 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountering Misinformation via Emotional Response Generation
Nov 17, 2023



The proliferation of misinformation on social media platforms (SMPs) poses a significant danger to public health, social cohesion and ultimately democracy. Previous research has shown how social correction can be an effective way to curb misinformation, by engaging directly in a constructive dialogue with users who spread -- often in good faith -- misleading messages. Although professional fact-checkers are crucial to debunking viral claims, they usually do not engage in conversations on social media. Thereby, significant effort has been made to automate the use of fact-checker material in social correction; however, no previous work has tried to integrate it with the style and pragmatics that are commonly employed in social media communication. To fill this gap, we present VerMouth, the first large-scale dataset comprising roughly 12 thousand claim-response pairs (linked to debunking articles), accounting for both SMP-style and basic emotions, two factors which have a significant role in misinformation credibility and spreading. To collect this dataset we used a technique based on an author-reviewer pipeline, which efficiently combines LLMs and human annotators to obtain high-quality data. We also provide comprehensive experiments showing how models trained on our proposed dataset have significant improvements in terms of output quality and generalization capabilities.
Glitter or Gold? Deriving Structured Insights from Sustainability Reports via Large Language Models
Oct 09, 2023Over the last decade, several regulatory bodies have started requiring the disclosure of non-financial information from publicly listed companies, in light of the investors' increasing attention to Environmental, Social, and Governance (ESG) issues. Such information is publicly released in a variety of non-structured and multi-modal documentation. Hence, it is not straightforward to aggregate and consolidate such data in a cohesive framework to further derive insights about sustainability practices across companies and markets. Thus, it is natural to resort to Information Extraction (IE) techniques to provide concise, informative and actionable data to the stakeholders. Moving beyond traditional text processing techniques, in this work we leverage Large Language Models (LLMs), along with prominent approaches such as Retrieved Augmented Generation and in-context learning, to extract semantically structured information from sustainability reports. We then adopt graph-based representations to generate meaningful statistical, similarity and correlation analyses concerning the obtained findings, highlighting the prominent sustainability actions undertaken across industries and discussing emerging similarity and disclosing patterns at company, sector and region levels. Lastly, we investigate which factual aspects impact the most on companies' ESG scores using our findings and other company information.
Let's ViCE! Mimicking Human Cognitive Behavior in Image Generation Evaluation
Jul 19, 2023Research in Image Generation has recently made significant progress, particularly boosted by the introduction of Vision-Language models which are able to produce high-quality visual content based on textual inputs. Despite ongoing advancements in terms of generation quality and realism, no methodical frameworks have been defined yet to quantitatively measure the quality of the generated content and the adherence with the prompted requests: so far, only human-based evaluations have been adopted for quality satisfaction and for comparing different generative methods. We introduce a novel automated method for Visual Concept Evaluation (ViCE), i.e. to assess consistency between a generated/edited image and the corresponding prompt/instructions, with a process inspired by the human cognitive behaviour. ViCE combines the strengths of Large Language Models (LLMs) and Visual Question Answering (VQA) into a unified pipeline, aiming to replicate the human cognitive process in quality assessment. This method outlines visual concepts, formulates image-specific verification questions, utilizes the Q&A system to investigate the image, and scores the combined outcome. Although this brave new hypothesis of mimicking humans in the image evaluation process is in its preliminary assessment stage, results are promising and open the door to a new form of automatic evaluation which could have significant impact as the image generation or the image target editing tasks become more and more sophisticated.
LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization
Jan 26, 2023



Text Summarization is a popular task and an active area of research for the Natural Language Processing community. By definition, it requires to account for long input texts, a characteristic which poses computational challenges for neural models. Moreover, real-world documents come in a variety of complex, visually-rich, layouts. This information is of great relevance, whether to highlight salient content or to encode long-range interactions between textual passages. Yet, all publicly available summarization datasets only provide plain text content. To facilitate research on how to exploit visual/layout information to better capture long-range dependencies in summarization models, we present LoRaLay, a collection of datasets for long-range summarization with accompanying visual/layout information. We extend existing and popular English datasets (arXiv and PubMed) with layout information and propose four novel datasets -- consistently built from scholar resources -- covering French, Spanish, Portuguese, and Korean languages. Further, we propose new baselines merging layout-aware and long-range models -- two orthogonal approaches -- and obtain state-of-the-art results, showing the importance of combining both lines of research.
Which Discriminator for Cooperative Text Generation?
Apr 25, 2022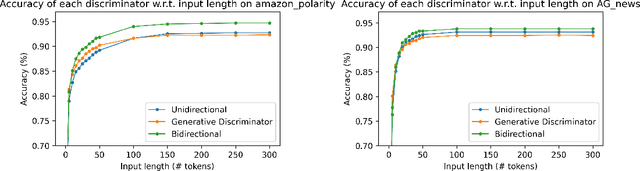

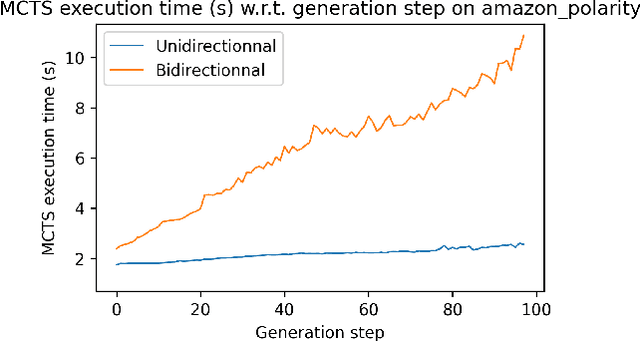
Language models generate texts by successively predicting probability distributions for next tokens given past ones. A growing field of interest tries to leverage external information in the decoding process so that the generated texts have desired properties, such as being more natural, non toxic, faithful, or having a specific writing style. A solution is to use a classifier at each generation step, resulting in a cooperative environment where the classifier guides the decoding of the language model distribution towards relevant texts for the task at hand. In this paper, we examine three families of (transformer-based) discriminators for this specific task of cooperative decoding: bidirectional, left-to-right and generative ones. We evaluate the pros and cons of these different types of discriminators for cooperative generation, exploring respective accuracy on classification tasks along with their impact on the resulting sample quality and computational performances. We also provide the code of a batched implementation of the powerful cooperative decoding strategy used for our experiments, the Monte Carlo Tree Search, working with each discriminator for Natural Language Generation.
Generative Cooperative Networks for Natural Language Generation
Jan 28, 2022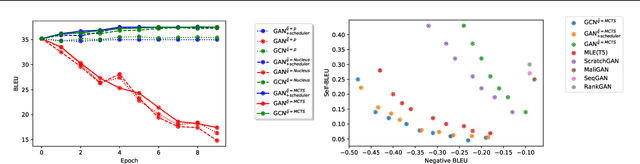
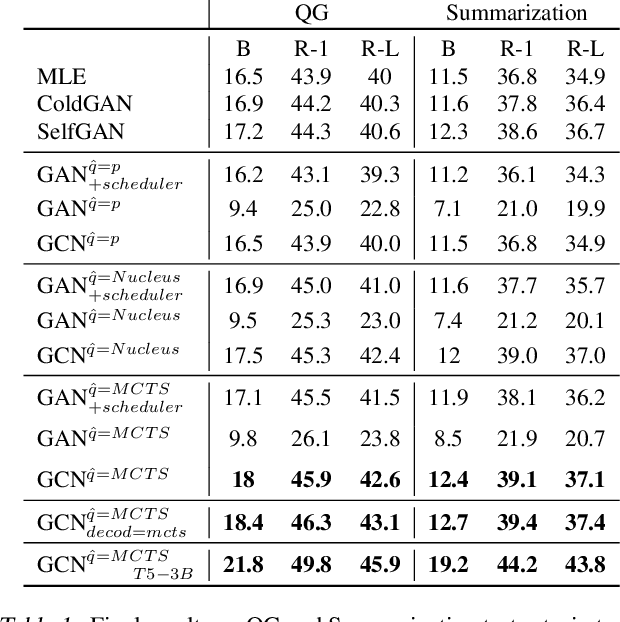
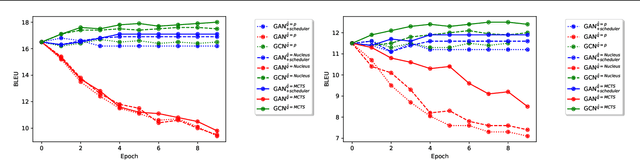
Generative Adversarial Networks (GANs) have known a tremendous success for many continuous generation tasks, especially in the field of image generation. However, for discrete outputs such as language, optimizing GANs remains an open problem with many instabilities, as no gradient can be properly back-propagated from the discriminator output to the generator parameters. An alternative is to learn the generator network via reinforcement learning, using the discriminator signal as a reward, but such a technique suffers from moving rewards and vanishing gradient problems. Finally, it often falls short compared to direct maximum-likelihood approaches. In this paper, we introduce Generative Cooperative Networks, in which the discriminator architecture is cooperatively used along with the generation policy to output samples of realistic texts for the task at hand. We give theoretical guarantees of convergence for our approach, and study various efficient decoding schemes to empirically achieve state-of-the-art results in two main NLG tasks.
Skim-Attention: Learning to Focus via Document Layout
Sep 02, 2021
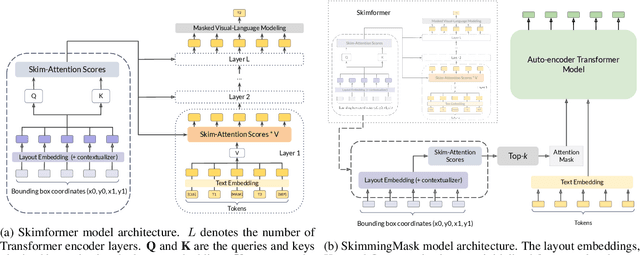

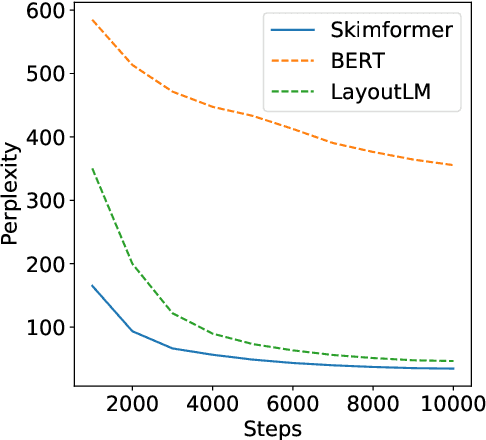
Transformer-based pre-training techniques of text and layout have proven effective in a number of document understanding tasks. Despite this success, multimodal pre-training models suffer from very high computational and memory costs. Motivated by human reading strategies, this paper presents Skim-Attention, a new attention mechanism that takes advantage of the structure of the document and its layout. Skim-Attention only attends to the 2-dimensional position of the words in a document. Our experiments show that Skim-Attention obtains a lower perplexity than prior works, while being more computationally efficient. Skim-Attention can be further combined with long-range Transformers to efficiently process long documents. We also show how Skim-Attention can be used off-the-shelf as a mask for any Pre-trained Language Model, allowing to improve their performance while restricting attention. Finally, we show the emergence of a document structure representation in Skim-Attention.
To Beam Or Not To Beam: That is a Question of Cooperation for Language GANs
Jun 11, 2021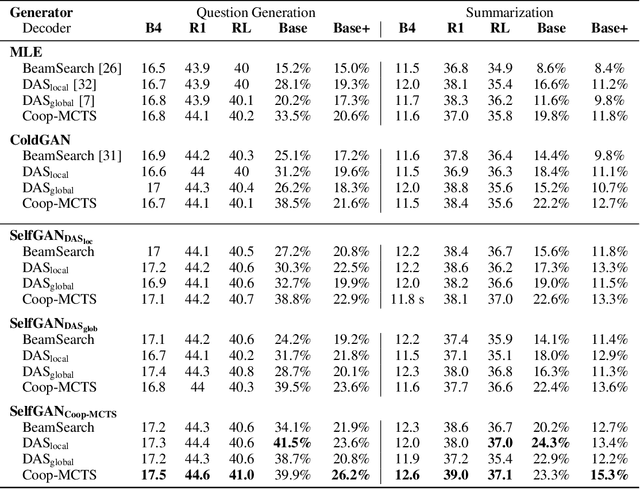
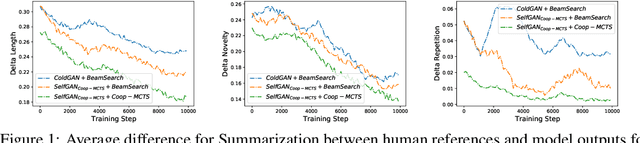
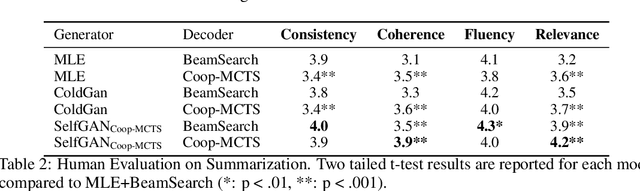
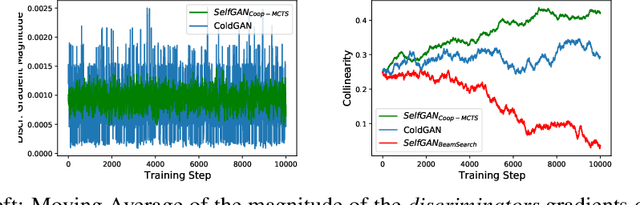
Due to the discrete nature of words, language GANs require to be optimized from rewards provided by discriminator networks, via reinforcement learning methods. This is a much harder setting than for continuous tasks, which enjoy gradient flows from discriminators to generators, usually leading to dramatic learning instabilities. However, we claim that this can be solved by making discriminator and generator networks cooperate to produce output sequences during training. These cooperative outputs, inherently built to obtain higher discrimination scores, not only provide denser rewards for training, but also form a more compact artificial set for discriminator training, hence improving its accuracy and stability. In this paper, we show that our SelfGAN framework, built on this cooperative principle, outperforms Teacher Forcing and obtains state-of-the-art results on two challenging tasks, Summarization and Question Generation.
Rethinking Automatic Evaluation in Sentence Simplification
Apr 16, 2021
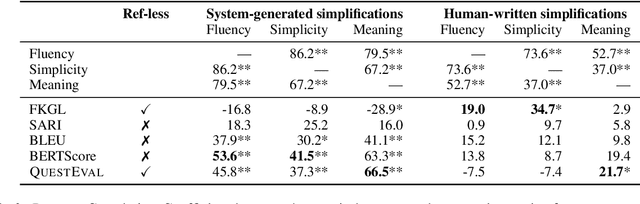
Automatic evaluation remains an open research question in Natural Language Generation. In the context of Sentence Simplification, this is particularly challenging: the task requires by nature to replace complex words with simpler ones that shares the same meaning. This limits the effectiveness of n-gram based metrics like BLEU. Going hand in hand with the recent advances in NLG, new metrics have been proposed, such as BERTScore for Machine Translation. In summarization, the QuestEval metric proposes to automatically compare two texts by questioning them. In this paper, we first propose a simple modification of QuestEval allowing it to tackle Sentence Simplification. We then extensively evaluate the correlations w.r.t. human judgement for several metrics including the recent BERTScore and QuestEval, and show that the latter obtain state-of-the-art correlations, outperforming standard metrics like BLEU and SARI. More importantly, we also show that a large part of the correlations are actually spurious for all the metrics. To investigate this phenomenon further, we release a new corpus of evaluated simplifications, this time not generated by systems but instead, written by humans. This allows us to remove the spurious correlations and draw very different conclusions from the original ones, resulting in a better understanding of these metrics. In particular, we raise concerns about very low correlations for most of traditional metrics. Our results show that the only significant measure of the Meaning Preservation is our adaptation of QuestEval.
Data-QuestEval: A Referenceless Metric for Data to Text Semantic Evaluation
Apr 15, 2021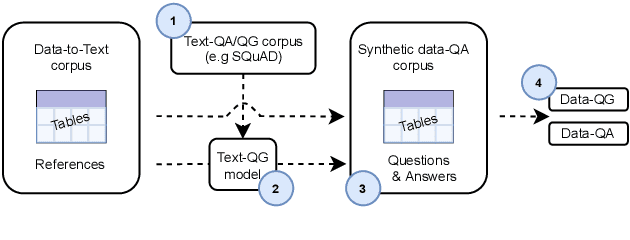
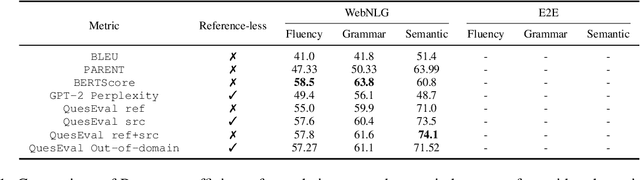

In this paper, we explore how QuestEval, which is a Text-vs-Text metric, can be adapted for the evaluation of Data-to-Text Generation systems. QuestEval is a reference-less metric that compares the predictions directly to the structured input data by automatically asking and answering questions. Its adaptation to Data-to-Text is not straightforward as it requires multi-modal Question Generation and Answering (QG \& QA) systems. To this purpose, we propose to build synthetic multi-modal corpora that enables to train multi-modal QG/QA. The resulting metric is reference-less, multi-modal; it obtains state-of-the-art correlations with human judgement on the E2E and WebNLG benchmark.