 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGTYP 2020 Shared Task: Prediction of Typological Features
Paper and Code
Oct 26, 2020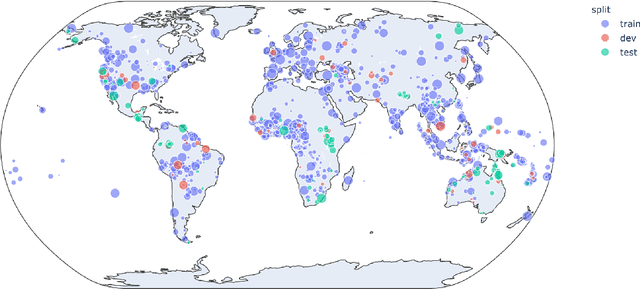

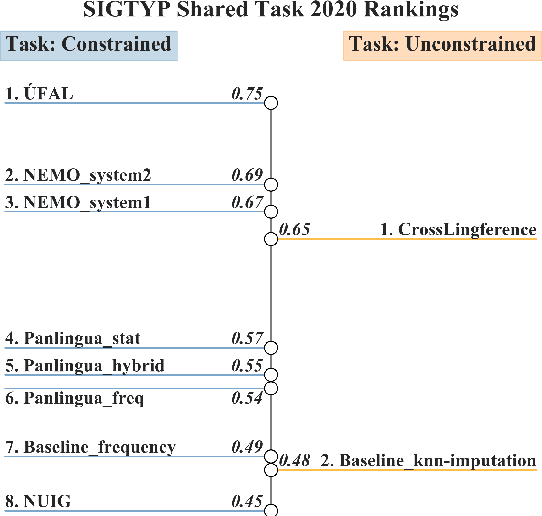
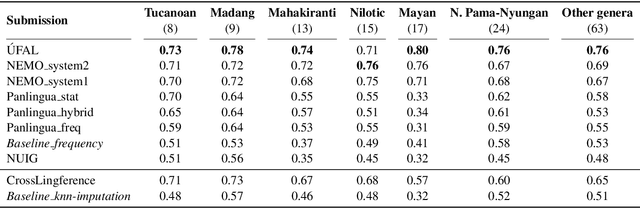
Typological knowledge bases (KBs) such as WALS (Dryer and Haspelmath, 2013) contain information about linguistic properties of the world's languages. They have been shown to be useful for downstream applications, including cross-lingual transfer learning and linguistic probing. A major drawback hampering broader adoption of typological KBs is that they are sparsely populated, in the sense that most languages only have annotations for some features, and skewed, in that few features have wide coverage. As typological features often correlate with one another, it is possible to predict them and thus automatically populate typological KBs, which is also the focus of this shared task. Overall, the task attracted 8 submissions from 5 teams, out of which the most successful methods make use of such feature correlations. However, our error analysis reveals that even the strongest submitted systems struggle with predicting feature values for languages where few features are known.