 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Information Change in Science Communication with Semantically Matched Paraphrases
Oct 24, 2022



Whether the media faithfully communicate scientific information has long been a core issue to the science community. Automatically identifying paraphrased scientific findings could enable large-scale tracking and analysis of information changes in the science communication process, but this requires systems to understand the similarity between scientific information across multiple domains. To this end, we present the SCIENTIFIC PARAPHRASE AND INFORMATION CHANGE DATASET (SPICED), the first paraphrase dataset of scientific findings annotated for degree of information change. SPICED contains 6,000 scientific finding pairs extracted from news stories, social media discussions, and full texts of original papers. We demonstrate that SPICED poses a challenging task and that models trained on SPICED improve downstream performance on evidence retrieval for fact checking of real-world scientific claims. Finally, we show that models trained on SPICED can reveal large-scale trends in the degrees to which people and organizations faithfully communicate new scientific findings. Data, code, and pre-trained models are available at http://www.copenlu.com/publication/2022_emnlp_wright/.
Machine Reading, Fast and Slow: When Do Models "Understand" Language?
Sep 15, 2022
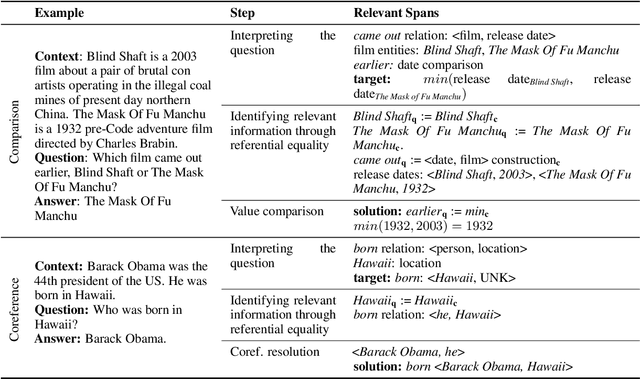
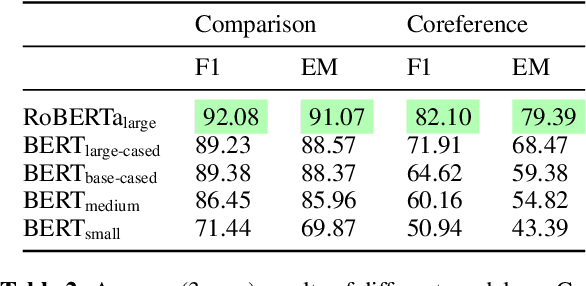

Two of the most fundamental challenges in Natural Language Understanding (NLU) at present are: (a) how to establish whether deep learning-based models score highly on NLU benchmarks for the 'right' reasons; and (b) to understand what those reasons would even be. We investigate the behavior of reading comprehension models with respect to two linguistic 'skills': coreference resolution and comparison. We propose a definition for the reasoning steps expected from a system that would be 'reading slowly', and compare that with the behavior of five models of the BERT family of various sizes, observed through saliency scores and counterfactual explanations. We find that for comparison (but not coreference) the systems based on larger encoders are more likely to rely on the 'right' information, but even they struggle with generalization, suggesting that they still learn specific lexical patterns rather than the general principles of comparison.
Counterfactually Augmented Data and Unintended Bias: The Case of Sexism and Hate Speech Detection
May 09, 2022
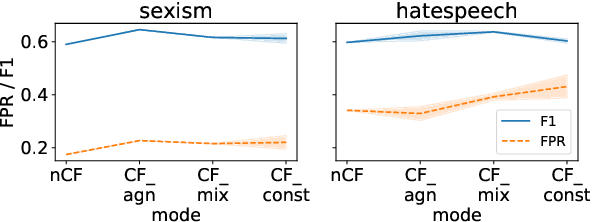
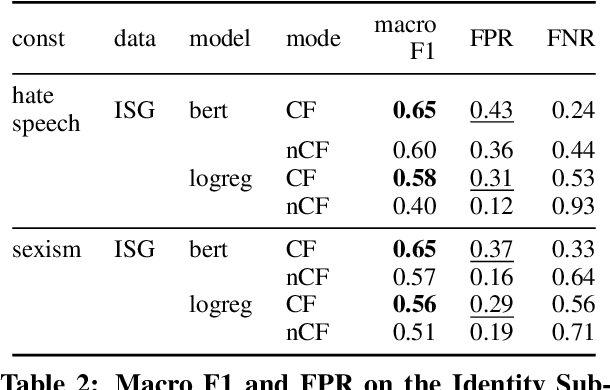
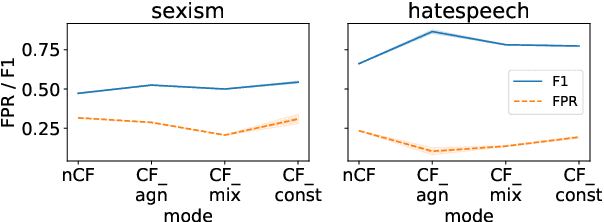
Counterfactually Augmented Data (CAD) aims to improve out-of-domain generalizability, an indicator of model robustness. The improvement is credited with promoting core features of the construct over spurious artifacts that happen to correlate with it. Yet, over-relying on core features may lead to unintended model bias. Especially, construct-driven CAD -- perturbations of core features -- may induce models to ignore the context in which core features are used. Here, we test models for sexism and hate speech detection on challenging data: non-hateful and non-sexist usage of identity and gendered terms. In these hard cases, models trained on CAD, especially construct-driven CAD, show higher false-positive rates than models trained on the original, unperturbed data. Using a diverse set of CAD -- construct-driven and construct-agnostic -- reduces such unintended bias.
Same Neurons, Different Languages: Probing Morphosyntax in Multilingual Pre-trained Models
May 08, 2022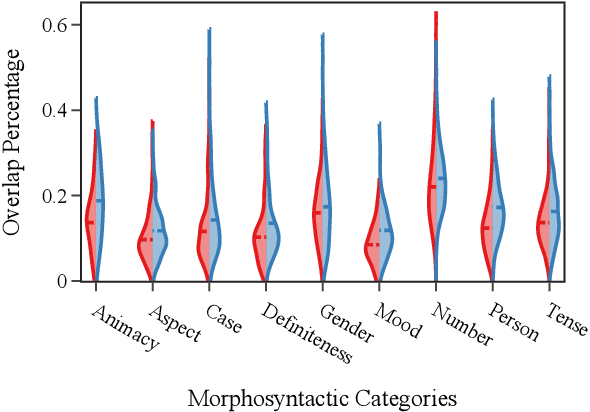
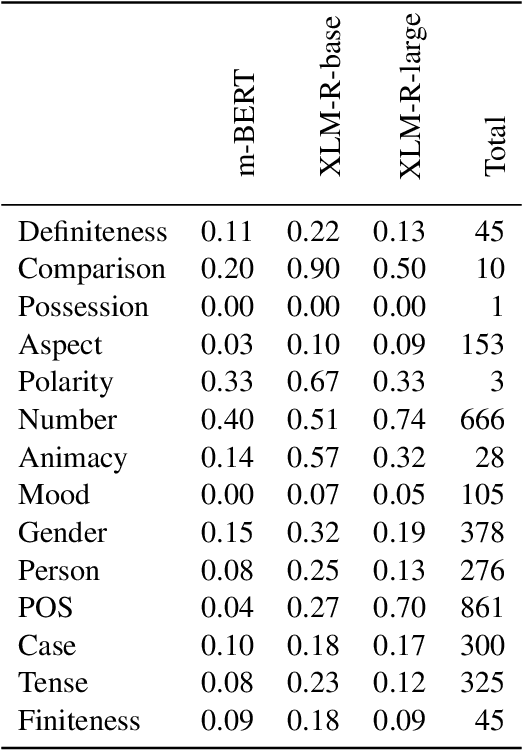
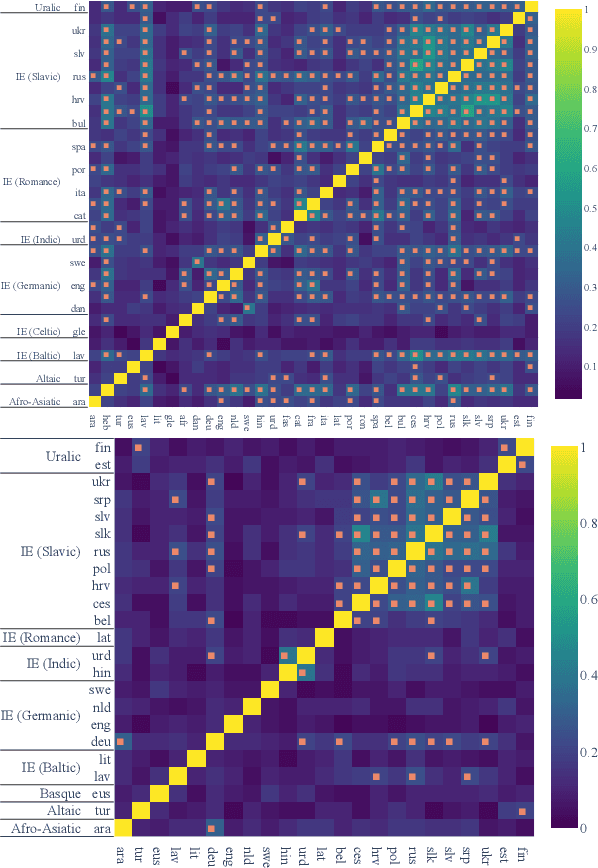
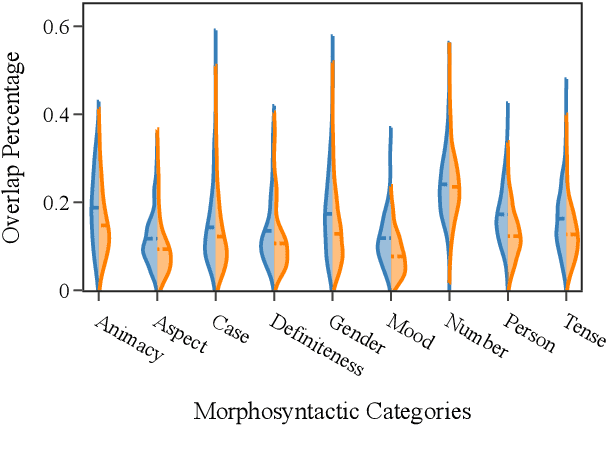
The success of multilingual pre-trained models is underpinned by their ability to learn representations shared by multiple languages even in absence of any explicit supervision. However, it remains unclear how these models learn to generalise across languages. In this work, we conjecture that multilingual pre-trained models can derive language-universal abstractions about grammar. In particular, we investigate whether morphosyntactic information is encoded in the same subset of neurons in different languages. We conduct the first large-scale empirical study over 43 languages and 14 morphosyntactic categories with a state-of-the-art neuron-level probe. Our findings show that the cross-lingual overlap between neurons is significant, but its extent may vary across categories and depends on language proximity and pre-training data size.
Fact Checking with Insufficient Evidence
Apr 05, 2022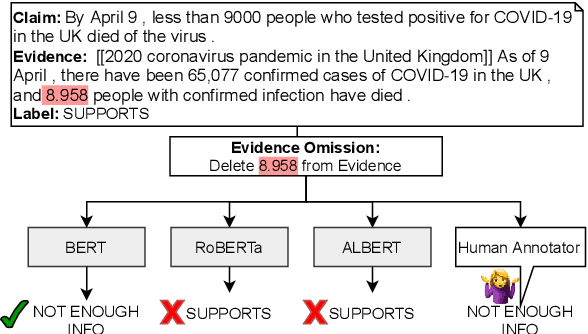



Automating the fact checking (FC) process relies on information obtained from external sources. In this work, we posit that it is crucial for FC models to make veracity predictions only when there is sufficient evidence and otherwise indicate when it is not enough. To this end, we are the first to study what information FC models consider sufficient by introducing a novel task and advancing it with three main contributions. First, we conduct an in-depth empirical analysis of the task with a new fluency-preserving method for omitting information from the evidence at the constituent and sentence level. We identify when models consider the remaining evidence (in)sufficient for FC, based on three trained models with different Transformer architectures and three FC datasets. Second, we ask annotators whether the omitted evidence was important for FC, resulting in a novel diagnostic dataset, SufficientFacts, for FC with omitted evidence. We find that models are least successful in detecting missing evidence when adverbial modifiers are omitted (21% accuracy), whereas it is easiest for omitted date modifiers (63% accuracy). Finally, we propose a novel data augmentation strategy for contrastive self-learning of missing evidence by employing the proposed omission method combined with tri-training. It improves performance for Evidence Sufficiency Prediction by up to 17.8 F1 score, which in turn improves FC performance by up to 2.6 F1 score.
Probing Pre-Trained Language Models for Cross-Cultural Differences in Values
Mar 25, 2022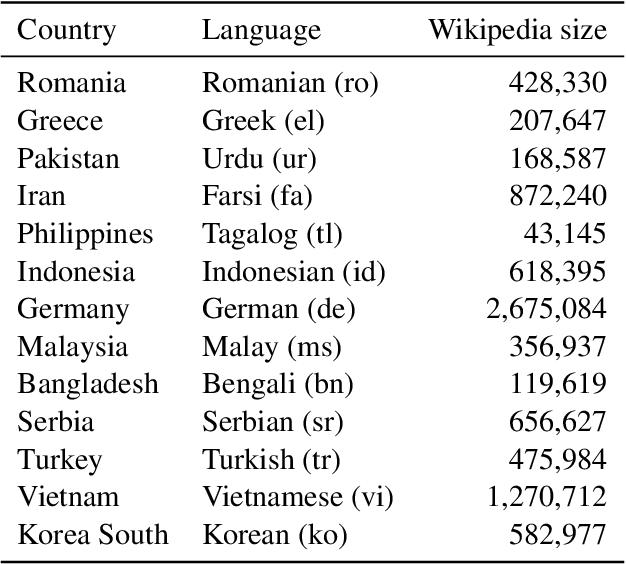
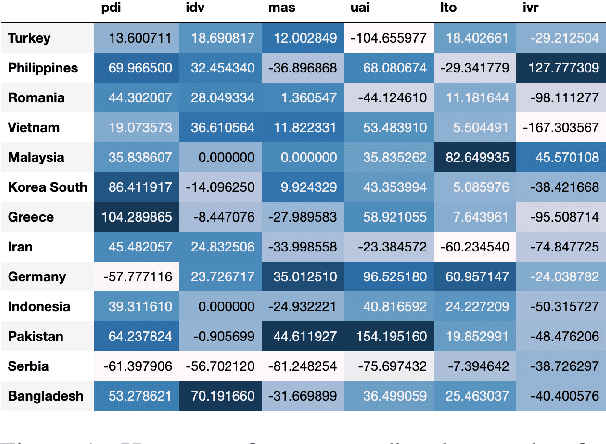
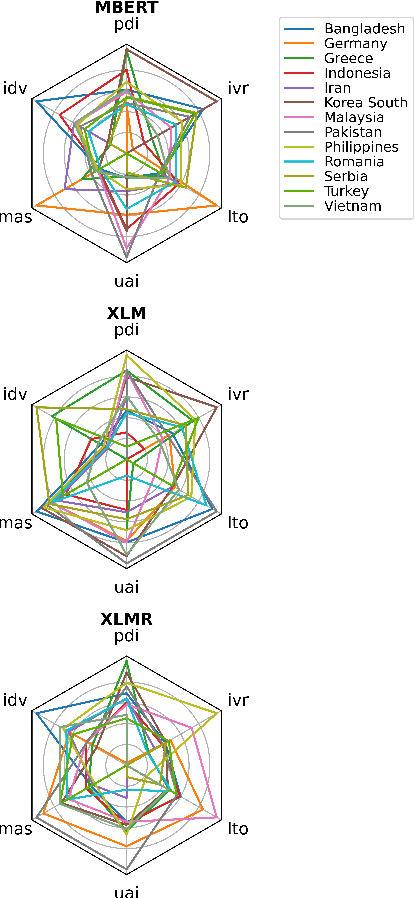
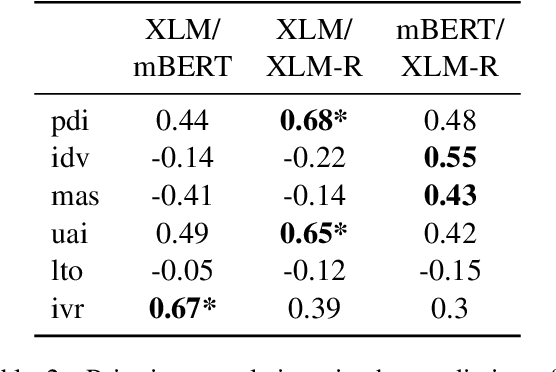
Language embeds information about social, cultural, and political values people hold. Prior work has explored social and potentially harmful biases encoded in Pre-Trained Language models (PTLMs). However, there has been no systematic study investigating how values embedded in these models vary across cultures. In this paper, we introduce probes to study which values across cultures are embedded in these models, and whether they align with existing theories and cross-cultural value surveys. We find that PTLMs capture differences in values across cultures, but those only weakly align with established value surveys. We discuss implications of using mis-aligned models in cross-cultural settings, as well as ways of aligning PTLMs with value surveys.
Generating Scientific Claims for Zero-Shot Scientific Fact Checking
Mar 24, 2022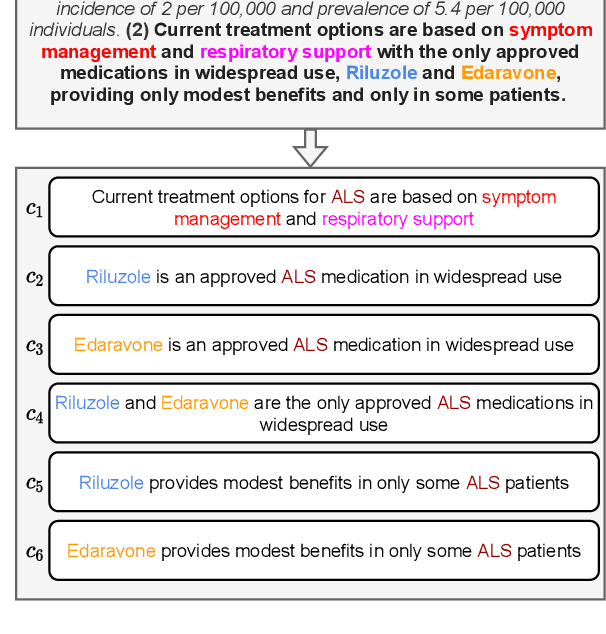
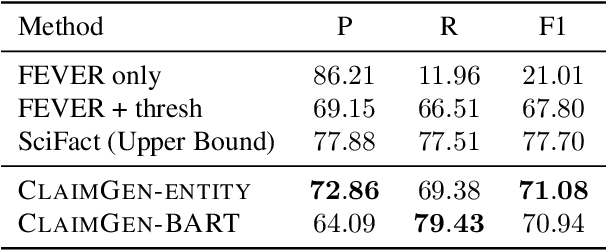
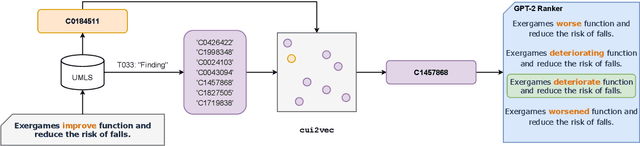

Automated scientific fact checking is difficult due to the complexity of scientific language and a lack of significant amounts of training data, as annotation requires domain expertise. To address this challenge, we propose scientific claim generation, the task of generating one or more atomic and verifiable claims from scientific sentences, and demonstrate its usefulness in zero-shot fact checking for biomedical claims. We propose CLAIMGEN-BART, a new supervised method for generating claims supported by the literature, as well as KBIN, a novel method for generating claim negations. Additionally, we adapt an existing unsupervised entity-centric method of claim generation to biomedical claims, which we call CLAIMGEN-ENTITY. Experiments on zero-shot fact checking demonstrate that both CLAIMGEN-ENTITY and CLAIMGEN-BART, coupled with KBIN, achieve up to 90% performance of fully supervised models trained on manually annotated claims and evidence. A rigorous evaluation study demonstrates significant improvement in generated claim and negation quality over existing baselines
Neighborhood Contrastive Learning for Scientific Document Representations with Citation Embeddings
Feb 14, 2022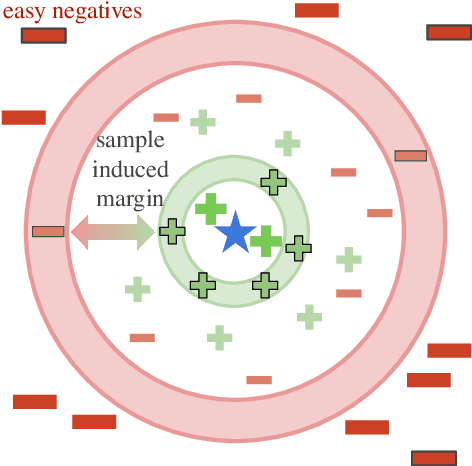
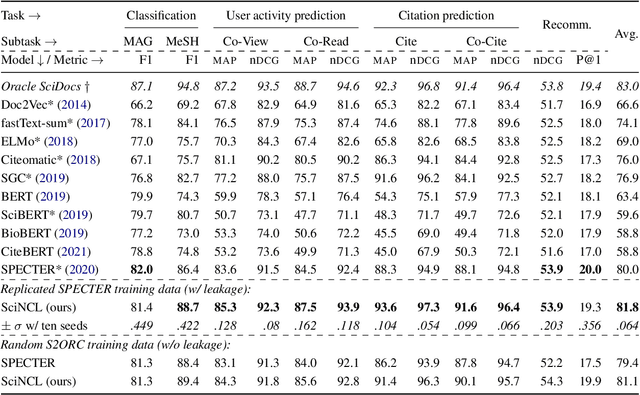
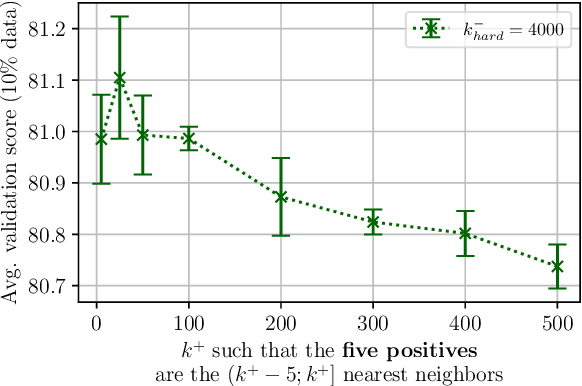
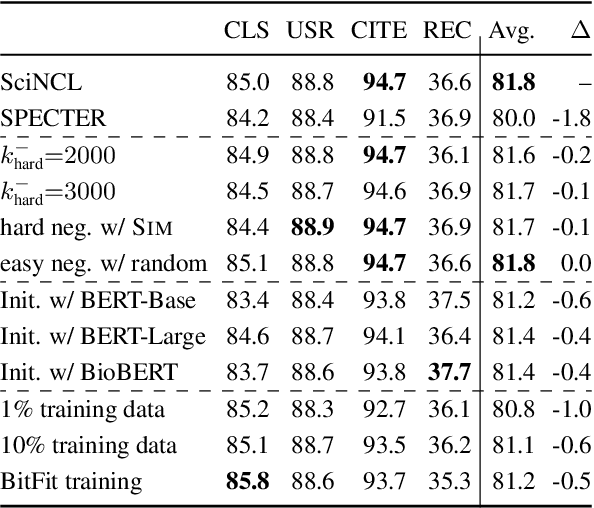
Learning scientific document representations can be substantially improved through contrastive learning objectives, where the challenge lies in creating positive and negative training samples that encode the desired similarity semantics. Prior work relies on discrete citation relations to generate contrast samples. However, discrete citations enforce a hard cut-off to similarity. This is counter-intuitive to similarity-based learning, and ignores that scientific papers can be very similar despite lacking a direct citation - a core problem of finding related research. Instead, we use controlled nearest neighbor sampling over citation graph embeddings for contrastive learning. This control allows us to learn continuous similarity, to sample hard-to-learn negatives and positives, and also to avoid collisions between negative and positive samples by controlling the sampling margin between them. The resulting method SciNCL outperforms the state-of-the-art on the SciDocs benchmark. Furthermore, we demonstrate that it can train (or tune) models sample-efficiently, and that it can be combined with recent training-efficient methods. Perhaps surprisingly, even training a general-domain language model this way outperforms baselines pretrained in-domain.
A Latent-Variable Model for Intrinsic Probing
Jan 20, 2022The success of pre-trained contextualized representations has prompted researchers to analyze them for the presence of linguistic information. Indeed, it is natural to assume that these pre-trained representations do encode some level of linguistic knowledge as they have brought about large empirical improvements on a wide variety of NLP tasks, which suggests they are learning true linguistic generalization. In this work, we focus on intrinsic probing, an analysis technique where the goal is not only to identify whether a representation encodes a linguistic attribute, but also to pinpoint where this attribute is encoded. We propose a novel latent-variable formulation for constructing intrinsic probes and derive a tractable variational approximation to the log-likelihood. Our results show that our model is versatile and yields tighter mutual information estimates than two intrinsic probes previously proposed in the literature. Finally, we find empirical evidence that pre-trained representations develop a cross-lingually entangled notion of morphosyntax.
A Survey on Gender Bias in Natural Language Processing
Dec 28, 2021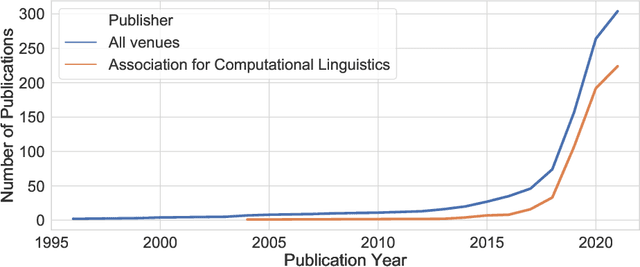
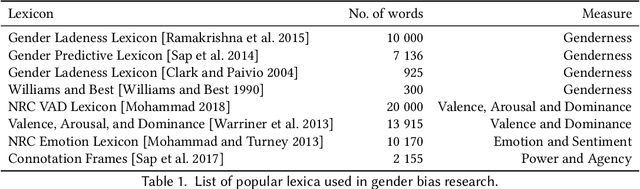


Language can be used as a means of reproducing and enforcing harmful stereotypes and biases and has been analysed as such in numerous research. In this paper, we present a survey of 304 papers on gender bias in natural language processing. We analyse definitions of gender and its categories within social sciences and connect them to formal definitions of gender bias in NLP research. We survey lexica and datasets applied in research on gender bias and then compare and contrast approaches to detecting and mitigating gender bias. We find that research on gender bias suffers from four core limitations. 1) Most research treats gender as a binary variable neglecting its fluidity and continuity. 2) Most of the work has been conducted in monolingual setups for English or other high-resource languages. 3) Despite a myriad of papers on gender bias in NLP methods, we find that most of the newly developed algorithms do not test their models for bias and disregard possible ethical considerations of their work. 4) Finally, methodologies developed in this line of research are fundamentally flawed covering very limited definitions of gender bias and lacking evaluation baselines and pipelines. We suggest recommendations towards overcoming these limitations as a guide for future research.