 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPaR.txt, a cheap Shallow Parsing approach for Regulatory texts
Oct 04, 2021
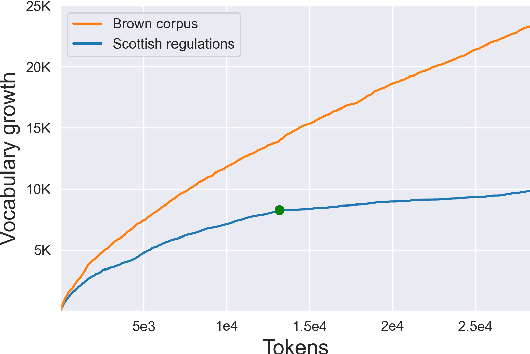
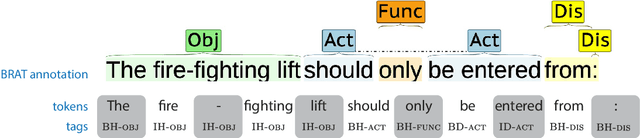

Automated Compliance Checking (ACC) systems aim to semantically parse building regulations to a set of rules. However, semantic parsing is known to be hard and requires large amounts of training data. The complexity of creating such training data has led to research that focuses on small sub-tasks, such as shallow parsing or the extraction of a limited subset of rules. This study introduces a shallow parsing task for which training data is relatively cheap to create, with the aim of learning a lexicon for ACC. We annotate a small domain-specific dataset of 200 sentences, SPaR.txt, and train a sequence tagger that achieves 79,93 F1-score on the test set. We then show through manual evaluation that the model identifies most (89,84%) defined terms in a set of building regulation documents, and that both contiguous and discontiguous Multi-Word Expressions (MWE) are discovered with reasonable accuracy (70,3%).
MiRANews: Dataset and Benchmarks for Multi-Resource-Assisted News Summarization
Sep 22, 2021
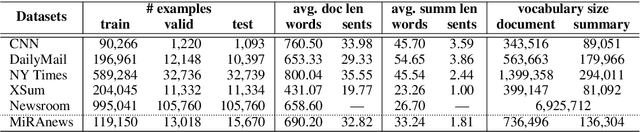
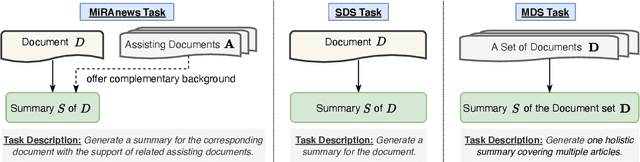
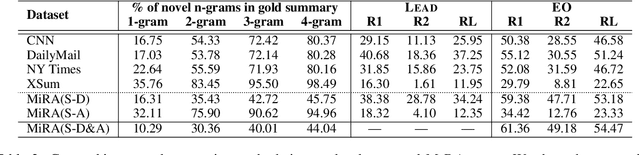
One of the most challenging aspects of current single-document news summarization is that the summary often contains 'extrinsic hallucinations', i.e., facts that are not present in the source document, which are often derived via world knowledge. This causes summarization systems to act more like open-ended language models tending to hallucinate facts that are erroneous. In this paper, we mitigate this problem with the help of multiple supplementary resource documents assisting the task. We present a new dataset MiRANews and benchmark existing summarization models. In contrast to multi-document summarization, which addresses multiple events from several source documents, we still aim at generating a summary for a single document. We show via data analysis that it's not only the models which are to blame: more than 27% of facts mentioned in the gold summaries of MiRANews are better grounded on assisting documents than in the main source articles. An error analysis of generated summaries from pretrained models fine-tuned on MiRANews reveals that this has an even bigger effects on models: assisted summarization reduces 55% of hallucinations when compared to single-document summarization models trained on the main article only. Our code and data are available at https://github.com/XinnuoXu/MiRANews.
AGGGEN: Ordering and Aggregating while Generating
Jun 17, 2021We present AGGGEN (pronounced 'again'), a data-to-text model which re-introduces two explicit sentence planning stages into neural data-to-text systems: input ordering and input aggregation. In contrast to previous work using sentence planning, our model is still end-to-end: AGGGEN performs sentence planning at the same time as generating text by learning latent alignments (via semantic facts) between input representation and target text. Experiments on the WebNLG and E2E challenge data show that by using fact-based alignments our approach is more interpretable, expressive, robust to noise, and easier to control, while retaining the advantages of end-to-end systems in terms of fluency. Our code is available at https://github.com/XinnuoXu/AggGen.
* Correct the first citation in the Zero-shot Few-shot scenarios paragraph in Section 7
OTTers: One-turn Topic Transitions for Open-Domain Dialogue
May 28, 2021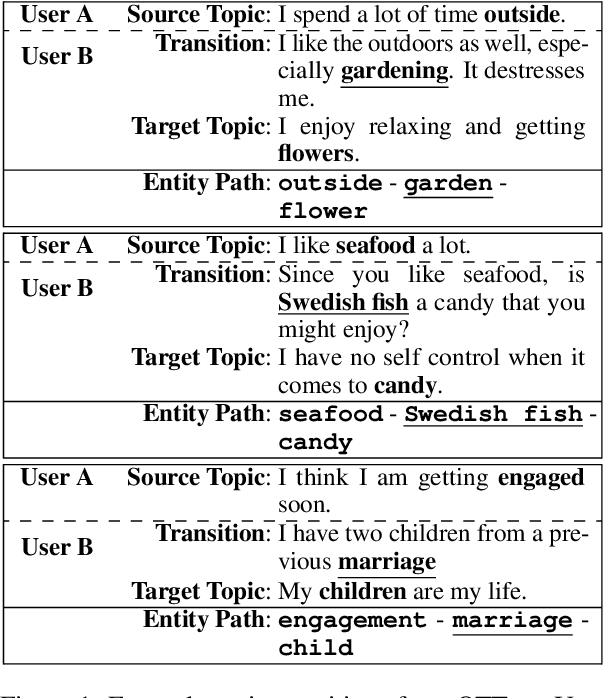


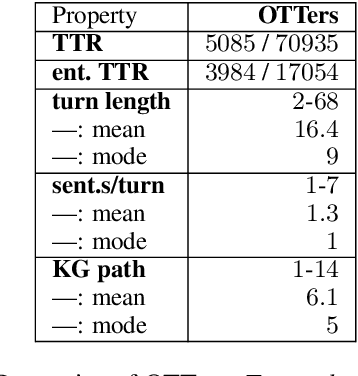
Mixed initiative in open-domain dialogue requires a system to pro-actively introduce new topics. The one-turn topic transition task explores how a system connects two topics in a cooperative and coherent manner. The goal of the task is to generate a "bridging" utterance connecting the new topic to the topic of the previous conversation turn. We are especially interested in commonsense explanations of how a new topic relates to what has been mentioned before. We first collect a new dataset of human one-turn topic transitions, which we call OTTers. We then explore different strategies used by humans when asked to complete such a task, and notice that the use of a bridging utterance to connect the two topics is the approach used the most. We finally show how existing state-of-the-art text generation models can be adapted to this task and examine the performance of these baselines on different splits of the OTTers data.
An Empirical Study on the Generalization Power of Neural Representations Learned via Visual Guessing Games
Jan 31, 2021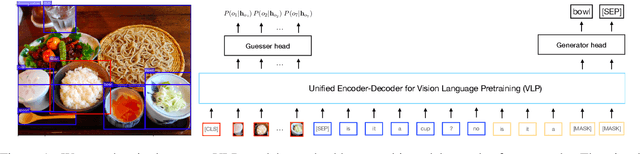
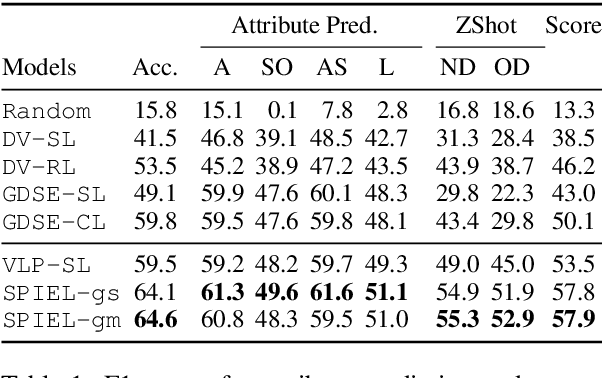


Guessing games are a prototypical instance of the "learning by interacting" paradigm. This work investigates how well an artificial agent can benefit from playing guessing games when later asked to perform on novel NLP downstream tasks such as Visual Question Answering (VQA). We propose two ways to exploit playing guessing games: 1) a supervised learning scenario in which the agent learns to mimic successful guessing games and 2) a novel way for an agent to play by itself, called Self-play via Iterated Experience Learning (SPIEL). We evaluate the ability of both procedures to generalize: an in-domain evaluation shows an increased accuracy (+7.79) compared with competitors on the evaluation suite CompGuessWhat?!; a transfer evaluation shows improved performance for VQA on the TDIUC dataset in terms of harmonic average accuracy (+5.31) thanks to more fine-grained object representations learned via SPIEL.
Imagining Grounded Conceptual Representations from Perceptual Information in Situated Guessing Games
Nov 05, 2020
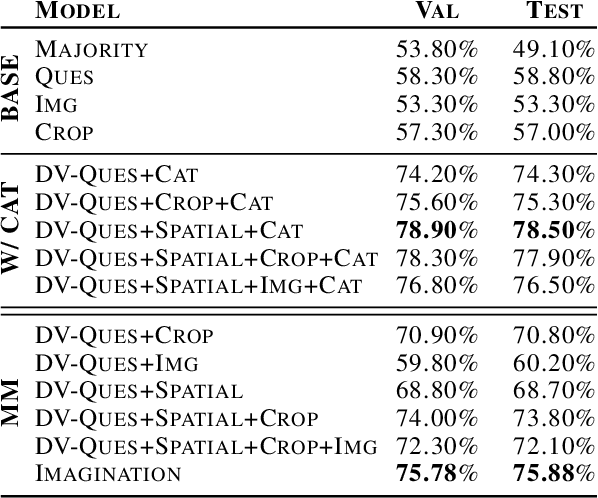
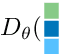

In visual guessing games, a Guesser has to identify a target object in a scene by asking questions to an Oracle. An effective strategy for the players is to learn conceptual representations of objects that are both discriminative and expressive enough to ask questions and guess correctly. However, as shown by Suglia et al. (2020), existing models fail to learn truly multi-modal representations, relying instead on gold category labels for objects in the scene both at training and inference time. This provides an unnatural performance advantage when categories at inference time match those at training time, and it causes models to fail in more realistic "zero-shot" scenarios where out-of-domain object categories are involved. To overcome this issue, we introduce a novel "imagination" module based on Regularized Auto-Encoders, that learns context-aware and category-aware latent embeddings without relying on category labels at inference time. Our imagination module outperforms state-of-the-art competitors by 8.26% gameplay accuracy in the CompGuessWhat?! zero-shot scenario (Suglia et al., 2020), and it improves the Oracle and Guesser accuracy by 2.08% and 12.86% in the GuessWhat?! benchmark, when no gold categories are available at inference time. The imagination module also boosts reasoning about object properties and attributes.
CompGuessWhat?!: A Multi-task Evaluation Framework for Grounded Language Learning
Jun 03, 2020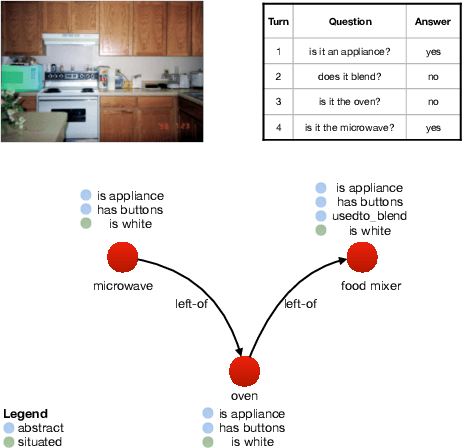
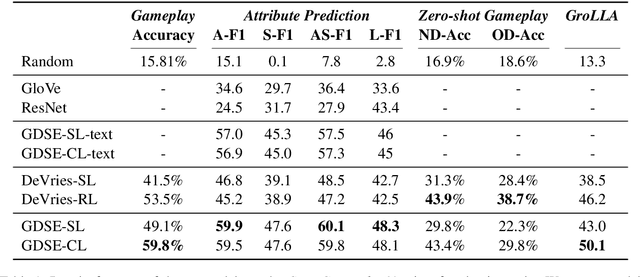


Approaches to Grounded Language Learning typically focus on a single task-based final performance measure that may not depend on desirable properties of the learned hidden representations, such as their ability to predict salient attributes or to generalise to unseen situations. To remedy this, we present GROLLA, an evaluation framework for Grounded Language Learning with Attributes with three sub-tasks: 1) Goal-oriented evaluation; 2) Object attribute prediction evaluation; and 3) Zero-shot evaluation. We also propose a new dataset CompGuessWhat?! as an instance of this framework for evaluating the quality of learned neural representations, in particular concerning attribute grounding. To this end, we extend the original GuessWhat?! dataset by including a semantic layer on top of the perceptual one. Specifically, we enrich the VisualGenome scene graphs associated with the GuessWhat?! images with abstract and situated attributes. By using diagnostic classifiers, we show that current models learn representations that are not expressive enough to encode object attributes (average F1 of 44.27). In addition, they do not learn strategies nor representations that are robust enough to perform well when novel scenes or objects are involved in gameplay (zero-shot best accuracy 50.06%).
In Layman's Terms: Semi-Open Relation Extraction from Scientific Texts
May 26, 2020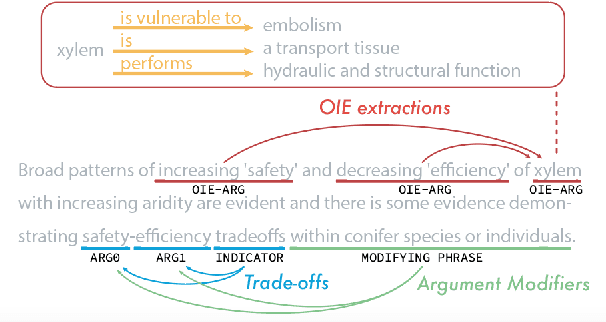

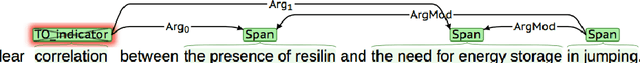
Information Extraction (IE) from scientific texts can be used to guide readers to the central information in scientific documents. But narrow IE systems extract only a fraction of the information captured, and Open IE systems do not perform well on the long and complex sentences encountered in scientific texts. In this work we combine the output of both types of systems to achieve Semi-Open Relation Extraction, a new task that we explore in the Biology domain. First, we present the Focused Open Biological Information Extraction (FOBIE) dataset and use FOBIE to train a state-of-the-art narrow scientific IE system to extract trade-off relations and arguments that are central to biology texts. We then run both the narrow IE system and a state-of-the-art Open IE system on a corpus of 10k open-access scientific biological texts. We show that a significant amount (65%) of erroneous and uninformative Open IE extractions can be filtered using narrow IE extractions. Furthermore, we show that the retained extractions are significantly more often informative to a reader.
A Scientific Information Extraction Dataset for Nature Inspired Engineering
May 26, 2020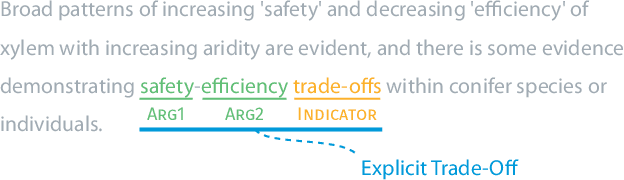
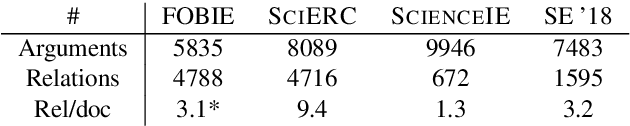

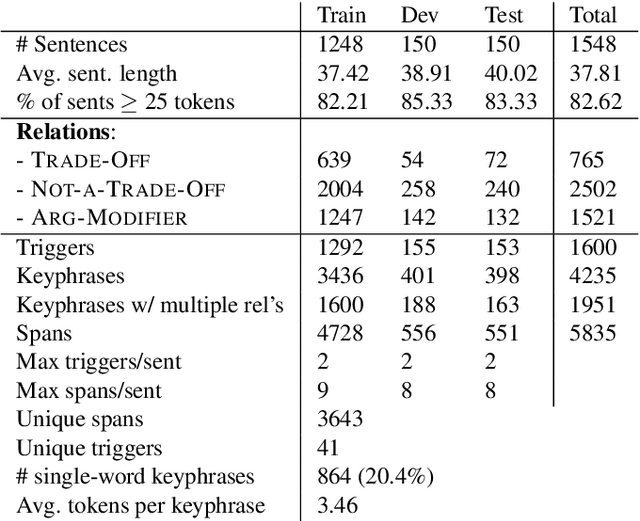
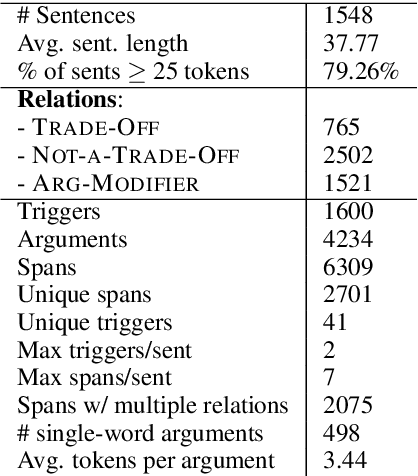
Nature has inspired various ground-breaking technological developments in applications ranging from robotics to aerospace engineering and the manufacturing of medical devices. However, accessing the information captured in scientific biology texts is a time-consuming and hard task that requires domain-specific knowledge. Improving access for outsiders can help interdisciplinary research like Nature Inspired Engineering. This paper describes a dataset of 1,500 manually-annotated sentences that express domain-independent relations between central concepts in a scientific biology text, such as trade-offs and correlations. The arguments of these relations can be Multi Word Expressions and have been annotated with modifying phrases to form non-projective graphs. The dataset allows for training and evaluating Relation Extraction algorithms that aim for coarse-grained typing of scientific biological documents, enabling a high-level filter for engineers.
History for Visual Dialog: Do we really need it?
May 08, 2020

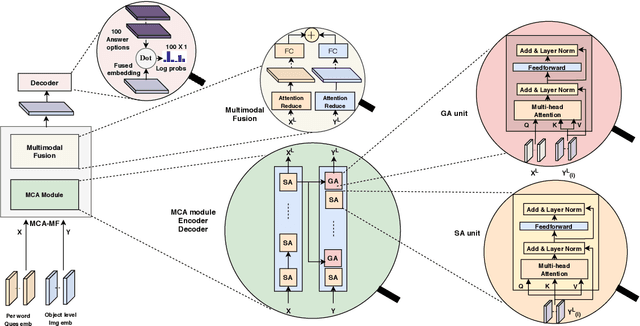
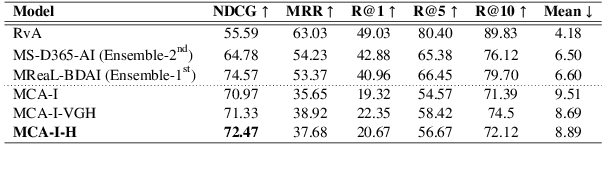
Visual Dialog involves "understanding" the dialog history (what has been discussed previously) and the current question (what is asked), in addition to grounding information in the image, to generate the correct response. In this paper, we show that co-attention models which explicitly encode dialog history outperform models that don't, achieving state-of-the-art performance (72 % NDCG on val set). However, we also expose shortcomings of the crowd-sourcing dataset collection procedure by showing that history is indeed only required for a small amount of the data and that the current evaluation metric encourages generic replies. To that end, we propose a challenging subset (VisDialConv) of the VisDial val set and provide a benchmark of 63% NDCG.