 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartAttack: Testing the Vulnerability of LLMs to Malicious Prompting in Chart Generation
Jan 19, 2026Multimodal large language models (MLLMs) are increasingly used to automate chart generation from data tables, enabling efficient data analysis and reporting but also introducing new misuse risks. In this work, we introduce ChartAttack, a novel framework for evaluating how MLLMs can be misused to generate misleading charts at scale. ChartAttack injects misleaders into chart designs, aiming to induce incorrect interpretations of the underlying data. Furthermore, we create AttackViz, a chart question-answering (QA) dataset where each (chart specification, QA) pair is labeled with effective misleaders and their induced incorrect answers. Experiments in in-domain and cross-domain settings show that ChartAttack significantly degrades the QA performance of MLLM readers, reducing accuracy by an average of 19.6 points and 14.9 points, respectively. A human study further shows an average 20.2 point drop in accuracy for participants exposed to misleading charts generated by ChartAttack. Our findings highlight an urgent need for robustness and security considerations in the design, evaluation, and deployment of MLLM-based chart generation systems. We make our code and data publicly available.
Aletheia: What Makes RLVR For Code Verifiers Tick?
Jan 17, 2026Multi-domain thinking verifiers trained via Reinforcement Learning from Verifiable Rewards (RLVR) are a prominent fixture of the Large Language Model (LLM) post-training pipeline, owing to their ability to robustly rate and rerank model outputs. However, the adoption of such verifiers towards code generation has been comparatively sparse, with execution feedback constituting the dominant signal. Nonetheless, code verifiers remain valuable toward judging model outputs in scenarios where execution feedback is hard to obtain and are a potentially powerful addition to the code generation post-training toolbox. To this end, we create and open-source Aletheia, a controlled testbed that enables execution-grounded evaluation of code verifiers' robustness across disparate policy models and covariate shifts. We examine components of the RLVR-based verifier training recipe widely credited for its success: (1) intermediate thinking traces, (2) learning from negative samples, and (3) on-policy training. While experiments show the optimality of RLVR, we uncover important opportunities to simplify the recipe. Particularly, despite code verification exhibiting positive training- and inference-time scaling, on-policy learning stands out as the key component at small verifier sizes, and thinking-based training emerges as the most important component at larger scales.
Reward Modeling for Scientific Writing Evaluation
Jan 16, 2026Scientific writing is an expert-domain task that demands deep domain knowledge, task-specific requirements and reasoning capabilities that leverage the domain knowledge to satisfy the task specifications. While scientific text generation has been widely studied, its evaluation remains a challenging and open problem. It is critical to develop models that can be reliably deployed for evaluating diverse open-ended scientific writing tasks while adhering to their distinct requirements. However, existing LLM-based judges and reward models are primarily optimized for general-purpose benchmarks with fixed scoring rubrics and evaluation criteria. Consequently, they often fail to reason over sparse knowledge of scientific domains when interpreting task-dependent and multi-faceted criteria. Moreover, fine-tuning for each individual task is costly and impractical for low-resource settings. To bridge these gaps, we propose cost-efficient, open-source reward models tailored for scientific writing evaluation. We introduce a two-stage training framework that initially optimizes scientific evaluation preferences and then refines reasoning capabilities. Our multi-aspect evaluation design and joint training across diverse tasks enable fine-grained assessment and robustness to dynamic criteria and scoring rubrics. Experimental analysis shows that our training regime strongly improves LLM-based scientific writing evaluation. Our models generalize effectively across tasks and to previously unseen scientific writing evaluation settings, allowing a single trained evaluator to be reused without task-specific retraining.
Exposía: Academic Writing Assessment of Exposés and Peer Feedback
Jan 10, 2026We present Exposía, the first public dataset that connects writing and feedback assessment in higher education, enabling research on educationally grounded approaches to academic writing evaluation. Exposía includes student research project proposals and peer and instructor feedback consisting of comments and free-text reviews. The dataset was collected in the "Introduction to Scientific Work" course of the Computer Science undergraduate program that focuses on teaching academic writing skills and providing peer feedback on academic writing. Exposía reflects the multi-stage nature of the academic writing process that includes drafting, providing and receiving feedback, and revising the writing based on the feedback received. Both the project proposals and peer feedback are accompanied by human assessment scores based on a fine-grained, pedagogically-grounded schema for writing and feedback assessment that we develop. We use Exposía to benchmark state-of-the-art open-source large language models (LLMs) for two tasks: automated scoring of (1) the proposals and (2) the student reviews. The strongest LLMs attain high agreement on scoring aspects that require little domain knowledge but degrade on dimensions evaluating content, in line with human agreement values. We find that LLMs align better with the human instructors giving high scores. Finally, we establish that a prompting strategy that scores multiple aspects of the writing together is the most effective, an important finding for classroom deployment.
MAGneT: Coordinated Multi-Agent Generation of Synthetic Multi-Turn Mental Health Counseling Sessions
Sep 04, 2025The growing demand for scalable psychological counseling highlights the need for fine-tuning open-source Large Language Models (LLMs) with high-quality, privacy-compliant data, yet such data remains scarce. Here we introduce MAGneT, a novel multi-agent framework for synthetic psychological counseling session generation that decomposes counselor response generation into coordinated sub-tasks handled by specialized LLM agents, each modeling a key psychological technique. Unlike prior single-agent approaches, MAGneT better captures the structure and nuance of real counseling. In addition, we address inconsistencies in prior evaluation protocols by proposing a unified evaluation framework integrating diverse automatic and expert metrics. Furthermore, we expand the expert evaluations from four aspects of counseling in previous works to nine aspects, enabling a more thorough and robust assessment of data quality. Empirical results show that MAGneT significantly outperforms existing methods in quality, diversity, and therapeutic alignment of the generated counseling sessions, improving general counseling skills by 3.2% and CBT-specific skills by 4.3% on average on cognitive therapy rating scale (CTRS). Crucially, experts prefer MAGneT-generated sessions in 77.2% of cases on average across all aspects. Moreover, fine-tuning an open-source model on MAGneT-generated sessions shows better performance, with improvements of 6.3% on general counseling skills and 7.3% on CBT-specific skills on average on CTRS over those fine-tuned with sessions generated by baseline methods. We also make our code and data public.
Is this chart lying to me? Automating the detection of misleading visualizations
Aug 29, 2025Misleading visualizations are a potent driver of misinformation on social media and the web. By violating chart design principles, they distort data and lead readers to draw inaccurate conclusions. Prior work has shown that both humans and multimodal large language models (MLLMs) are frequently deceived by such visualizations. Automatically detecting misleading visualizations and identifying the specific design rules they violate could help protect readers and reduce the spread of misinformation. However, the training and evaluation of AI models has been limited by the absence of large, diverse, and openly available datasets. In this work, we introduce Misviz, a benchmark of 2,604 real-world visualizations annotated with 12 types of misleaders. To support model training, we also release Misviz-synth, a synthetic dataset of 81,814 visualizations generated using Matplotlib and based on real-world data tables. We perform a comprehensive evaluation on both datasets using state-of-the-art MLLMs, rule-based systems, and fine-tuned classifiers. Our results reveal that the task remains highly challenging. We release Misviz, Misviz-synth, and the accompanying code.
How Quantization Shapes Bias in Large Language Models
Aug 25, 2025
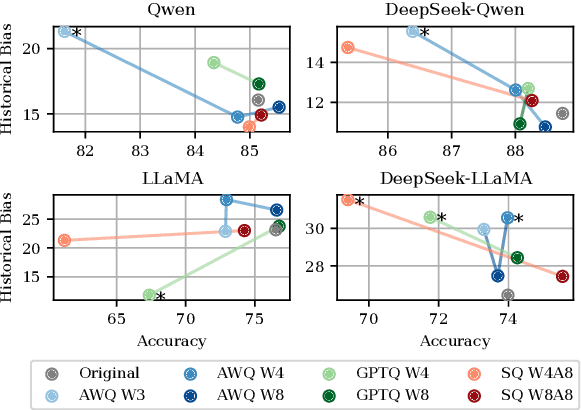
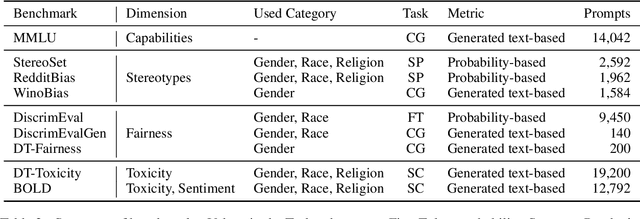
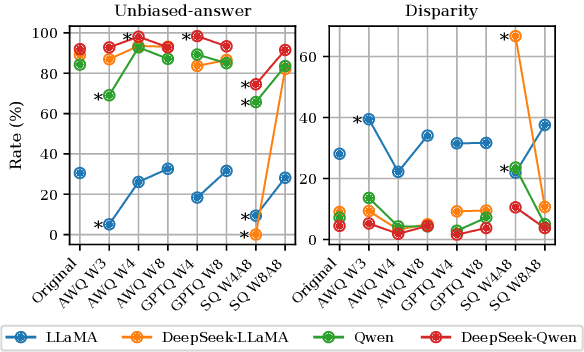
This work presents a comprehensive evaluation of how quantization affects model bias, with particular attention to its impact on individual demographic subgroups. We focus on weight and activation quantization strategies and examine their effects across a broad range of bias types, including stereotypes, toxicity, sentiment, and fairness. We employ both probabilistic and generated text-based metrics across nine benchmarks and evaluate models varying in architecture family and reasoning ability. Our findings show that quantization has a nuanced impact on bias: while it can reduce model toxicity and does not significantly impact sentiment, it tends to slightly increase stereotypes and unfairness in generative tasks, especially under aggressive compression. These trends are generally consistent across demographic categories and model types, although their magnitude depends on the specific setting. Overall, our results highlight the importance of carefully balancing efficiency and ethical considerations when applying quantization in practice.
Tailored Emotional LLM-Supporter: Enhancing Cultural Sensitivity
Aug 11, 2025Large language models (LLMs) show promise in offering emotional support and generating empathetic responses for individuals in distress, but their ability to deliver culturally sensitive support remains underexplored due to lack of resources. In this work, we introduce CultureCare, the first dataset designed for this task, spanning four cultures and including 1729 distress messages, 1523 cultural signals, and 1041 support strategies with fine-grained emotional and cultural annotations. Leveraging CultureCare, we (i) develop and test four adaptation strategies for guiding three state-of-the-art LLMs toward culturally sensitive responses; (ii) conduct comprehensive evaluations using LLM judges, in-culture human annotators, and clinical psychologists; (iii) show that adapted LLMs outperform anonymous online peer responses, and that simple cultural role-play is insufficient for cultural sensitivity; and (iv) explore the application of LLMs in clinical training, where experts highlight their potential in fostering cultural competence in future therapists.
Expert Preference-based Evaluation of Automated Related Work Generation
Aug 11, 2025Expert domain writing, such as scientific writing, typically demands extensive domain knowledge. Recent advances in LLMs show promising potential in reducing the expert workload. However, evaluating the quality of automatically generated scientific writing is a crucial open issue, as it requires knowledge of domain-specific evaluation criteria and the ability to discern expert preferences. Conventional automatic metrics and LLM-as-a-judge systems are insufficient to grasp expert preferences and domain-specific quality standards. To address this gap and support human-AI collaborative writing, we focus on related work generation, one of the most challenging scientific tasks, as an exemplar. We propose GREP, a multi-turn evaluation framework that integrates classical related work evaluation criteria with expert-specific preferences. Instead of assigning a single score, our framework decomposes the evaluation into fine-grained dimensions. This localized evaluation approach is further augmented with contrastive few-shot examples to provide detailed contextual guidance for the evaluation dimensions. The design principles allow our framework to deliver cardinal assessment of quality, which can facilitate better post-training compared to ordinal preference data. For better accessibility, we design two variants of GREP: a more precise variant with proprietary LLMs as evaluators, and a cheaper alternative with open-weight LLMs. Empirical investigation reveals that our framework is able to assess the quality of related work sections in a much more robust manner compared to standard LLM judges, reflects natural scenarios of scientific writing, and bears a strong correlation with the human expert assessment. We also observe that generations from state-of-the-art LLMs struggle to satisfy validation constraints of a suitable related work section. They (mostly) fail to improve based on feedback as well.
Decision-Making with Deliberation: Meta-reviewing as a Document-grounded Dialogue
Aug 07, 2025Meta-reviewing is a pivotal stage in the peer-review process, serving as the final step in determining whether a paper is recommended for acceptance. Prior research on meta-reviewing has treated this as a summarization problem over review reports. However, complementary to this perspective, meta-reviewing is a decision-making process that requires weighing reviewer arguments and placing them within a broader context. Prior research has demonstrated that decision-makers can be effectively assisted in such scenarios via dialogue agents. In line with this framing, we explore the practical challenges for realizing dialog agents that can effectively assist meta-reviewers. Concretely, we first address the issue of data scarcity for training dialogue agents by generating synthetic data using Large Language Models (LLMs) based on a self-refinement strategy to improve the relevance of these dialogues to expert domains. Our experiments demonstrate that this method produces higher-quality synthetic data and can serve as a valuable resource towards training meta-reviewing assistants. Subsequently, we utilize this data to train dialogue agents tailored for meta-reviewing and find that these agents outperform \emph{off-the-shelf} LLM-based assistants for this task. Finally, we apply our agents in real-world meta-reviewing scenarios and confirm their effectiveness in enhancing the efficiency of meta-reviewing.\footnote{Code and Data: https://github.com/UKPLab/arxiv2025-meta-review-as-dialog