 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergyLens: Predictive Energy-Aware Exploration for Multi-GPU LLM Inference Optimization
May 14, 2026We present EnergyLens, an end-to-end framework for energy-aware large language model (LLM) inference optimization. As LLMs scale, predicting and reducing their energy footprint has become critical for sustainability and datacenter operations, yet existing approaches either require production-level code and expensive profiling or fail to accurately capture multi-GPU energy behavior. As a result, practitioners lack tools for deciding which optimizations to prioritize and for selecting among existing deployment configurations when exhaustive profiling is impractical. EnergyLens addresses this gap with an intuitive einsum-based interface that captures LLM specifications including fusion, parallelism, and compute-communication overlap, combined with load-imbalance-aware MoE modeling and an empirically driven communication energy model for multi-GPU settings. We validate EnergyLens on Llama3 and Qwen3-MoE across tensor-parallel and expert-parallel configurations, achieving mean absolute percentage errors (MAPEs) between 9.25% and 13.19% for multi-GPU prefill and decode energy, and 12.97% across SM allocations for Megatron-style overlap. Our energy-driven exploration reveals up to 1.47x and 52.9x energy variation across configurations in prefill and decode efficiency and motivates distributed serving. We further show that compute-communication overlap is difficult to optimize with intuition alone, but EnergyLens correctly identifies Pareto-optimal overlap configurations.
Adaptive Block-Scaled Data Types
Mar 30, 2026NVFP4 has grown increasingly popular as a 4-bit format for quantizing large language models due to its hardware support and its ability to retain useful information with relatively few bits per parameter. However, the format is not without limitations: recent work has shown that NVFP4 suffers from its error distribution, resulting in large amounts of quantization error on near-maximal values in each group of 16 values. In this work, we leverage this insight to design new Adaptive Block-Scaled Data Types that can adapt to the distribution of their input values. For four-bit quantization, our proposed IF4 (Int/Float 4) data type selects between FP4 and INT4 representations for each group of 16 values, which are then scaled by an E4M3 scale factor as is done with NVFP4. The selected data type is denoted using the scale factor's sign bit, which is currently unused in NVFP4, and we apply the same insight to design formats for other bit-widths, including IF3 and IF6. When used to quantize language models, we find that IF4 outperforms existing 4-bit block-scaled formats, achieving lower loss during quantized training and achieving higher accuracy on many tasks in post-training quantization. We additionally design and evaluate an IF4 Multiply-Accumulate (MAC) unit to demonstrate that IF4 can be implemented efficiently in next-generation hardware accelerators. Our code is available at https://github.com/mit-han-lab/fouroversix.
Hardware Trojan Detection Using Unsupervised Deep Learning on Quantum Diamond Microscope Magnetic Field Images
Apr 29, 2022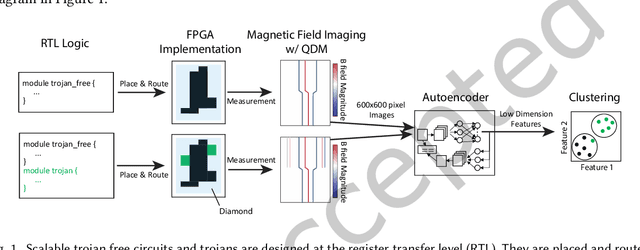

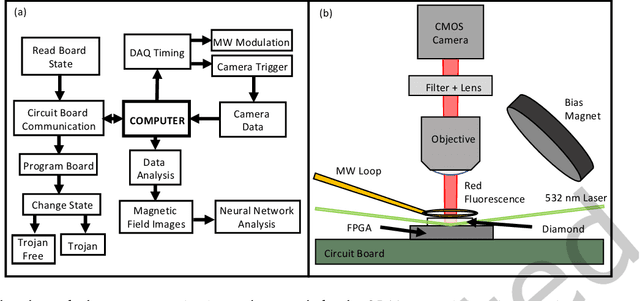
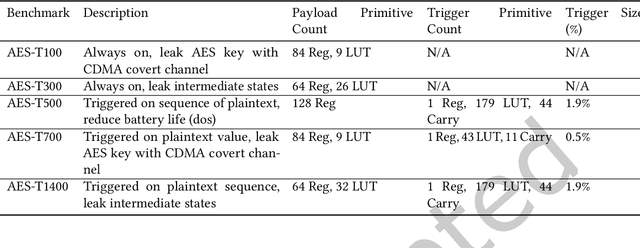
This paper presents a method for hardware trojan detection in integrated circuits. Unsupervised deep learning is used to classify wide field-of-view (4x4 mm$^2$), high spatial resolution magnetic field images taken using a Quantum Diamond Microscope (QDM). QDM magnetic imaging is enhanced using quantum control techniques and improved diamond material to increase magnetic field sensitivity by a factor of 4 and measurement speed by a factor of 16 over previous demonstrations. These upgrades facilitate the first demonstration of QDM magnetic field measurement for hardware trojan detection. Unsupervised convolutional neural networks and clustering are used to infer trojan presence from unlabeled data sets of 600x600 pixel magnetic field images without human bias. This analysis is shown to be more accurate than principal component analysis for distinguishing between field programmable gate arrays configured with trojan free and trojan inserted logic. This framework is tested on a set of scalable trojans that we developed and measured with the QDM. Scalable and TrustHub trojans are detectable down to a minimum trojan trigger size of 0.5% of the total logic. The trojan detection framework can be used for golden-chip free detection, since knowledge of the chips' identities is only used to evaluate detection accuracy
Leaky Nets: Recovering Embedded Neural Network Models and Inputs through Simple Power and Timing Side-Channels -- Attacks and Defenses
Mar 26, 2021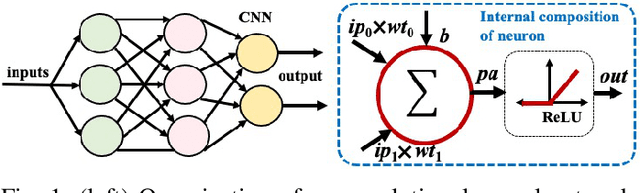
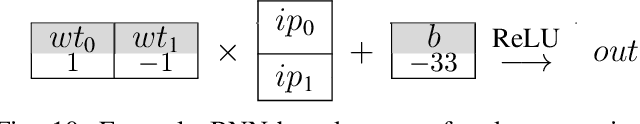
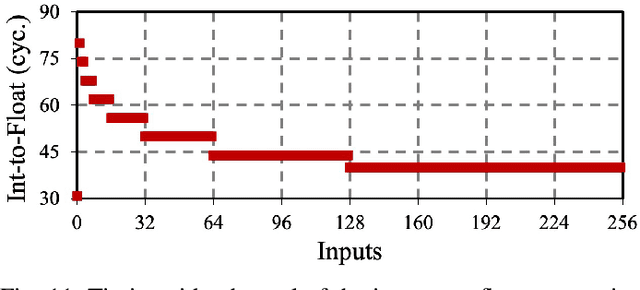
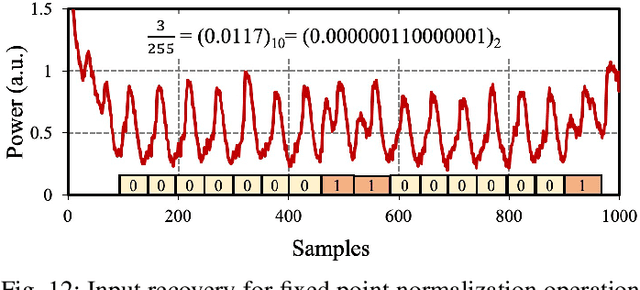
With the recent advancements in machine learning theory, many commercial embedded micro-processors use neural network models for a variety of signal processing applications. However, their associated side-channel security vulnerabilities pose a major concern. There have been several proof-of-concept attacks demonstrating the extraction of their model parameters and input data. But, many of these attacks involve specific assumptions, have limited applicability, or pose huge overheads to the attacker. In this work, we study the side-channel vulnerabilities of embedded neural network implementations by recovering their parameters using timing-based information leakage and simple power analysis side-channel attacks. We demonstrate our attacks on popular micro-controller platforms over networks of different precisions such as floating point, fixed point, binary networks. We are able to successfully recover not only the model parameters but also the inputs for the above networks. Countermeasures against timing-based attacks are implemented and their overheads are analyzed.
Rethinking Empirical Evaluation of Adversarial Robustness Using First-Order Attack Methods
Jun 01, 2020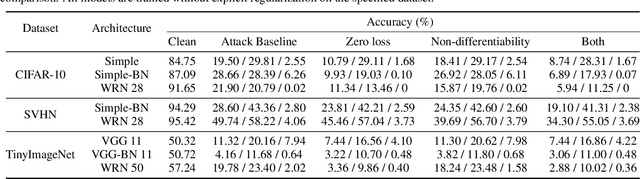
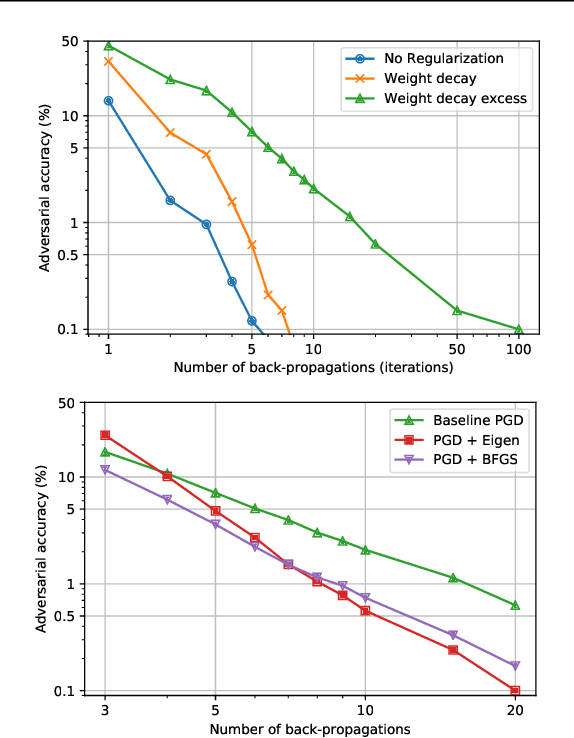
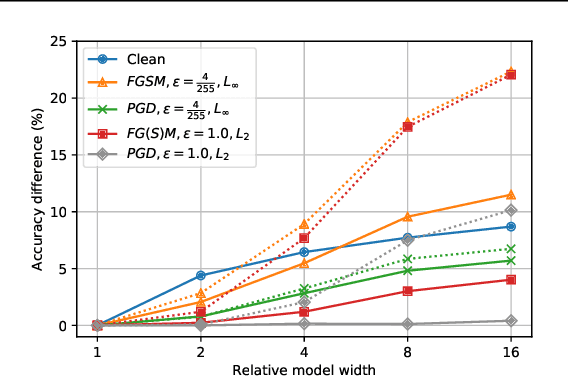
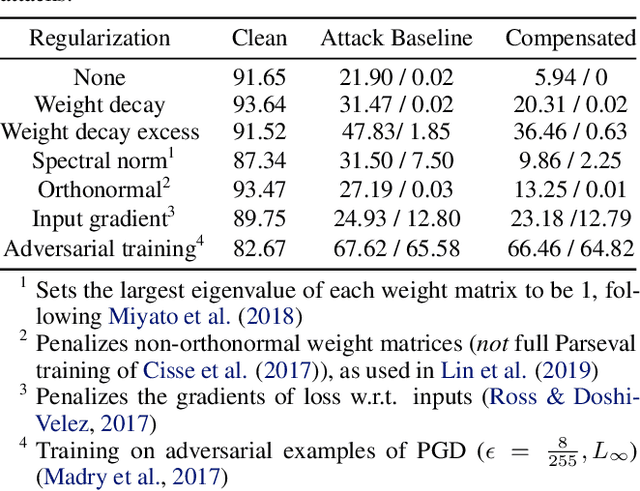
We identify three common cases that lead to overestimation of adversarial accuracy against bounded first-order attack methods, which is popularly used as a proxy for adversarial robustness in empirical studies. For each case, we propose compensation methods that either address sources of inaccurate gradient computation, such as numerical instability near zero and non-differentiability, or reduce the total number of back-propagations for iterative attacks by approximating second-order information. These compensation methods can be combined with existing attack methods for a more precise empirical evaluation metric. We illustrate the impact of these three cases with examples of practical interest, such as benchmarking model capacity and regularization techniques for robustness. Overall, our work shows that overestimated adversarial accuracy that is not indicative of robustness is prevalent even for conventionally trained deep neural networks, and highlights cautions of using empirical evaluation without guaranteed bounds.