 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Defining Erasure Harms for NLP
Jun 14, 2026The deployment of NLP systems has raised concerns about harms they might produce, including representational harms. Recent literature has begun to conceptualize and measure one such harm, the harm of erasure. Nevertheless, the field lacks a clear and cohesive conceptual foundation for identifying and measuring erasure. Existing conceptualizations of erasure are often broad -- making it difficult to identify what is needed to establish and measure erasure -- or else specific to particular settings -- facilitating measurement for those settings but potentially challenging to adapt to other settings. To address this gap, we develop and propose a structured definition of erasure that clarifies what components are necessary for establishing whether erasure has occurred, which practitioners need to explicitly articulate and operationalize in order to measure erasure.
Synthetic Users, Real Differences: an Evaluation Framework for User Simulation in Multi-Turn Conversations
May 04, 2026There is growing interest in exploring user simulation as an alternative to gathering and scoring real user-chatbot interactions for AI chatbot evaluation. For this purpose, it is important to ensure the realism of the simulation, i.e., the extent to which simulated dialogues reflect real dialogues users have with chatbots. Most existing methods evaluating simulation realism produce coarse quality signal and remain solely at the level of individual dialogues. To support more rigorous evaluation in this area, we propose realsim, an evaluation framework that enables practitioners to take a distributional view of real vs. simulated dialogues along 8 dimensions, covering attributes related to the communicative functions of the interaction, user states, and the surface form of user messages. We then instantiate the framework with a curated dataset of 1K multi-turn task-focused real user-chatbot dialogues that cover 16 domains of chatbot applications. Overall, we find that simulated users tend to struggle at capturing communication frictions that real users introduce to interactions, which could make evaluations based on such simulations overly optimistic. We also observe variability in performance across different domains, which may indicate a need for domain-specific user simulators.
ECBD: Evidence-Centered Benchmark Design for NLP
Jun 13, 2024



Benchmarking is seen as critical to assessing progress in NLP. However, creating a benchmark involves many design decisions (e.g., which datasets to include, which metrics to use) that often rely on tacit, untested assumptions about what the benchmark is intended to measure or is actually measuring. There is currently no principled way of analyzing these decisions and how they impact the validity of the benchmark's measurements. To address this gap, we draw on evidence-centered design in educational assessments and propose Evidence-Centered Benchmark Design (ECBD), a framework which formalizes the benchmark design process into five modules. ECBD specifies the role each module plays in helping practitioners collect evidence about capabilities of interest. Specifically, each module requires benchmark designers to describe, justify, and support benchmark design choices -- e.g., clearly specifying the capabilities the benchmark aims to measure or how evidence about those capabilities is collected from model responses. To demonstrate the use of ECBD, we conduct case studies with three benchmarks: BoolQ, SuperGLUE, and HELM. Our analysis reveals common trends in benchmark design and documentation that could threaten the validity of benchmarks' measurements.
Responsible AI Considerations in Text Summarization Research: A Review of Current Practices
Nov 18, 2023



AI and NLP publication venues have increasingly encouraged researchers to reflect on possible ethical considerations, adverse impacts, and other responsible AI issues their work might engender. However, for specific NLP tasks our understanding of how prevalent such issues are, or when and why these issues are likely to arise, remains limited. Focusing on text summarization -- a common NLP task largely overlooked by the responsible AI community -- we examine research and reporting practices in the current literature. We conduct a multi-round qualitative analysis of 333 summarization papers from the ACL Anthology published between 2020-2022. We focus on how, which, and when responsible AI issues are covered, which relevant stakeholders are considered, and mismatches between stated and realized research goals. We also discuss current evaluation practices and consider how authors discuss the limitations of both prior work and their own work. Overall, we find that relatively few papers engage with possible stakeholders or contexts of use, which limits their consideration of potential downstream adverse impacts or other responsible AI issues. Based on our findings, we make recommendations on concrete practices and research directions.
Network Analysis of the iNaturalist Citizen Science Community
Oct 16, 2023



In recent years, citizen science has become a larger and larger part of the scientific community. Its ability to crowd source data and expertise from thousands of citizen scientists makes it invaluable. Despite the field's growing popularity, the interactions and structure of citizen science projects are still poorly understood and under analyzed. We use the iNaturalist citizen science platform as a case study to analyze the structure of citizen science projects. We frame the data from iNaturalist as a bipartite network and use visualizations as well as established network science techniques to gain insights into the structure and interactions between users in citizen science projects. Finally, we propose a novel unique benchmark for network science research by using the iNaturalist data to create a network which has an unusual structure relative to other common benchmark networks. We demonstrate using a link prediction task that this network can be used to gain novel insights into a variety of network science methods.
MaskEval: Weighted MLM-Based Evaluation for Text Summarization and Simplification
May 24, 2022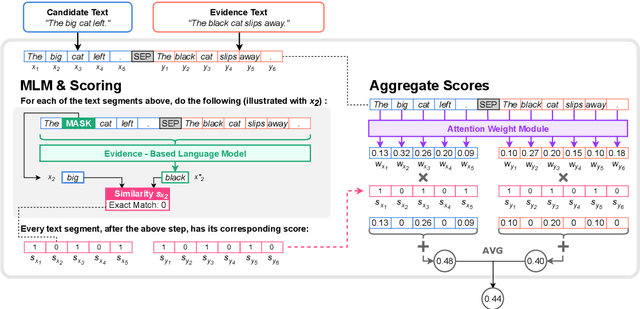
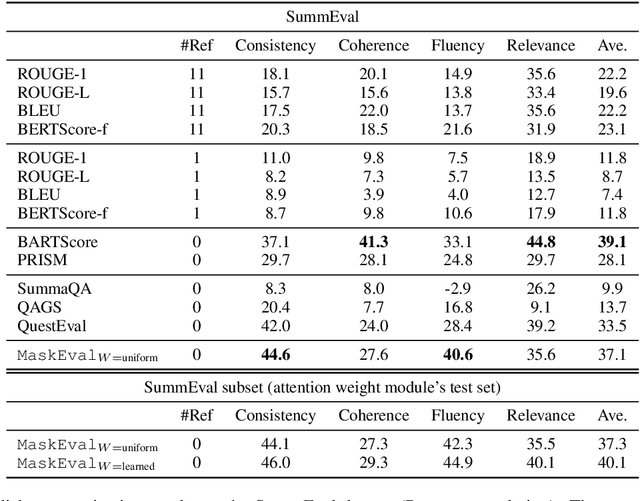
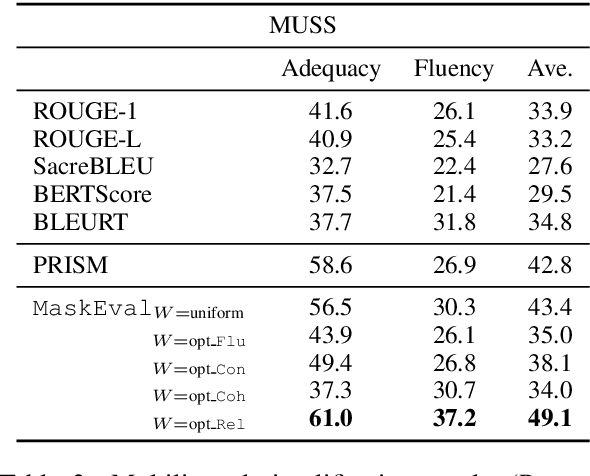
In text summarization and simplification, system outputs must be evaluated along multiple dimensions such as relevance, factual consistency, fluency, and grammaticality, and a wide range of possible outputs could be of high quality. These properties make the development of an adaptable, reference-less evaluation metric both necessary and challenging. We introduce MaskEval, a reference-less metric for text summarization and simplification that operates by performing masked language modeling (MLM) on the concatenation of the candidate and the source texts. It features an attention-like weighting mechanism to modulate the relative importance of each MLM step, which crucially allows MaskEval to be adapted to evaluate different quality dimensions. We demonstrate its effectiveness on English summarization and on multilingual text simplification in terms of correlations with human judgments.