 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Conformal Prediction for Regression Models under Label Noise
Sep 18, 2025In high-stakes scenarios, such as medical imaging applications, it is critical to equip the predictions of a regression model with reliable confidence intervals. Recently, Conformal Prediction (CP) has emerged as a powerful statistical framework that, based on a labeled calibration set, generates intervals that include the true labels with a pre-specified probability. In this paper, we address the problem of applying CP for regression models when the calibration set contains noisy labels. We begin by establishing a mathematically grounded procedure for estimating the noise-free CP threshold. Then, we turn it into a practical algorithm that overcomes the challenges arising from the continuous nature of the regression problem. We evaluate the proposed method on two medical imaging regression datasets with Gaussian label noise. Our method significantly outperforms the existing alternative, achieving performance close to the clean-label setting.
Privacy-Preserving Conformal Prediction Under Local Differential Privacy
May 21, 2025



Conformal prediction (CP) provides sets of candidate classes with a guaranteed probability of containing the true class. However, it typically relies on a calibration set with clean labels. We address privacy-sensitive scenarios where the aggregator is untrusted and can only access a perturbed version of the true labels. We propose two complementary approaches under local differential privacy (LDP). In the first approach, users do not access the model but instead provide their input features and a perturbed label using a k-ary randomized response. In the second approach, which enforces stricter privacy constraints, users add noise to their conformity score by binary search response. This method requires access to the classification model but preserves both data and label privacy. Both approaches compute the conformal threshold directly from noisy data without accessing the true labels. We prove finite-sample coverage guarantees and demonstrate robust coverage even under severe randomization. This approach unifies strong local privacy with predictive uncertainty control, making it well-suited for sensitive applications such as medical imaging or large language model queries, regardless of whether users can (or are willing to) compute their own scores.
Detect and Correct: A Selective Noise Correction Method for Learning with Noisy Labels
May 19, 2025Falsely annotated samples, also known as noisy labels, can significantly harm the performance of deep learning models. Two main approaches for learning with noisy labels are global noise estimation and data filtering. Global noise estimation approximates the noise across the entire dataset using a noise transition matrix, but it can unnecessarily adjust correct labels, leaving room for local improvements. Data filtering, on the other hand, discards potentially noisy samples but risks losing valuable data. Our method identifies potentially noisy samples based on their loss distribution. We then apply a selection process to separate noisy and clean samples and learn a noise transition matrix to correct the loss for noisy samples while leaving the clean data unaffected, thereby improving the training process. Our approach ensures robust learning and enhanced model performance by preserving valuable information from noisy samples and refining the correction process. We applied our method to standard image datasets (MNIST, CIFAR-10, and CIFAR-100) and a biological scRNA-seq cell-type annotation dataset. We observed a significant improvement in model accuracy and robustness compared to traditional methods.
Calibration of Network Confidence for Unsupervised Domain Adaptation Using Estimated Accuracy
Sep 06, 2024This study addresses the problem of calibrating network confidence while adapting a model that was originally trained on a source domain to a target domain using unlabeled samples from the target domain. The absence of labels from the target domain makes it impossible to directly calibrate the adapted network on the target domain. To tackle this challenge, we introduce a calibration procedure that relies on estimating the network's accuracy on the target domain. The network accuracy is first computed on the labeled source data and then is modified to represent the actual accuracy of the model on the target domain. The proposed algorithm calibrates the prediction confidence directly in the target domain by minimizing the disparity between the estimated accuracy and the computed confidence. The experimental results show that our method significantly outperforms existing methods, which rely on importance weighting, across several standard datasets.
A conformalized learning of a prediction set with applications to medical imaging classification
Aug 09, 2024Medical imaging classifiers can achieve high predictive accuracy, but quantifying their uncertainty remains an unresolved challenge, which prevents their deployment in medical clinics. We present an algorithm that can modify any classifier to produce a prediction set containing the true label with a user-specified probability, such as 90%. We train a network to predict an instance-based version of the Conformal Prediction threshold. The threshold is then conformalized to ensure the required coverage. We applied the proposed algorithm to several standard medical imaging classification datasets. The experimental results demonstrate that our method outperforms current approaches in terms of smaller average size of the prediction set while maintaining the desired coverage.
The Power of Summary-Source Alignments
Jun 02, 2024Multi-document summarization (MDS) is a challenging task, often decomposed to subtasks of salience and redundancy detection, followed by text generation. In this context, alignment of corresponding sentences between a reference summary and its source documents has been leveraged to generate training data for some of the component tasks. Yet, this enabling alignment step has usually been applied heuristically on the sentence level on a limited number of subtasks. In this paper, we propose extending the summary-source alignment framework by (1) applying it at the more fine-grained proposition span level, (2) annotating alignment manually in a multi-document setup, and (3) revealing the great potential of summary-source alignments to yield several datasets for at least six different tasks. Specifically, for each of the tasks, we release a manually annotated test set that was derived automatically from the alignment annotation. We also release development and train sets in the same way, but from automatically derived alignments. Using the datasets, each task is demonstrated with baseline models and corresponding evaluation metrics to spur future research on this broad challenge.
A Conformal Prediction Score that is Robust to Label Noise
May 04, 2024Conformal Prediction (CP) quantifies network uncertainty by building a small prediction set with a pre-defined probability that the correct class is within this set. In this study we tackle the problem of CP calibration based on a validation set with noisy labels. We introduce a conformal score that is robust to label noise. The noise-free conformal score is estimated using the noisy labeled data and the noise level. In the test phase the noise-free score is used to form the prediction set. We applied the proposed algorithm to several standard medical imaging classification datasets. We show that our method outperforms current methods by a large margin, in terms of the average size of the prediction set, while maintaining the required coverage.
Peek Across: Improving Multi-Document Modeling via Cross-Document Question-Answering
May 24, 2023The integration of multi-document pre-training objectives into language models has resulted in remarkable improvements in multi-document downstream tasks. In this work, we propose extending this idea by pre-training a generic multi-document model from a novel cross-document question answering pre-training objective. To that end, given a set (or cluster) of topically-related documents, we systematically generate semantically-oriented questions from a salient sentence in one document and challenge the model, during pre-training, to answer these questions while "peeking" into other topically-related documents. In a similar manner, the model is also challenged to recover the sentence from which the question was generated, again while leveraging cross-document information. This novel multi-document QA formulation directs the model to better recover cross-text informational relations, and introduces a natural augmentation that artificially increases the pre-training data. Further, unlike prior multi-document models that focus on either classification or summarization tasks, our pre-training objective formulation enables the model to perform tasks that involve both short text generation (e.g., QA) and long text generation (e.g., summarization). Following this scheme, we pre-train our model -- termed QAmden -- and evaluate its performance across several multi-document tasks, including multi-document QA, summarization, and query-focused summarization, yielding improvements of up to 7%, and significantly outperforms zero-shot GPT-3.5 and GPT-4.
Conformal Nucleus Sampling
May 04, 2023



Language models generate text based on successively sampling the next word. A decoding procedure based on nucleus (top-$p$) sampling chooses from the smallest possible set of words whose cumulative probability exceeds the probability $p$. In this work, we assess whether a top-$p$ set is indeed aligned with its probabilistic meaning in various linguistic contexts. We employ conformal prediction, a calibration procedure that focuses on the construction of minimal prediction sets according to a desired confidence level, to calibrate the parameter $p$ as a function of the entropy of the next word distribution. We find that OPT models are overconfident, and that calibration shows a moderate inverse scaling with model size.
Utilizing Evidence Spans via Sequence-Level Contrastive Learning for Long-Context Question Answering
Dec 16, 2021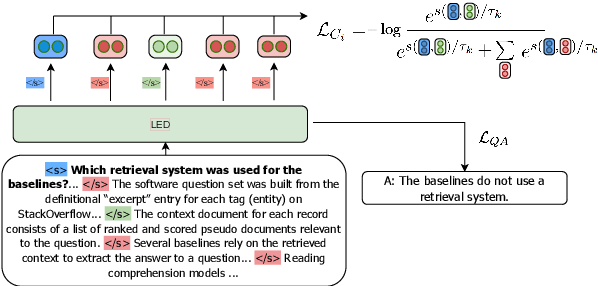

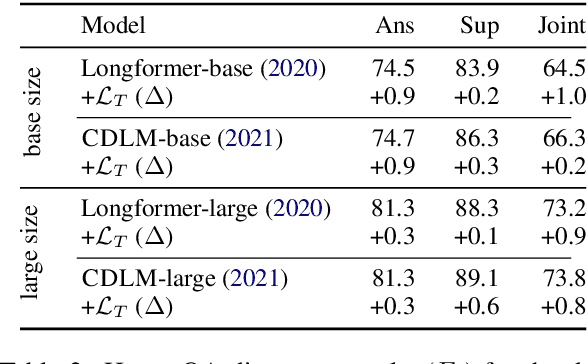
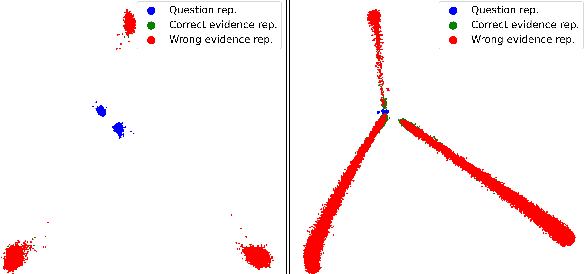
Long-range transformer models have achieved encouraging results on long-context question answering (QA) tasks. Such tasks often require reasoning over a long document, and they benefit from identifying a set of evidence spans (e.g., sentences) that provide supporting evidence for addressing the question. In this work, we propose a novel method for equipping long-range transformers with an additional sequence-level objective for better identification of supporting evidence spans. We achieve this by proposing an additional contrastive supervision signal in finetuning, where the model is encouraged to explicitly discriminate supporting evidence sentences from negative ones by maximizing the question-evidence similarity. The proposed additional loss exhibits consistent improvements on three different strong long-context transformer models, across two challenging question answering benchmarks - HotpotQA and QAsper.