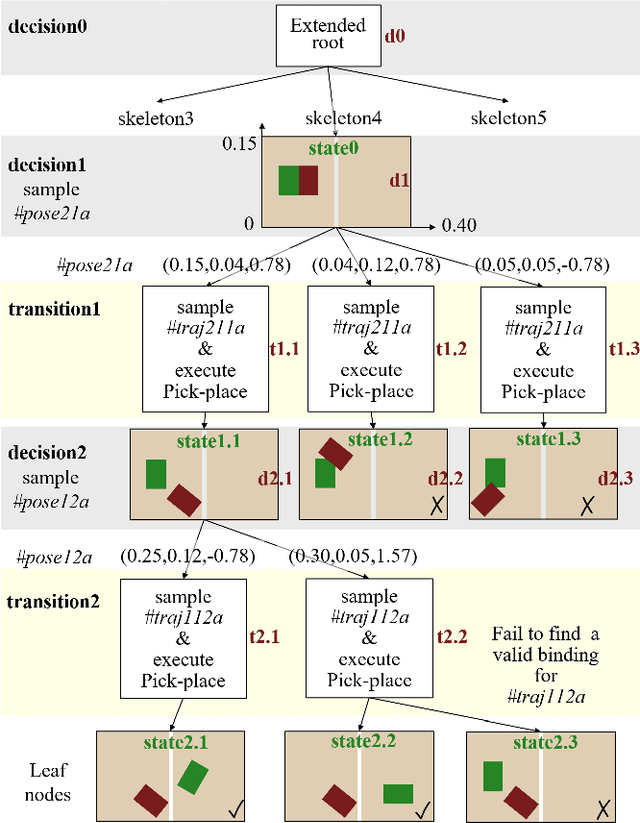

Task and Motion Planning (TAMP) requires the integration of symbolic reasoning with metric motion planning that accounts for the robot's actions' geometric feasibility. This hierarchical structure inevitably prevents the symbolic planners from accessing the environment's low-level geometric description, vital to the problem's solution. Most TAMP approaches fail to provide feasible solutions when there is missing knowledge about the environment at the symbolic level. The incapability of devising alternative high-level plans leads existing planners to a dead end. We propose a novel approach for decision-making on extended decision spaces over plan skeletons and action parameters. We integrate top-k planning for constructing an explicit skeleton space, where a skeleton planner generates a variety of candidate skeleton plans. Moreover, we effectively combine this skeleton space with the resultant motion parameter spaces into a single extended decision space. Accordingly, we use Monte-Carlo Tree Search (MCTS) to ensure an exploration-exploitation balance at each decision node and optimize globally to produce minimum-cost solutions. The proposed seamless combination of symbolic top-k planning with streams, with the proved optimality of MCTS, leads to a powerful planning algorithm that can handle the combinatorial complexity of long-horizon manipulation tasks. We empirically evaluate our proposed algorithm in challenging manipulation tasks with different domains that require multi-stage decisions and show how our method can overcome dead-ends through its effective alternate plans compared to its most competitive baseline method.
Learning Human-like Hand Reaching for Human-Robot Handshaking
Feb 28, 2021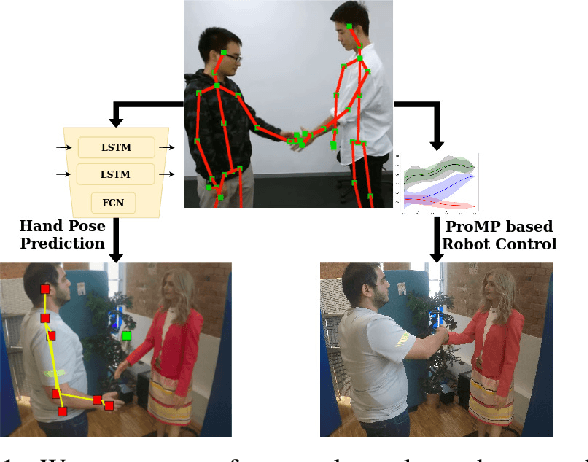
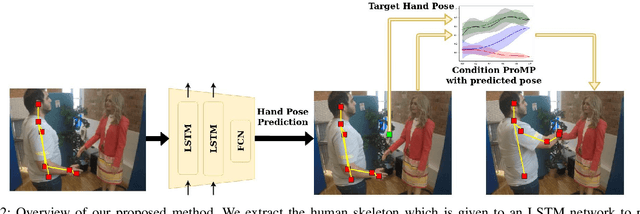


One of the first and foremost non-verbal interactions that humans perform is a handshake. It has an impact on first impressions as touch can convey complex emotions. This makes handshaking an important skill for the repertoire of a social robot. In this paper, we present a novel framework for learning human-robot handshaking behaviours for humanoid robots solely using third-person human-human interaction data. This is especially useful for non-backdrivable robots that cannot be taught by demonstrations via kinesthetic teaching. Our approach can be easily executed on different humanoid robots. This removes the need for re-training, which is especially tedious when training with human-interaction partners. We show this by applying the learnt behaviours on two different humanoid robots with similar degrees of freedom but different shapes and control limits.
A Probabilistic Interpretation of Self-Paced Learning with Applications to Reinforcement Learning
Feb 25, 2021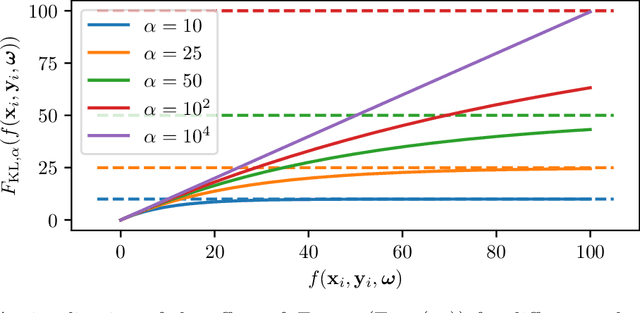
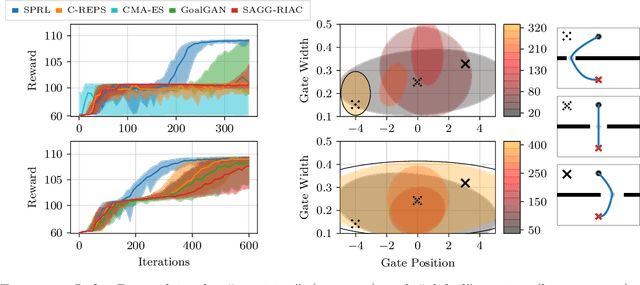
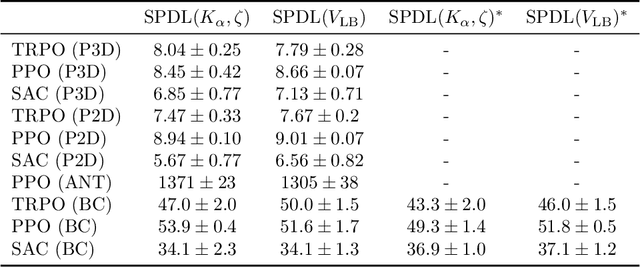
Across machine learning, the use of curricula has shown strong empirical potential to improve learning from data by avoiding local optima of training objectives. For reinforcement learning (RL), curricula are especially interesting, as the underlying optimization has a strong tendency to get stuck in local optima due to the exploration-exploitation trade-off. Recently, a number of approaches for an automatic generation of curricula for RL have been shown to increase performance while requiring less expert knowledge compared to manually designed curricula. However, these approaches are seldomly investigated from a theoretical perspective, preventing a deeper understanding of their mechanics. In this paper, we present an approach for automated curriculum generation in RL with a clear theoretical underpinning. More precisely, we formalize the well-known self-paced learning paradigm as inducing a distribution over training tasks, which trades off between task complexity and the objective to match a desired task distribution. Experiments show that training on this induced distribution helps to avoid poor local optima across RL algorithms in different tasks with uninformative rewards and challenging exploration requirements.
Human-Robot Handshaking: A Review
Feb 14, 2021
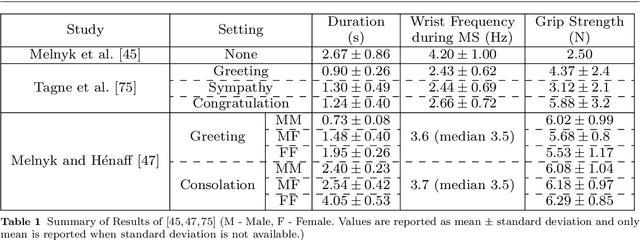
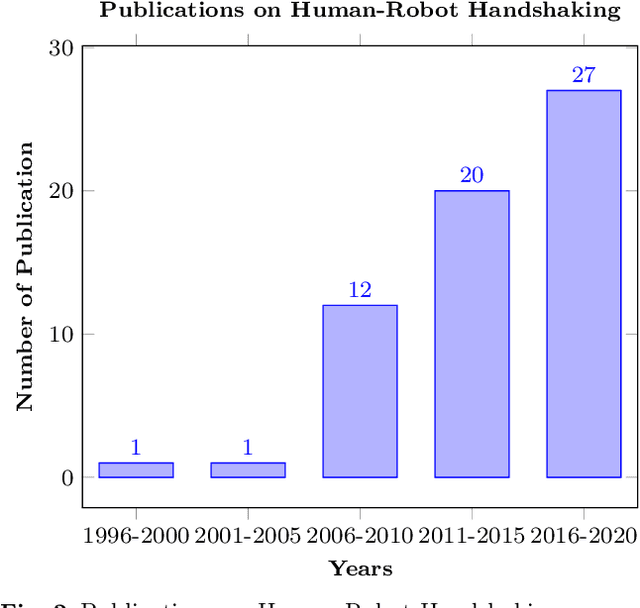
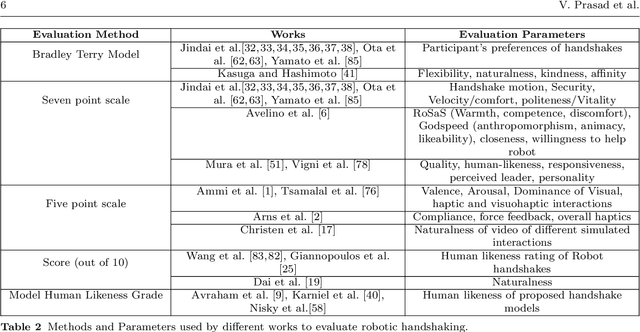
For some years now, the use of social, anthropomorphic robots in various situations has been on the rise. These are robots developed to interact with humans and are equipped with corresponding extremities. They already support human users in various industries, such as retail, gastronomy, hotels, education and healthcare. During such Human-Robot Interaction (HRI) scenarios, physical touch plays a central role in the various applications of social robots as interactive non-verbal behaviour is a key factor in making the interaction more natural. Shaking hands is a simple, natural interaction used commonly in many social contexts and is seen as a symbol of greeting, farewell and congratulations. In this paper, we take a look at the existing state of Human-Robot Handshaking research, categorise the works based on their focus areas, draw out the major findings of these areas while analysing their pitfalls. We mainly see that some form of synchronisation exists during the different phases of the interaction. In addition to this, we also find that additional factors like gaze, voice facial expressions etc. can affect the perception of a robotic handshake and that internal factors like personality and mood can affect the way in which handshaking behaviours are executed by humans. Based on the findings and insights, we finally discuss possible ways forward for research on such physically interactive behaviours.
Structured Policy Representation: Imposing Stability in arbitrarily conditioned dynamic systems
Dec 11, 2020
We present a new family of deep neural network-based dynamic systems. The presented dynamics are globally stable and can be conditioned with an arbitrary context state. We show how these dynamics can be used as structured robot policies. Global stability is one of the most important and straightforward inductive biases as it allows us to impose reasonable behaviors outside the region of the demonstrations.