 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Subjectivity of Respect in Police Traffic Stops: Modeling Community Perspectives in Body-Worn Camera Footage
Feb 10, 2026Traffic stops are among the most frequent police-civilian interactions, and body-worn cameras (BWCs) provide a unique record of how these encounters unfold. Respect is a central dimension of these interactions, shaping public trust and perceived legitimacy, yet its interpretation is inherently subjective and shaped by lived experience, rendering community-specific perspectives a critical consideration. Leveraging unprecedented access to Los Angeles Police Department BWC footage, we introduce the first large-scale traffic-stop dataset annotated with respect ratings and free-text rationales from multiple perspectives. By sampling annotators from police-affiliated, justice-system-impacted, and non-affiliated Los Angeles residents, we enable the systematic study of perceptual differences across diverse communities. To this end, we (i) develop a domain-specific evaluation rubric grounded in procedural justice theory, LAPD training materials, and extensive fieldwork; (ii) introduce a rubric-driven preference data construction framework for perspective-consistent alignment; and (iii) propose a perspective-aware modeling framework that predicts personalized respect ratings and generates annotator-specific rationales for both officers and civilian drivers from traffic-stop transcripts. Across all three annotator groups, our approach improves both rating prediction performance and rationale alignment. Our perspective-aware framework enables law enforcement to better understand diverse community expectations, providing a vital tool for building public trust and procedural legitimacy.
Self-Explaining Hate Speech Detection with Moral Rationales
Jan 07, 2026Hate speech detection models rely on surface-level lexical features, increasing vulnerability to spurious correlations and limiting robustness, cultural contextualization, and interpretability. We propose Supervised Moral Rationale Attention (SMRA), the first self-explaining hate speech detection framework to incorporate moral rationales as direct supervision for attention alignment. Based on Moral Foundations Theory, SMRA aligns token-level attention with expert-annotated moral rationales, guiding models to attend to morally salient spans rather than spurious lexical patterns. Unlike prior rationale-supervised or post-hoc approaches, SMRA integrates moral rationale supervision directly into the training objective, producing inherently interpretable and contextualized explanations. To support our framework, we also introduce HateBRMoralXplain, a Brazilian Portuguese benchmark dataset annotated with hate labels, moral categories, token-level moral rationales, and socio-political metadata. Across binary hate speech detection and multi-label moral sentiment classification, SMRA consistently improves performance (e.g., +0.9 and +1.5 F1, respectively) while substantially enhancing explanation faithfulness, increasing IoU F1 (+7.4 pp) and Token F1 (+5.0 pp). Although explanations become more concise, sufficiency improves (+2.3 pp) and fairness remains stable, indicating more faithful rationales without performance or bias trade-offs
Theory Trace Card: Theory-Driven Socio-Cognitive Evaluation of LLMs
Jan 05, 2026Socio-cognitive benchmarks for large language models (LLMs) often fail to predict real-world behavior, even when models achieve high benchmark scores. Prior work has attributed this evaluation-deployment gap to problems of measurement and validity. While these critiques are insightful, we argue that they overlook a more fundamental issue: many socio-cognitive evaluations proceed without an explicit theoretical specification of the target capability, leaving the assumptions linking task performance to competence implicit. Without this theoretical grounding, benchmarks that exercise only narrow subsets of a capability are routinely misinterpreted as evidence of broad competence: a gap that creates a systemic validity illusion by masking the failure to evaluate the capability's other essential dimensions. To address this gap, we make two contributions. First, we diagnose and formalize this theory gap as a foundational failure that undermines measurement and enables systematic overgeneralization of benchmark results. Second, we introduce the Theory Trace Card (TTC), a lightweight documentation artifact designed to accompany socio-cognitive evaluations, which explicitly outlines the theoretical basis of an evaluation, the components of the target capability it exercises, its operationalization, and its limitations. We argue that TTCs enhance the interpretability and reuse of socio-cognitive evaluations by making explicit the full validity chain, which links theory, task operationalization, scoring, and limitations, without modifying benchmarks or requiring agreement on a single theory.
Authors Should Label Their Own Documents
Dec 27, 2025Third-party annotation is the status quo for labeling text, but egocentric information such as sentiment and belief can at best only be approximated by a third-person proxy. We introduce author labeling, an annotation technique where the writer of the document itself annotates the data at the moment of creation. We collaborate with a commercial chatbot with over 20,000 users to deploy an author labeling annotation system. This system identifies task-relevant queries, generates on-the-fly labeling questions, and records authors' answers in real time. We train and deploy an online-learning model architecture for product recommendation with author-labeled data to improve performance. We train our model to minimize the prediction error on questions generated for a set of predetermined subjective beliefs using author-labeled responses. Our model achieves a 537% improvement in click-through rate compared to an industry advertising baseline running concurrently. We then compare the quality and practicality of author labeling to three traditional annotation approaches for sentiment analysis and find author labeling to be higher quality, faster to acquire, and cheaper. These findings reinforce existing literature that annotations, especially for egocentric and subjective beliefs, are significantly higher quality when labeled by the author rather than a third party. To facilitate broader scientific adoption, we release an author labeling service for the research community at https://academic.echollm.io.
Authors Should Annotate
Dec 15, 2025The status quo for labeling text is third-party annotation, but there are many cases where information directly from the document's source would be preferable over a third-person proxy, especially for egocentric features like sentiment and belief. We introduce author labeling, an annotation technique where the writer of the document itself annotates the data at the moment of creation. We collaborate with a commercial chatbot with over 10,000 users to deploy an author labeling annotation system for subjective features related to product recommendation. This system identifies task-relevant queries, generates on-the-fly labeling questions, and records authors' answers in real time. We train and deploy an online-learning model architecture for product recommendation that continuously improves from author labeling and find it achieved a 534% increase in click-through rate compared to an industry advertising baseline running concurrently. We then compare the quality and practicality of author labeling to three traditional annotation approaches for sentiment analysis and find author labeling to be higher quality, faster to acquire, and cheaper. These findings reinforce existing literature that annotations, especially for egocentric and subjective beliefs, are significantly higher quality when labeled by the author rather than a third party. To facilitate broader scientific adoption, we release an author labeling service for the research community at academic.echollm.io.
MFTCXplain: A Multilingual Benchmark Dataset for Evaluating the Moral Reasoning of LLMs through Hate Speech Multi-hop Explanation
Jun 23, 2025Ensuring the moral reasoning capabilities of Large Language Models (LLMs) is a growing concern as these systems are used in socially sensitive tasks. Nevertheless, current evaluation benchmarks present two major shortcomings: a lack of annotations that justify moral classifications, which limits transparency and interpretability; and a predominant focus on English, which constrains the assessment of moral reasoning across diverse cultural settings. In this paper, we introduce MFTCXplain, a multilingual benchmark dataset for evaluating the moral reasoning of LLMs via hate speech multi-hop explanation using Moral Foundation Theory (MFT). The dataset comprises 3,000 tweets across Portuguese, Italian, Persian, and English, annotated with binary hate speech labels, moral categories, and text span-level rationales. Empirical results highlight a misalignment between LLM outputs and human annotations in moral reasoning tasks. While LLMs perform well in hate speech detection (F1 up to 0.836), their ability to predict moral sentiments is notably weak (F1 < 0.35). Furthermore, rationale alignment remains limited mainly in underrepresented languages. These findings show the limited capacity of current LLMs to internalize and reflect human moral reasoning.
A Multi-Perspective Machine Learning Approach to Evaluate Police-Driver Interaction in Los Angeles
Feb 08, 2024Interactions between the government officials and civilians affect public wellbeing and the state legitimacy that is necessary for the functioning of democratic society. Police officers, the most visible and contacted agents of the state, interact with the public more than 20 million times a year during traffic stops. Today, these interactions are regularly recorded by body-worn cameras (BWCs), which are lauded as a means to enhance police accountability and improve police-public interactions. However, the timely analysis of these recordings is hampered by a lack of reliable automated tools that can enable the analysis of these complex and contested police-public interactions. This article proposes an approach to developing new multi-perspective, multimodal machine learning (ML) tools to analyze the audio, video, and transcript information from this BWC footage. Our approach begins by identifying the aspects of communication most salient to different stakeholders, including both community members and police officers. We move away from modeling approaches built around the existence of a single ground truth and instead utilize new advances in soft labeling to incorporate variation in how different observers perceive the same interactions. We argue that this inclusive approach to the conceptualization and design of new ML tools is broadly applicable to the study of communication and development of analytic tools across domains of human interaction, including education, medicine, and the workplace.
The Moral Foundations Reddit Corpus
Aug 18, 2022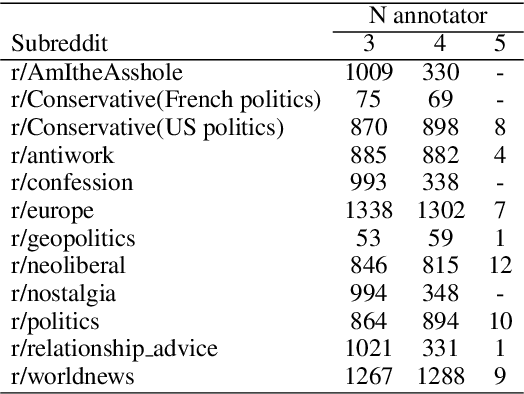
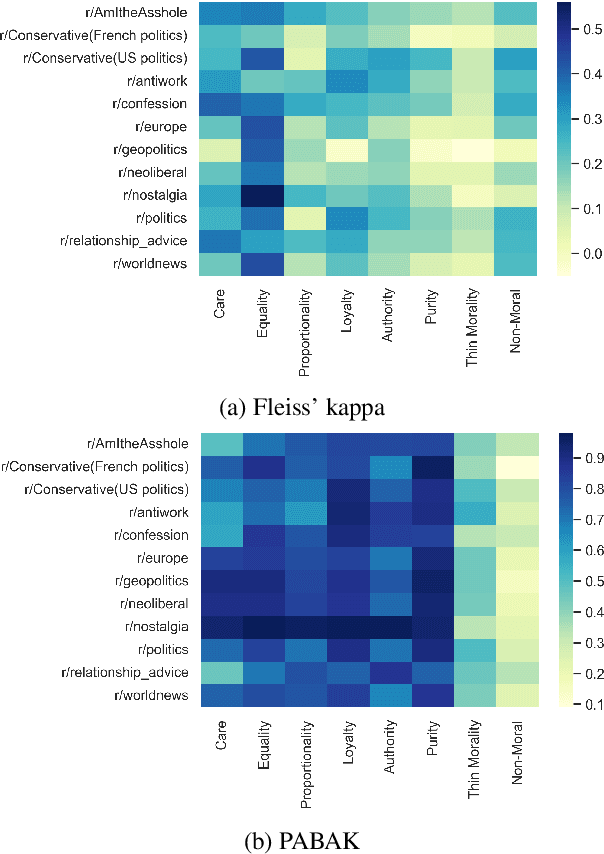
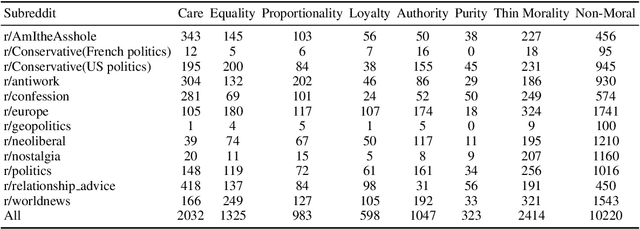
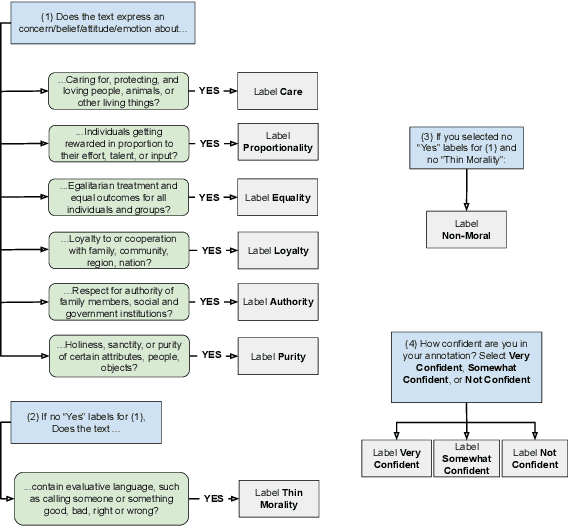
Moral framing and sentiment can affect a variety of online and offline behaviors, including donation, pro-environmental action, political engagement, and even participation in violent protests. Various computational methods in Natural Language Processing (NLP) have been used to detect moral sentiment from textual data, but in order to achieve better performances in such subjective tasks, large sets of hand-annotated training data are needed. Previous corpora annotated for moral sentiment have proven valuable, and have generated new insights both within NLP and across the social sciences, but have been limited to Twitter. To facilitate improving our understanding of the role of moral rhetoric, we present the Moral Foundations Reddit Corpus, a collection of 16,123 Reddit comments that have been curated from 12 distinct subreddits, hand-annotated by at least three trained annotators for 8 categories of moral sentiment (i.e., Care, Proportionality, Equality, Purity, Authority, Loyalty, Thin Morality, Implicit/Explicit Morality) based on the updated Moral Foundations Theory (MFT) framework. We use a range of methodologies to provide baseline moral-sentiment classification results for this new corpus, e.g., cross-domain classification and knowledge transfer.