 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory Trace Card: Theory-Driven Socio-Cognitive Evaluation of LLMs
Jan 05, 2026Socio-cognitive benchmarks for large language models (LLMs) often fail to predict real-world behavior, even when models achieve high benchmark scores. Prior work has attributed this evaluation-deployment gap to problems of measurement and validity. While these critiques are insightful, we argue that they overlook a more fundamental issue: many socio-cognitive evaluations proceed without an explicit theoretical specification of the target capability, leaving the assumptions linking task performance to competence implicit. Without this theoretical grounding, benchmarks that exercise only narrow subsets of a capability are routinely misinterpreted as evidence of broad competence: a gap that creates a systemic validity illusion by masking the failure to evaluate the capability's other essential dimensions. To address this gap, we make two contributions. First, we diagnose and formalize this theory gap as a foundational failure that undermines measurement and enables systematic overgeneralization of benchmark results. Second, we introduce the Theory Trace Card (TTC), a lightweight documentation artifact designed to accompany socio-cognitive evaluations, which explicitly outlines the theoretical basis of an evaluation, the components of the target capability it exercises, its operationalization, and its limitations. We argue that TTCs enhance the interpretability and reuse of socio-cognitive evaluations by making explicit the full validity chain, which links theory, task operationalization, scoring, and limitations, without modifying benchmarks or requiring agreement on a single theory.
Realistic threat perception drives intergroup conflict: A causal, dynamic analysis using generative-agent simulations
Dec 18, 2025Human conflict is often attributed to threats against material conditions and symbolic values, yet it remains unclear how they interact and which dominates. Progress is limited by weak causal control, ethical constraints, and scarce temporal data. We address these barriers using simulations of large language model (LLM)-driven agents in virtual societies, independently varying realistic and symbolic threat while tracking actions, language, and attitudes. Representational analyses show that the underlying LLM encodes realistic threat, symbolic threat, and hostility as distinct internal states, that our manipulations map onto them, and that steering these states causally shifts behavior. Our simulations provide a causal account of threat-driven conflict over time: realistic threat directly increases hostility, whereas symbolic threat effects are weaker, fully mediated by ingroup bias, and increase hostility only when realistic threat is absent. Non-hostile intergroup contact buffers escalation, and structural asymmetries concentrate hostility among majority groups.
MFTCXplain: A Multilingual Benchmark Dataset for Evaluating the Moral Reasoning of LLMs through Hate Speech Multi-hop Explanation
Jun 23, 2025Ensuring the moral reasoning capabilities of Large Language Models (LLMs) is a growing concern as these systems are used in socially sensitive tasks. Nevertheless, current evaluation benchmarks present two major shortcomings: a lack of annotations that justify moral classifications, which limits transparency and interpretability; and a predominant focus on English, which constrains the assessment of moral reasoning across diverse cultural settings. In this paper, we introduce MFTCXplain, a multilingual benchmark dataset for evaluating the moral reasoning of LLMs via hate speech multi-hop explanation using Moral Foundation Theory (MFT). The dataset comprises 3,000 tweets across Portuguese, Italian, Persian, and English, annotated with binary hate speech labels, moral categories, and text span-level rationales. Empirical results highlight a misalignment between LLM outputs and human annotations in moral reasoning tasks. While LLMs perform well in hate speech detection (F1 up to 0.836), their ability to predict moral sentiments is notably weak (F1 < 0.35). Furthermore, rationale alignment remains limited mainly in underrepresented languages. These findings show the limited capacity of current LLMs to internalize and reflect human moral reasoning.
Reasoning on a Spectrum: Aligning LLMs to System 1 and System 2 Thinking
Feb 18, 2025



Large Language Models (LLMs) exhibit impressive reasoning abilities, yet their reliance on structured step-by-step processing reveals a critical limitation. While human cognition fluidly adapts between intuitive, heuristic (System 1) and analytical, deliberative (System 2) reasoning depending on the context, LLMs lack this dynamic flexibility. This rigidity can lead to brittle and unreliable performance when faced with tasks that deviate from their trained patterns. To address this, we create a dataset of 2,000 samples with valid System 1 and System 2 answers, explicitly align LLMs with these reasoning styles, and evaluate their performance across reasoning benchmarks. Our results reveal an accuracy-efficiency trade-off: System 2-aligned models excel in arithmetic and symbolic reasoning, while System 1-aligned models perform better in commonsense tasks. A mechanistic analysis of model responses shows that System 1 models employ more definitive answers, whereas System 2 models demonstrate greater uncertainty. Interpolating between these extremes produces a monotonic transition in reasoning accuracy, preserving coherence. This work challenges the assumption that step-by-step reasoning is always optimal and highlights the need for adapting reasoning strategies based on task demands.
The Moral Foundations Reddit Corpus
Aug 18, 2022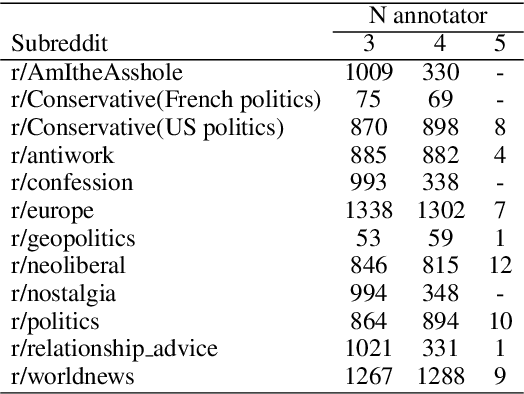
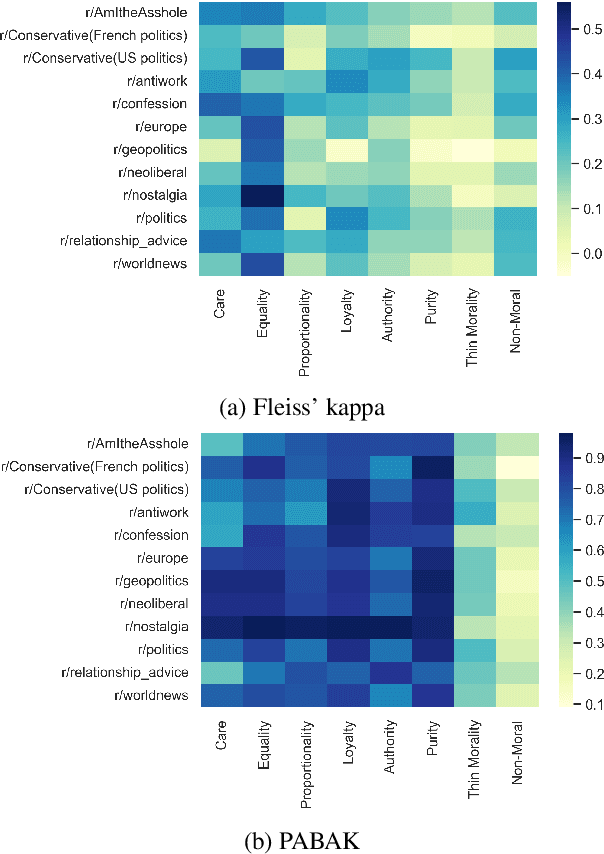
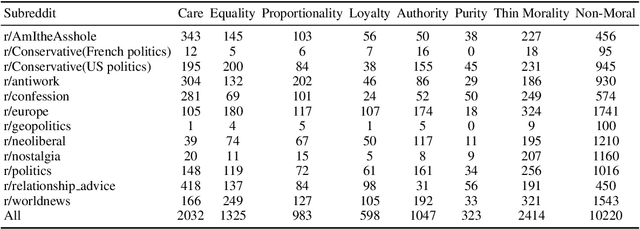
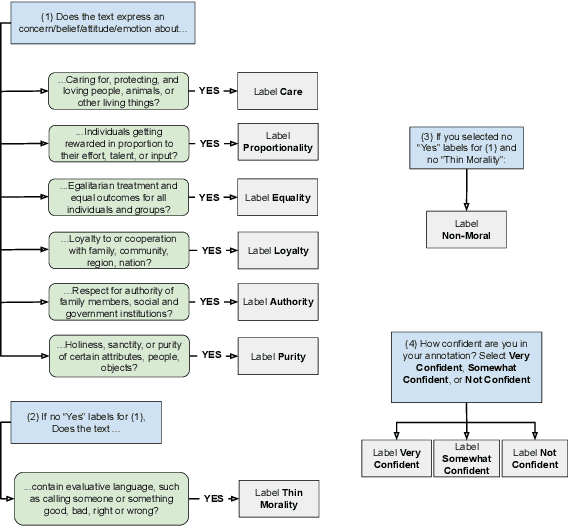
Moral framing and sentiment can affect a variety of online and offline behaviors, including donation, pro-environmental action, political engagement, and even participation in violent protests. Various computational methods in Natural Language Processing (NLP) have been used to detect moral sentiment from textual data, but in order to achieve better performances in such subjective tasks, large sets of hand-annotated training data are needed. Previous corpora annotated for moral sentiment have proven valuable, and have generated new insights both within NLP and across the social sciences, but have been limited to Twitter. To facilitate improving our understanding of the role of moral rhetoric, we present the Moral Foundations Reddit Corpus, a collection of 16,123 Reddit comments that have been curated from 12 distinct subreddits, hand-annotated by at least three trained annotators for 8 categories of moral sentiment (i.e., Care, Proportionality, Equality, Purity, Authority, Loyalty, Thin Morality, Implicit/Explicit Morality) based on the updated Moral Foundations Theory (MFT) framework. We use a range of methodologies to provide baseline moral-sentiment classification results for this new corpus, e.g., cross-domain classification and knowledge transfer.