 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrospective Sparse Attention for Efficient Long-Context Generation
Aug 12, 2025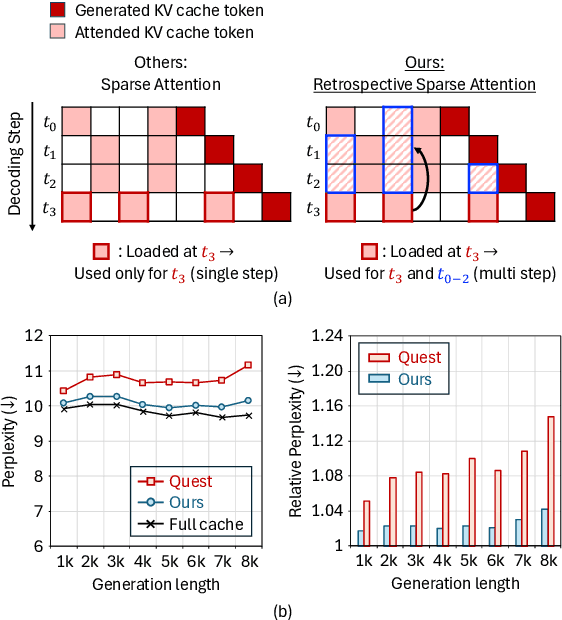
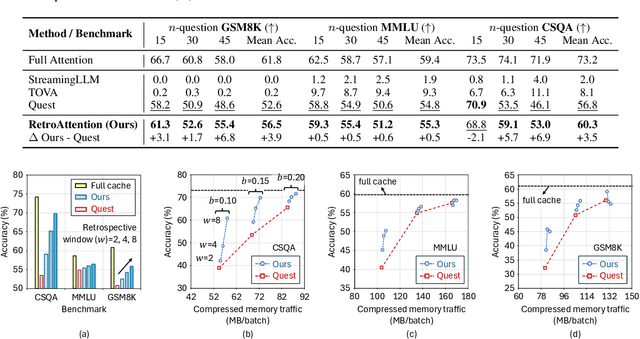
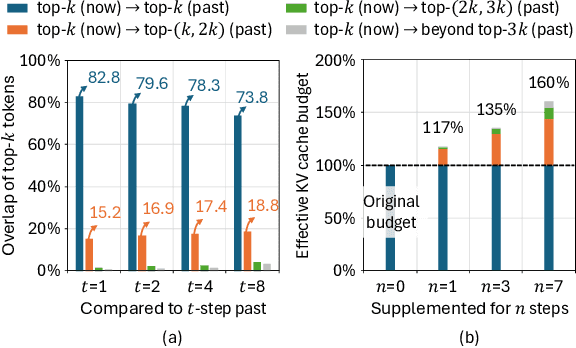
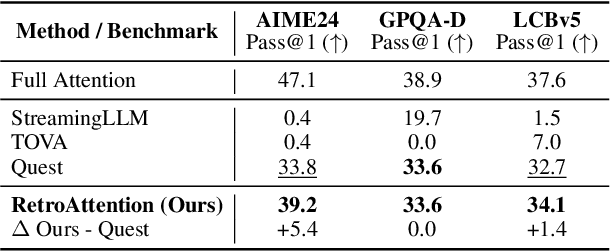
Large Language Models (LLMs) are increasingly deployed in long-context tasks such as reasoning, code generation, and multi-turn dialogue. However, inference over extended contexts is bottlenecked by the Key-Value (KV) cache, whose memory footprint grows linearly with sequence length and dominates latency at each decoding step. While recent KV cache compression methods identify and load important tokens, they focus predominantly on input contexts and fail to address the cumulative attention errors that arise during long decoding. In this paper, we introduce RetroAttention, a novel KV cache update technique that retrospectively revises past attention outputs using newly arrived KV entries from subsequent decoding steps. By maintaining a lightweight output cache, RetroAttention enables past queries to efficiently access more relevant context, while incurring minimal latency overhead. This breaks the fixed-attention-output paradigm and allows continual correction of prior approximations. Extensive experiments on long-generation benchmarks show that RetroAttention consistently outperforms state-of-the-art (SOTA) KV compression methods, increasing effective KV exposure by up to 1.6$\times$ and accuracy by up to 21.9\%.