 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe KITMUS Test: Evaluating Knowledge Integration from Multiple Sources in Natural Language Understanding Systems
Dec 15, 2022Many state-of-the-art natural language understanding (NLU) models are based on pretrained neural language models. These models often make inferences using information from multiple sources. An important class of such inferences are those that require both background knowledge, presumably contained in a model's pretrained parameters, and instance-specific information that is supplied at inference time. However, the integration and reasoning abilities of NLU models in the presence of multiple knowledge sources have been largely understudied. In this work, we propose a test suite of coreference resolution tasks that require reasoning over multiple facts. Our dataset is organized into subtasks that differ in terms of which knowledge sources contain relevant facts. We evaluate state-of-the-art coreference resolution models on our dataset. Our results indicate that several models struggle to reason on-the-fly over knowledge observed both at pretrain time and at inference time. However, with task-specific training, a subset of models demonstrates the ability to integrate certain knowledge types from multiple sources.
MaskEval: Weighted MLM-Based Evaluation for Text Summarization and Simplification
May 24, 2022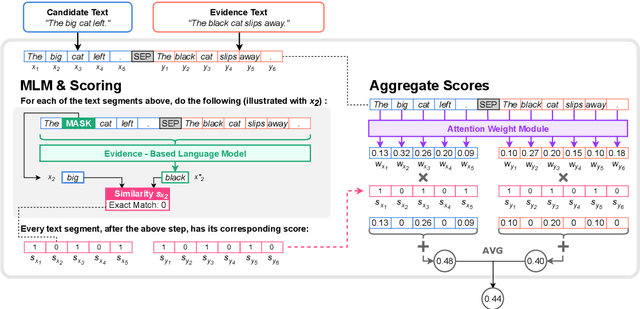
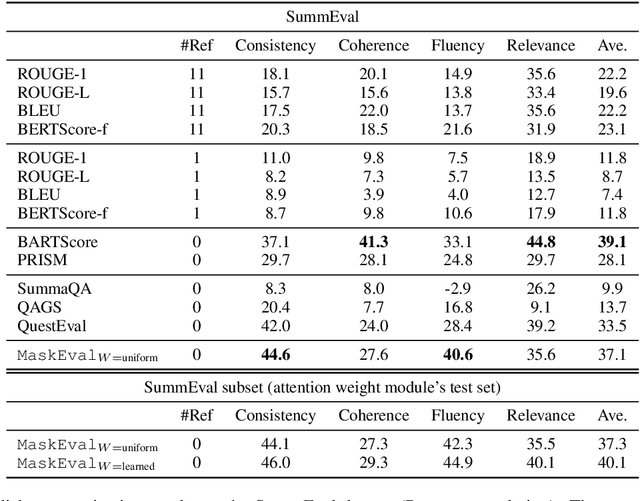
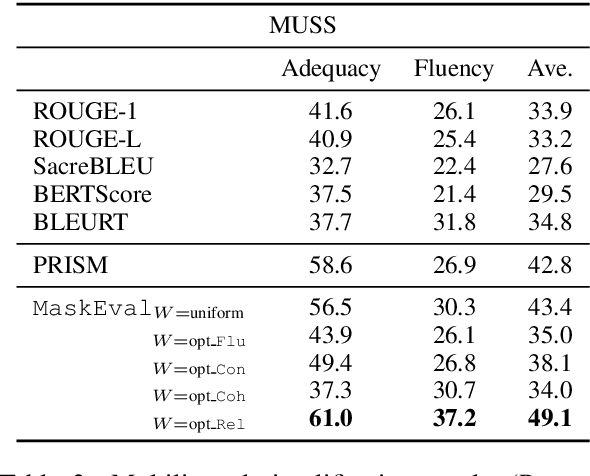
In text summarization and simplification, system outputs must be evaluated along multiple dimensions such as relevance, factual consistency, fluency, and grammaticality, and a wide range of possible outputs could be of high quality. These properties make the development of an adaptable, reference-less evaluation metric both necessary and challenging. We introduce MaskEval, a reference-less metric for text summarization and simplification that operates by performing masked language modeling (MLM) on the concatenation of the candidate and the source texts. It features an attention-like weighting mechanism to modulate the relative importance of each MLM step, which crucially allows MaskEval to be adapted to evaluate different quality dimensions. We demonstrate its effectiveness on English summarization and on multilingual text simplification in terms of correlations with human judgments.
Why Exposure Bias Matters: An Imitation Learning Perspective of Error Accumulation in Language Generation
Apr 03, 2022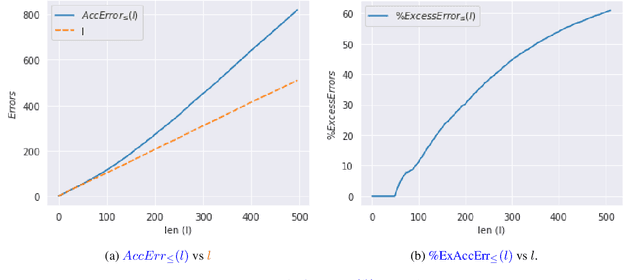
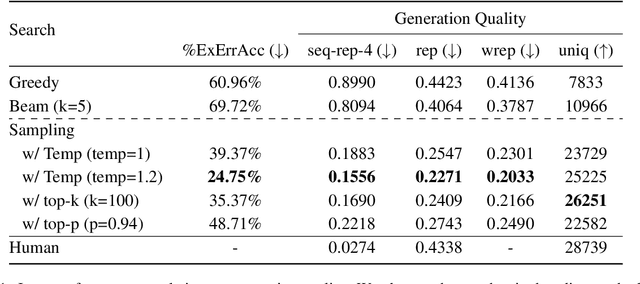
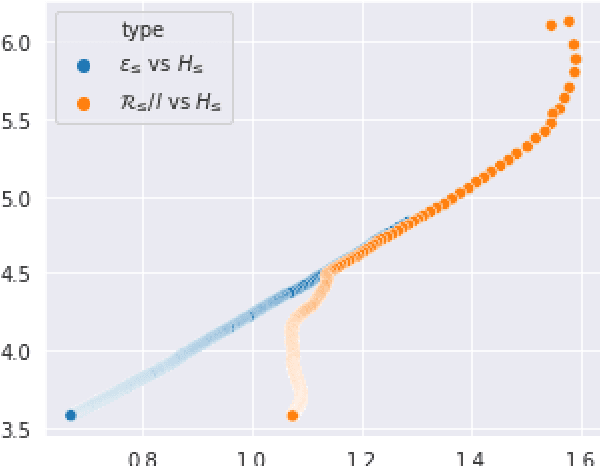
Current language generation models suffer from issues such as repetition, incoherence, and hallucinations. An often-repeated hypothesis is that this brittleness of generation models is caused by the training and the generation procedure mismatch, also referred to as exposure bias. In this paper, we verify this hypothesis by analyzing exposure bias from an imitation learning perspective. We show that exposure bias leads to an accumulation of errors, analyze why perplexity fails to capture this accumulation, and empirically show that this accumulation results in poor generation quality. Source code to reproduce these experiments is available at https://github.com/kushalarora/quantifying_exposure_bias
Does Pre-training Induce Systematic Inference? How Masked Language Models Acquire Commonsense Knowledge
Dec 16, 2021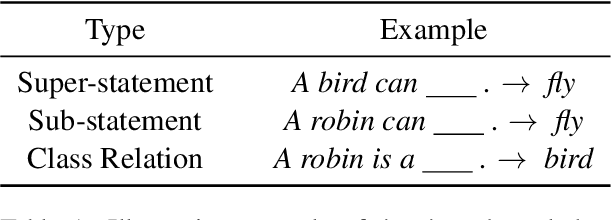
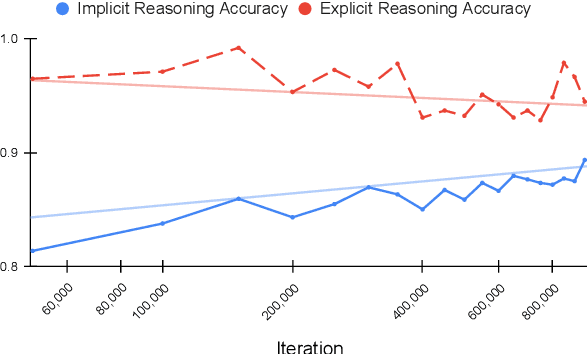
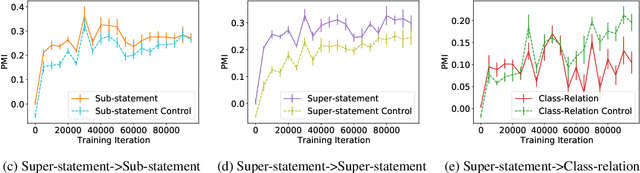
Transformer models pre-trained with a masked-language-modeling objective (e.g., BERT) encode commonsense knowledge as evidenced by behavioral probes; however, the extent to which this knowledge is acquired by systematic inference over the semantics of the pre-training corpora is an open question. To answer this question, we selectively inject verbalized knowledge into the minibatches of a BERT model during pre-training and evaluate how well the model generalizes to supported inferences. We find generalization does not improve over the course of pre-training, suggesting that commonsense knowledge is acquired from surface-level, co-occurrence patterns rather than induced, systematic reasoning.
TIE: A Framework for Embedding-based Incremental Temporal Knowledge Graph Completion
May 09, 2021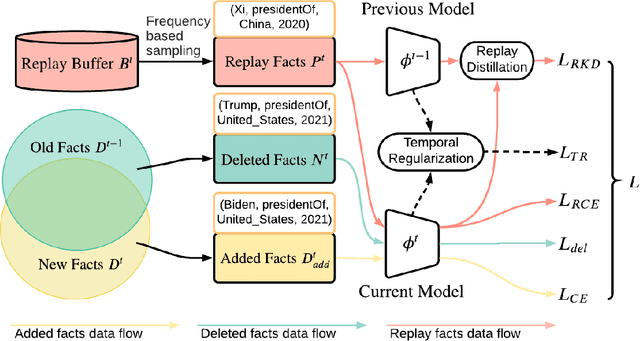

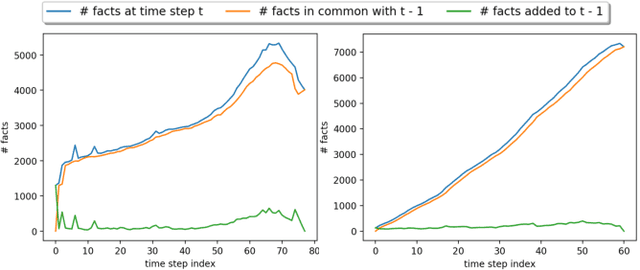
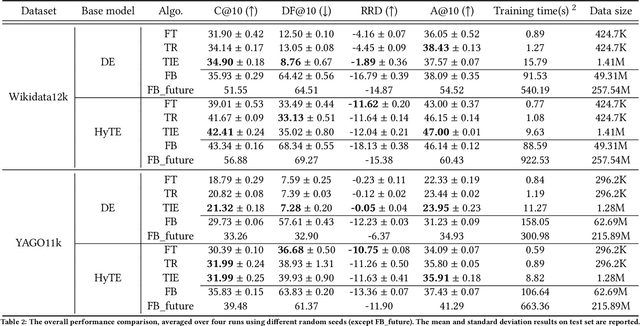
Reasoning in a temporal knowledge graph (TKG) is a critical task for information retrieval and semantic search. It is particularly challenging when the TKG is updated frequently. The model has to adapt to changes in the TKG for efficient training and inference while preserving its performance on historical knowledge. Recent work approaches TKG completion (TKGC) by augmenting the encoder-decoder framework with a time-aware encoding function. However, naively fine-tuning the model at every time step using these methods does not address the problems of 1) catastrophic forgetting, 2) the model's inability to identify the change of facts (e.g., the change of the political affiliation and end of a marriage), and 3) the lack of training efficiency. To address these challenges, we present the Time-aware Incremental Embedding (TIE) framework, which combines TKG representation learning, experience replay, and temporal regularization. We introduce a set of metrics that characterizes the intransigence of the model and propose a constraint that associates the deleted facts with negative labels. Experimental results on Wikidata12k and YAGO11k datasets demonstrate that the proposed TIE framework reduces training time by about ten times and improves on the proposed metrics compared to vanilla full-batch training. It comes without a significant loss in performance for any traditional measures. Extensive ablation studies reveal performance trade-offs among different evaluation metrics, which is essential for decision-making around real-world TKG applications.
Modeling Event Plausibility with Consistent Conceptual Abstraction
Apr 20, 2021


Understanding natural language requires common sense, one aspect of which is the ability to discern the plausibility of events. While distributional models -- most recently pre-trained, Transformer language models -- have demonstrated improvements in modeling event plausibility, their performance still falls short of humans'. In this work, we show that Transformer-based plausibility models are markedly inconsistent across the conceptual classes of a lexical hierarchy, inferring that "a person breathing" is plausible while "a dentist breathing" is not, for example. We find this inconsistency persists even when models are softly injected with lexical knowledge, and we present a simple post-hoc method of forcing model consistency that improves correlation with human plausibility judgements.
Characterizing Idioms: Conventionality and Contingency
Apr 17, 2021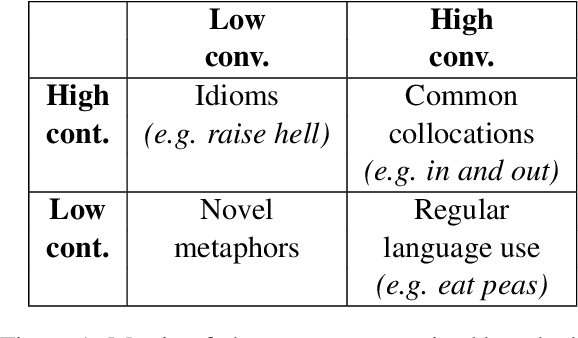
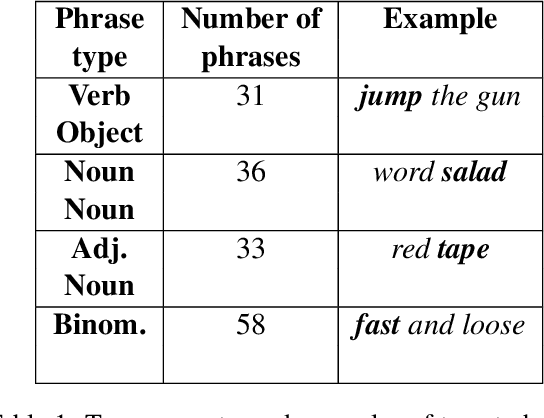
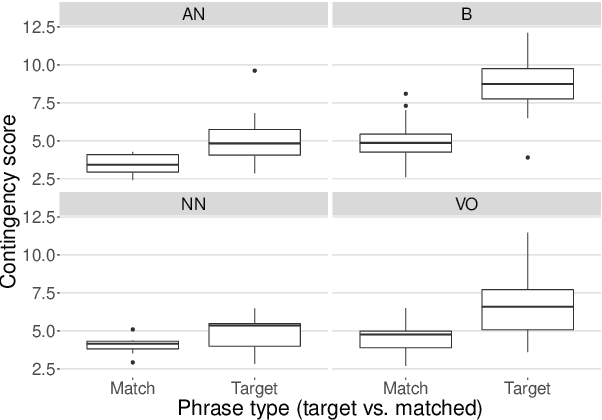
Idioms are unlike other phrases in two important ways. First, the words in an idiom have unconventional meanings. Second, the unconventional meaning of words in an idiom are contingent on the presence of the other words in the idiom. Linguistic theories disagree about whether these two properties depend on one another, as well as whether special theoretical machinery is needed to accommodate idioms. We define two measures that correspond to these two properties, and we show that idioms fall at the expected intersection of the two dimensions, but that the dimensions themselves are not correlated. Our results suggest that idioms are no more anomalous than other types of phrases, and that introducing special machinery to handle idioms may not be warranted.
The Topic Confusion Task: A Novel Scenario for Authorship Attribution
Apr 17, 2021
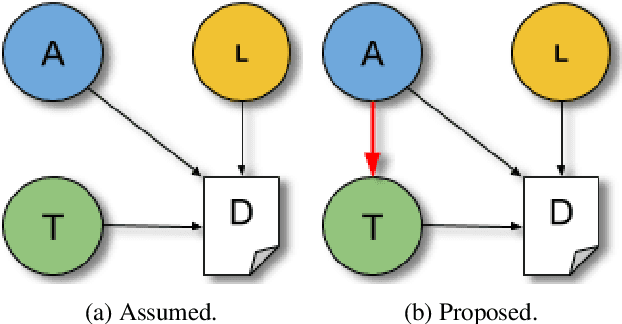
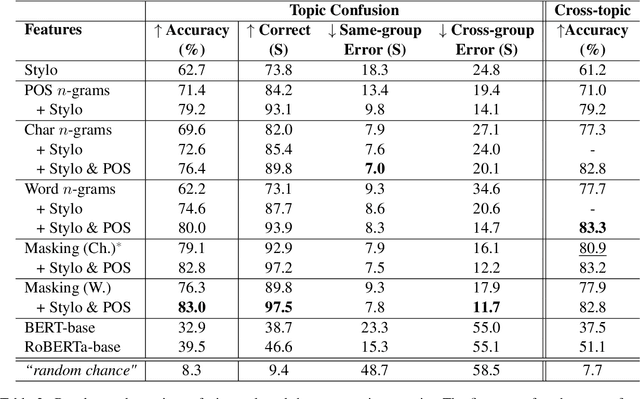
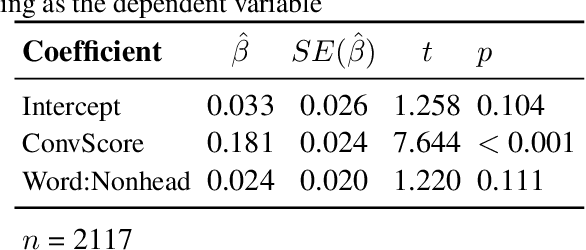
Authorship attribution is the problem of identifying the most plausible author of an anonymous text from a set of candidate authors. Researchers have investigated same-topic and cross-topic scenarios of authorship attribution, which differ according to whether unseen topics are used in the testing phase. However, neither scenario allows us to explain whether errors are caused by failure to capture authorship style, by the topic shift or by other factors. Motivated by this, we propose the \emph{topic confusion} task, where we switch the author-topic configuration between training and testing set. This setup allows us to probe errors in the attribution process. We investigate the accuracy and two error measures: one caused by the models' confusion by the switch because the features capture the topics, and one caused by the features' inability to capture the writing styles, leading to weaker models. By evaluating different features, we show that stylometric features with part-of-speech tags are less susceptible to topic variations and can increase the accuracy of the attribution process. We further show that combining them with word-level $n$-grams can outperform the state-of-the-art technique in the cross-topic scenario. Finally, we show that pretrained language models such as BERT and RoBERTa perform poorly on this task, and are outperformed by simple $n$-gram features.
On-the-Fly Attention Modularization for Neural Generation
Jan 02, 2021
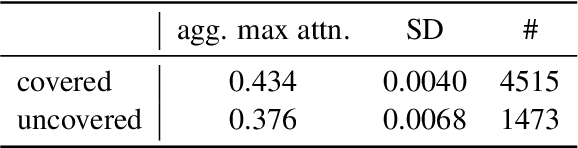
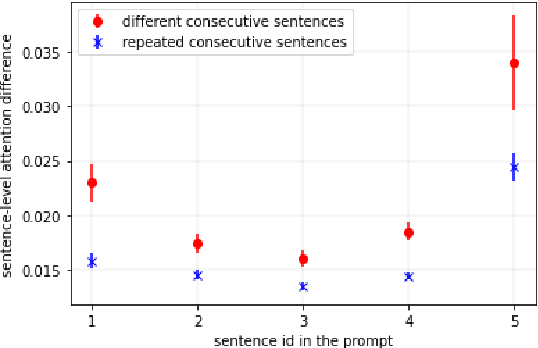
Despite considerable advancements with deep neural language models (LMs), neural text generation still suffers from degeneration: generated text is repetitive, generic, self-inconsistent, and lacking commonsense. The empirical analyses on sentence-level attention patterns reveal that neural text degeneration may be associated with insufficient learning of inductive biases by the attention mechanism. Our findings motivate on-the-fly attention modularization, a simple but effective method for injecting inductive biases into attention computation during inference. The resulting text produced by the language model with attention modularization can yield enhanced diversity and commonsense reasoning while maintaining fluency and coherence.
Optimizing Deeper Transformers on Small Datasets: An Application on Text-to-SQL Semantic Parsing
Dec 30, 2020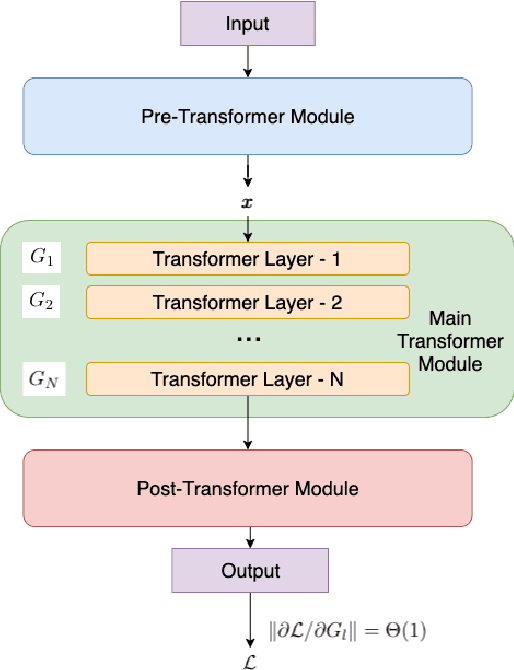
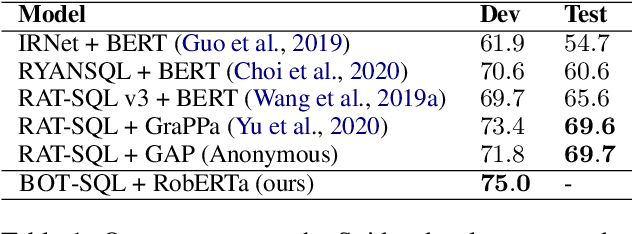
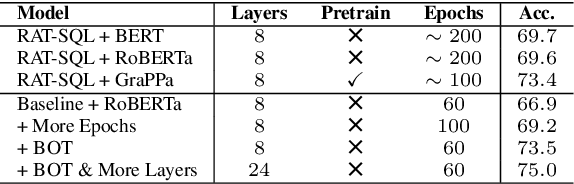
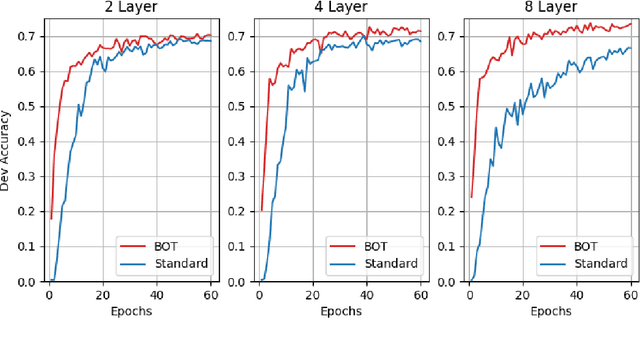
Due to the common belief that training deep transformers from scratch requires large datasets, people usually only use shallow and simple additional layers on top of pre-trained models during fine-tuning on small datasets. We provide evidence that this does not always need to be the case: with proper initialization and training techniques, the benefits of very deep transformers are shown to carry over to hard structural prediction tasks, even using small datasets. In particular, we successfully train 48 layers of transformers for a semantic parsing task. These comprise 24 fine-tuned transformer layers from pre-trained RoBERTa and 24 relation-aware transformer layers trained from scratch. With fewer training steps and no task-specific pre-training, we obtain the state of the art performance on the challenging cross-domain Text-to-SQL semantic parsing benchmark Spider. We achieve this by deriving a novel Data dependent Transformer Fixed-update initialization scheme (DT-Fixup), inspired by the prior T-Fixup work. Further error analysis demonstrates that increasing the depth of the transformer model can help improve generalization on the cases requiring reasoning and structural understanding.