 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Transformer Modifications Transfer Across Implementations and Applications?
Feb 23, 2021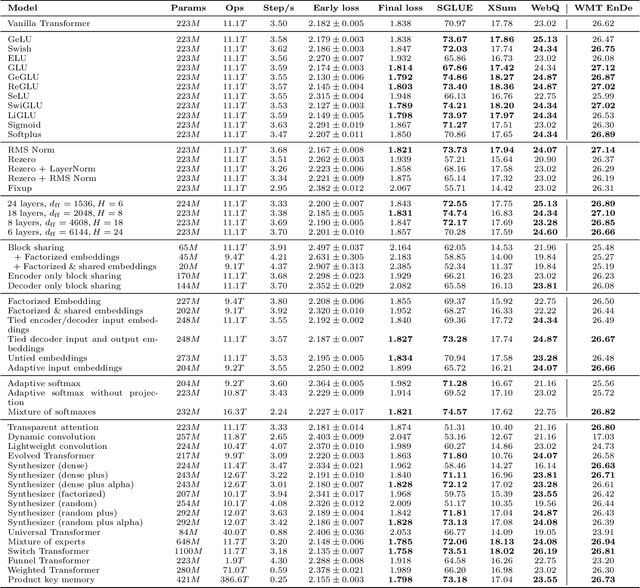
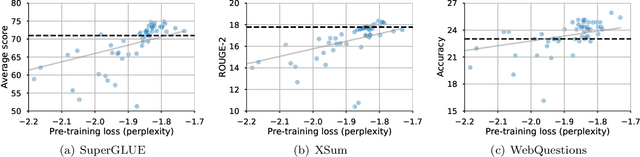
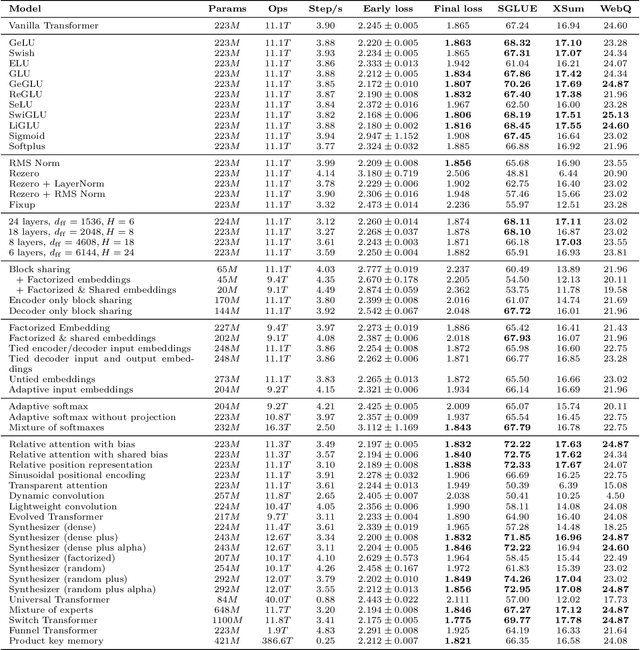
The research community has proposed copious modifications to the Transformer architecture since it was introduced over three years ago, relatively few of which have seen widespread adoption. In this paper, we comprehensively evaluate many of these modifications in a shared experimental setting that covers most of the common uses of the Transformer in natural language processing. Surprisingly, we find that most modifications do not meaningfully improve performance. Furthermore, most of the Transformer variants we found beneficial were either developed in the same codebase that we used or are relatively minor changes. We conjecture that performance improvements may strongly depend on implementation details and correspondingly make some recommendations for improving the generality of experimental results.
Scalable and accurate deep learning for electronic health records
May 11, 2018
Predictive modeling with electronic health record (EHR) data is anticipated to drive personalized medicine and improve healthcare quality. Constructing predictive statistical models typically requires extraction of curated predictor variables from normalized EHR data, a labor-intensive process that discards the vast majority of information in each patient's record. We propose a representation of patients' entire, raw EHR records based on the Fast Healthcare Interoperability Resources (FHIR) format. We demonstrate that deep learning methods using this representation are capable of accurately predicting multiple medical events from multiple centers without site-specific data harmonization. We validated our approach using de-identified EHR data from two U.S. academic medical centers with 216,221 adult patients hospitalized for at least 24 hours. In the sequential format we propose, this volume of EHR data unrolled into a total of 46,864,534,945 data points, including clinical notes. Deep learning models achieved high accuracy for tasks such as predicting in-hospital mortality (AUROC across sites 0.93-0.94), 30-day unplanned readmission (AUROC 0.75-0.76), prolonged length of stay (AUROC 0.85-0.86), and all of a patient's final discharge diagnoses (frequency-weighted AUROC 0.90). These models outperformed state-of-the-art traditional predictive models in all cases. We also present a case-study of a neural-network attribution system, which illustrates how clinicians can gain some transparency into the predictions. We believe that this approach can be used to create accurate and scalable predictions for a variety of clinical scenarios, complete with explanations that directly highlight evidence in the patient's chart.
* Published version from https://www.nature.com/articles/s41746-018-0029-1
Multi-task Prediction of Disease Onsets from Longitudinal Lab Tests
Sep 20, 2016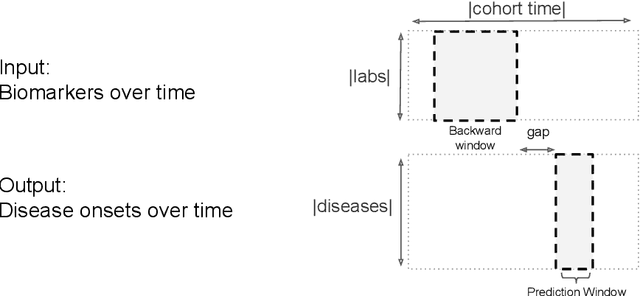
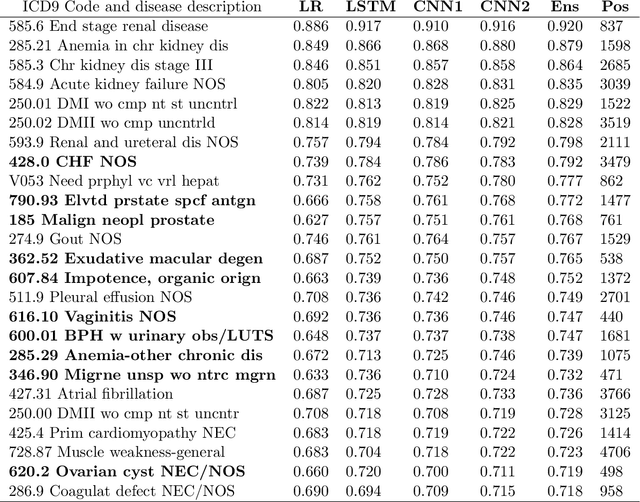
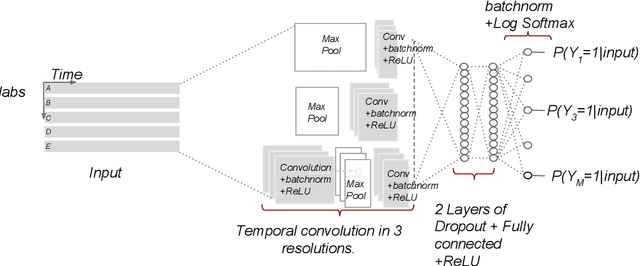
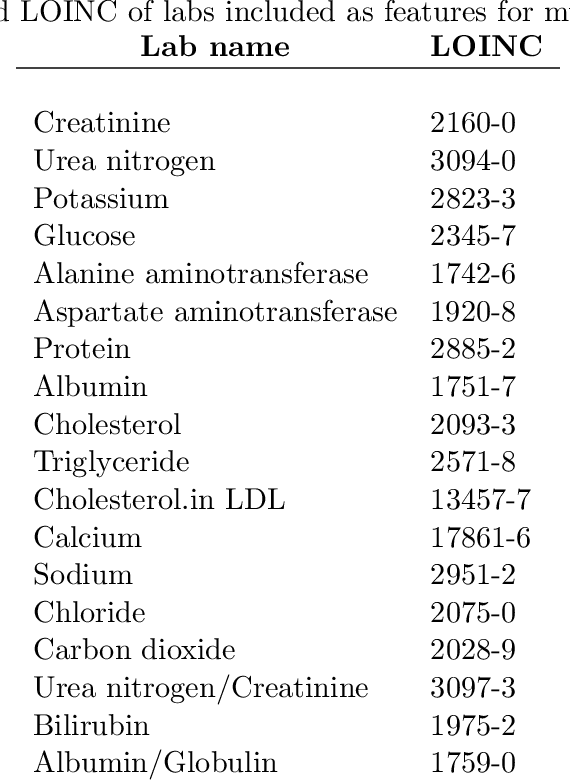
Disparate areas of machine learning have benefited from models that can take raw data with little preprocessing as input and learn rich representations of that raw data in order to perform well on a given prediction task. We evaluate this approach in healthcare by using longitudinal measurements of lab tests, one of the more raw signals of a patient's health state widely available in clinical data, to predict disease onsets. In particular, we train a Long Short-Term Memory (LSTM) recurrent neural network and two novel convolutional neural networks for multi-task prediction of disease onset for 133 conditions based on 18 common lab tests measured over time in a cohort of 298K patients derived from 8 years of administrative claims data. We compare the neural networks to a logistic regression with several hand-engineered, clinically relevant features. We find that the representation-based learning approaches significantly outperform this baseline. We believe that our work suggests a new avenue for patient risk stratification based solely on lab results.