 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Vectors: a Task Arithmetic View on Backdoor Attacks and Defenses
Oct 09, 2025Model merging (MM) recently emerged as an effective method for combining large deep learning models. However, it poses significant security risks. Recent research shows that it is highly susceptible to backdoor attacks, which introduce a hidden trigger into a single fine-tuned model instance that allows the adversary to control the output of the final merged model at inference time. In this work, we propose a simple framework for understanding backdoor attacks by treating the attack itself as a task vector. $Backdoor\ Vector\ (BV)$ is calculated as the difference between the weights of a fine-tuned backdoored model and fine-tuned clean model. BVs reveal new insights into attacks understanding and a more effective framework to measure their similarity and transferability. Furthermore, we propose a novel method that enhances backdoor resilience through merging dubbed $Sparse\ Backdoor\ Vector\ (SBV)$ that combines multiple attacks into a single one. We identify the core vulnerability behind backdoor threats in MM: $inherent\ triggers$ that exploit adversarial weaknesses in the base model. To counter this, we propose $Injection\ BV\ Subtraction\ (IBVS)$ - an assumption-free defense against backdoors in MM. Our results show that SBVs surpass prior attacks and is the first method to leverage merging to improve backdoor effectiveness. At the same time, IBVS provides a lightweight, general defense that remains effective even when the backdoor threat is entirely unknown.
Bucks for Buckets (B4B): Active Defenses Against Stealing Encoders
Oct 12, 2023Machine Learning as a Service (MLaaS) APIs provide ready-to-use and high-utility encoders that generate vector representations for given inputs. Since these encoders are very costly to train, they become lucrative targets for model stealing attacks during which an adversary leverages query access to the API to replicate the encoder locally at a fraction of the original training costs. We propose Bucks for Buckets (B4B), the first active defense that prevents stealing while the attack is happening without degrading representation quality for legitimate API users. Our defense relies on the observation that the representations returned to adversaries who try to steal the encoder's functionality cover a significantly larger fraction of the embedding space than representations of legitimate users who utilize the encoder to solve a particular downstream task.vB4B leverages this to adaptively adjust the utility of the returned representations according to a user's coverage of the embedding space. To prevent adaptive adversaries from eluding our defense by simply creating multiple user accounts (sybils), B4B also individually transforms each user's representations. This prevents the adversary from directly aggregating representations over multiple accounts to create their stolen encoder copy. Our active defense opens a new path towards securely sharing and democratizing encoders over public APIs.
Towards More Realistic Membership Inference Attacks on Large Diffusion Models
Jun 22, 2023



Generative diffusion models, including Stable Diffusion and Midjourney, can generate visually appealing, diverse, and high-resolution images for various applications. These models are trained on billions of internet-sourced images, raising significant concerns about the potential unauthorized use of copyright-protected images. In this paper, we examine whether it is possible to determine if a specific image was used in the training set, a problem known in the cybersecurity community and referred to as a membership inference attack. Our focus is on Stable Diffusion, and we address the challenge of designing a fair evaluation framework to answer this membership question. We propose a methodology to establish a fair evaluation setup and apply it to Stable Diffusion, enabling potential extensions to other generative models. Utilizing this evaluation setup, we execute membership attacks (both known and newly introduced). Our research reveals that previously proposed evaluation setups do not provide a full understanding of the effectiveness of membership inference attacks. We conclude that the membership inference attack remains a significant challenge for large diffusion models (often deployed as black-box systems), indicating that related privacy and copyright issues will persist in the foreseeable future.
Progressive Latent Replay for efficient Generative Rehearsal
Jul 05, 2022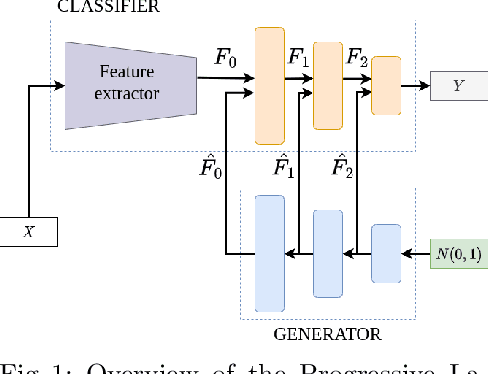
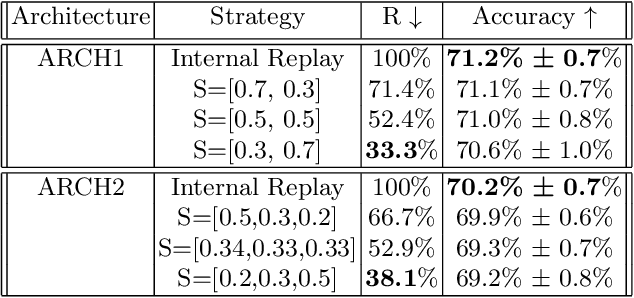
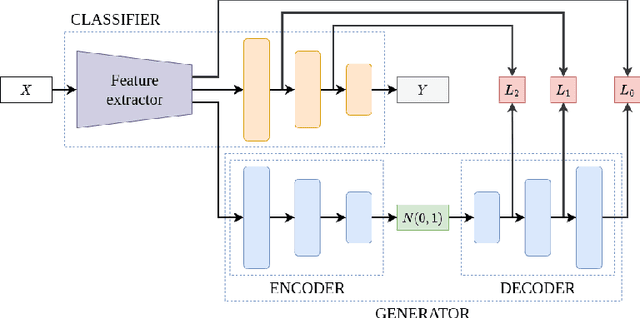
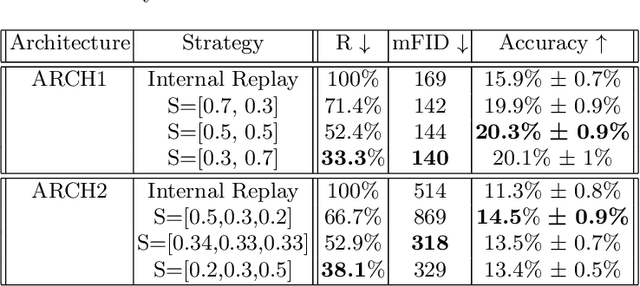
We introduce a new method for internal replay that modulates the frequency of rehearsal based on the depth of the network. While replay strategies mitigate the effects of catastrophic forgetting in neural networks, recent works on generative replay show that performing the rehearsal only on the deeper layers of the network improves the performance in continual learning. However, the generative approach introduces additional computational overhead, limiting its applications. Motivated by the observation that earlier layers of neural networks forget less abruptly, we propose to update network layers with varying frequency using intermediate-level features during replay. This reduces the computational burden by omitting computations for both deeper layers of the generator and earlier layers of the main model. We name our method Progressive Latent Replay and show that it outperforms Internal Replay while using significantly fewer resources.