 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Inference for Sparse Extreme Multi-Label Ranking Trees
Jun 09, 2021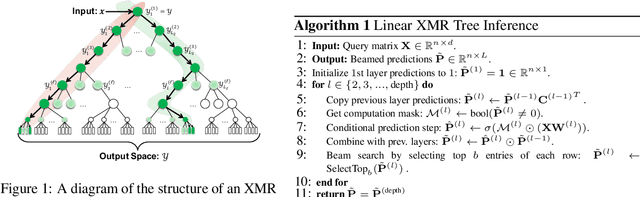

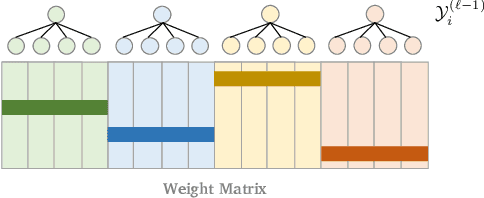
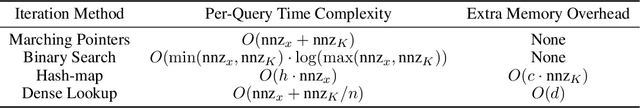
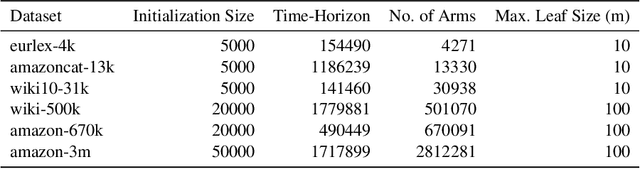
Tree-based models underpin many modern semantic search engines and recommender systems due to their sub-linear inference times. In industrial applications, these models operate at extreme scales, where every bit of performance is critical. Memory constraints at extreme scales also require that models be sparse, hence tree-based models are often back-ended by sparse matrix algebra routines. However, there are currently no sparse matrix techniques specifically designed for the sparsity structure one encounters in tree-based models for extreme multi-label ranking/classification (XMR/XMC) problems. To address this issue, we present the masked sparse chunk multiplication (MSCM) technique, a sparse matrix technique specifically tailored to XMR trees. MSCM is easy to implement, embarrassingly parallelizable, and offers a significant performance boost to any existing tree inference pipeline at no cost. We perform a comprehensive study of MSCM applied to several different sparse inference schemes and benchmark our methods on a general purpose extreme multi-label ranking framework. We observe that MSCM gives consistently dramatic speedups across both the online and batch inference settings, single- and multi-threaded settings, and on many different tree models and datasets. To demonstrate its utility in industrial applications, we apply MSCM to an enterprise-scale semantic product search problem with 100 million products and achieve sub-millisecond latency of 0.88 ms per query on a single thread -- an 8x reduction in latency over vanilla inference techniques. The MSCM technique requires absolutely no sacrifices to model accuracy as it gives exactly the same results as standard sparse matrix techniques. Therefore, we believe that MSCM will enable users of XMR trees to save a substantial amount of compute resources in their inference pipelines at very little cost.
Top-$k$ eXtreme Contextual Bandits with Arm Hierarchy
Feb 15, 2021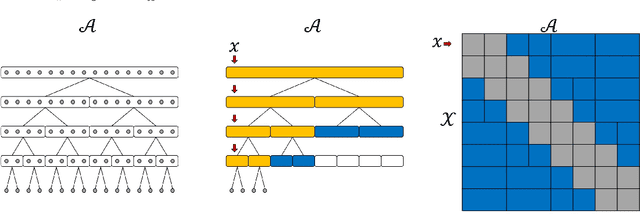
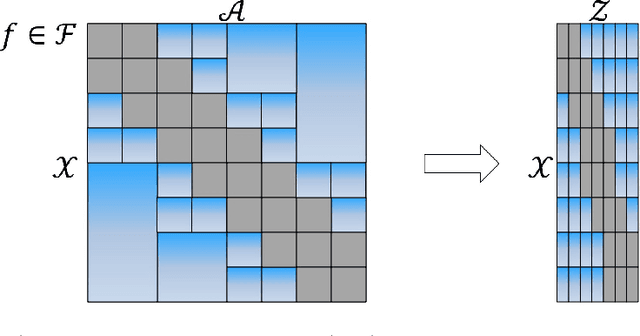
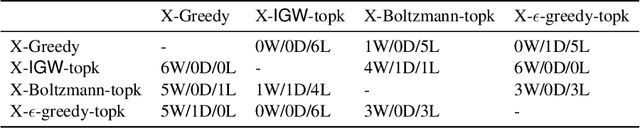
Motivated by modern applications, such as online advertisement and recommender systems, we study the top-$k$ extreme contextual bandits problem, where the total number of arms can be enormous, and the learner is allowed to select $k$ arms and observe all or some of the rewards for the chosen arms. We first propose an algorithm for the non-extreme realizable setting, utilizing the Inverse Gap Weighting strategy for selecting multiple arms. We show that our algorithm has a regret guarantee of $O(k\sqrt{(A-k+1)T \log (|\mathcal{F}|T)})$, where $A$ is the total number of arms and $\mathcal{F}$ is the class containing the regression function, while only requiring $\tilde{O}(A)$ computation per time step. In the extreme setting, where the total number of arms can be in the millions, we propose a practically-motivated arm hierarchy model that induces a certain structure in mean rewards to ensure statistical and computational efficiency. The hierarchical structure allows for an exponential reduction in the number of relevant arms for each context, thus resulting in a regret guarantee of $O(k\sqrt{(\log A-k+1)T \log (|\mathcal{F}|T)})$. Finally, we implement our algorithm using a hierarchical linear function class and show superior performance with respect to well-known benchmarks on simulated bandit feedback experiments using extreme multi-label classification datasets. On a dataset with three million arms, our reduction scheme has an average inference time of only 7.9 milliseconds, which is a 100x improvement.
Voting based ensemble improves robustness of defensive models
Nov 28, 2020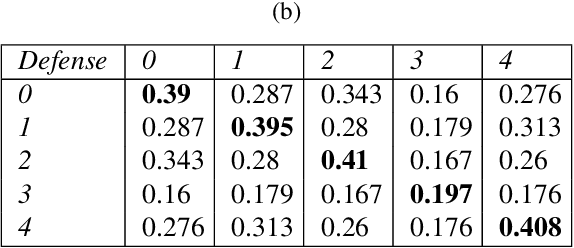
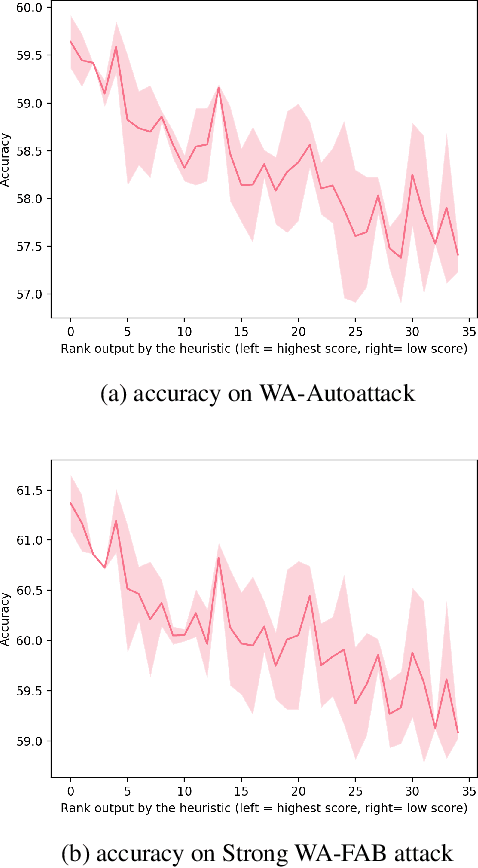
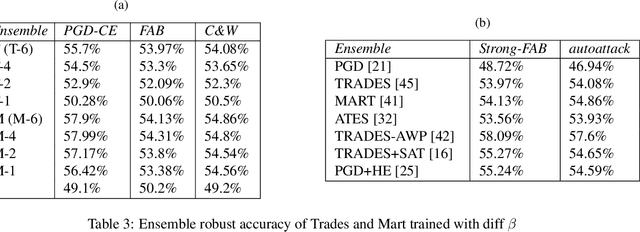
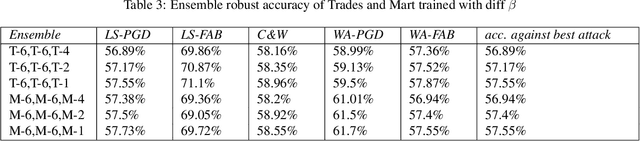
Developing robust models against adversarial perturbations has been an active area of research and many algorithms have been proposed to train individual robust models. Taking these pretrained robust models, we aim to study whether it is possible to create an ensemble to further improve robustness. Several previous attempts tackled this problem by ensembling the soft-label prediction and have been proved vulnerable based on the latest attack methods. In this paper, we show that if the robust training loss is diverse enough, a simple hard-label based voting ensemble can boost the robust error over each individual model. Furthermore, given a pool of robust models, we develop a principled way to select which models to ensemble. Finally, to verify the improved robustness, we conduct extensive experiments to study how to attack a voting-based ensemble and develop several new white-box attacks. On CIFAR-10 dataset, by ensembling several state-of-the-art pre-trained defense models, our method can achieve a 59.8% robust accuracy, outperforming all the existing defensive models without using additional data.
On the Benefits of Multiple Gossip Steps in Communication-Constrained Decentralized Optimization
Nov 20, 2020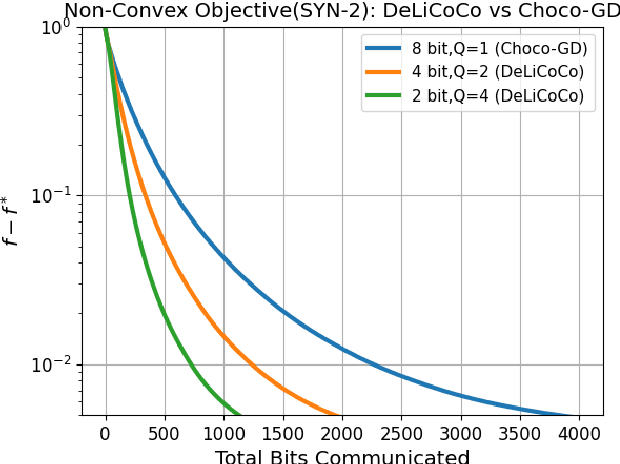
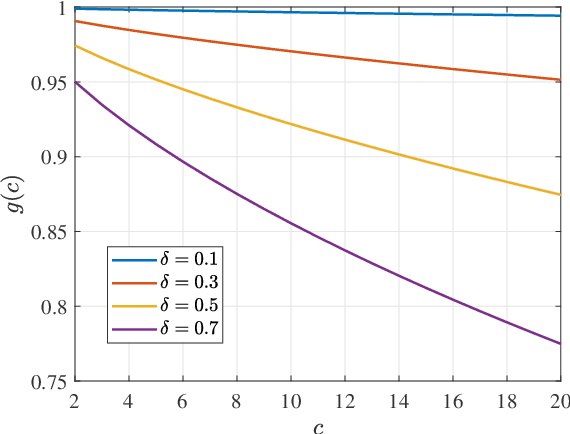
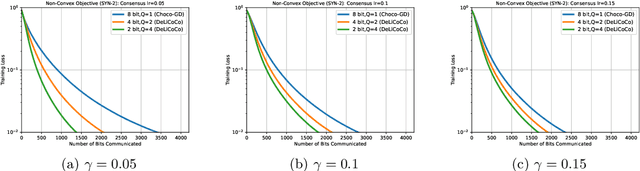
In decentralized optimization, it is common algorithmic practice to have nodes interleave (local) gradient descent iterations with gossip (i.e. averaging over the network) steps. Motivated by the training of large-scale machine learning models, it is also increasingly common to require that messages be {\em lossy compressed} versions of the local parameters. In this paper, we show that, in such compressed decentralized optimization settings, there are benefits to having {\em multiple} gossip steps between subsequent gradient iterations, even when the cost of doing so is appropriately accounted for e.g. by means of reducing the precision of compressed information. In particular, we show that having $O(\log\frac{1}{\epsilon})$ gradient iterations {with constant step size} - and $O(\log\frac{1}{\epsilon})$ gossip steps between every pair of these iterations - enables convergence to within $\epsilon$ of the optimal value for smooth non-convex objectives satisfying Polyak-\L{}ojasiewicz condition. This result also holds for smooth strongly convex objectives. To our knowledge, this is the first work that derives convergence results for nonconvex optimization under arbitrary communication compression.
Learning from eXtreme Bandit Feedback
Sep 27, 2020

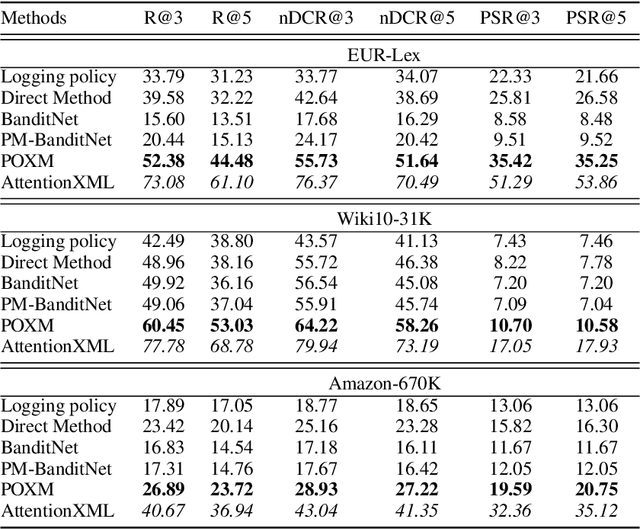
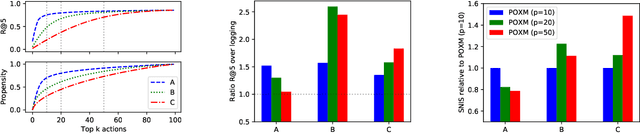
We study the problem of batch learning from bandit feedback in the setting of extremely large action spaces. Learning from extreme bandit feedback is ubiquitous in recommendation systems, in which billions of decisions are made over sets consisting of millions of choices in a single day, yielding massive observational data. In these large-scale real-world applications, supervised learning frameworks such as eXtreme Multi-label Classification (XMC) are widely used despite the fact that they incur significant biases due to the mismatch between bandit feedback and supervised labels. Such biases can be mitigated by importance sampling techniques, but these techniques suffer from impractical variance when dealing with a large number of actions. In this paper, we introduce a selective importance sampling estimator (sIS) that operates in a significantly more favorable bias-variance regime. The sIS estimator is obtained by performing importance sampling on the conditional expectation of the reward with respect to a small subset of actions for each instance (a form of Rao-Blackwellization). We employ this estimator in a novel algorithmic procedure---named Policy Optimization for eXtreme Models (POXM)---for learning from bandit feedback on XMC tasks. In POXM, the selected actions for the sIS estimator are the top-p actions of the logging policy, where p is adjusted from the data and is significantly smaller than the size of the action space. We use a supervised-to-bandit conversion on three XMC datasets to benchmark our POXM method against three competing methods: BanditNet, a previously applied partial matching pruning strategy, and a supervised learning baseline. Whereas BanditNet sometimes improves marginally over the logging policy, our experiments show that POXM systematically and significantly improves over all baselines.
Extreme Multi-label Classification from Aggregated Labels
Apr 01, 2020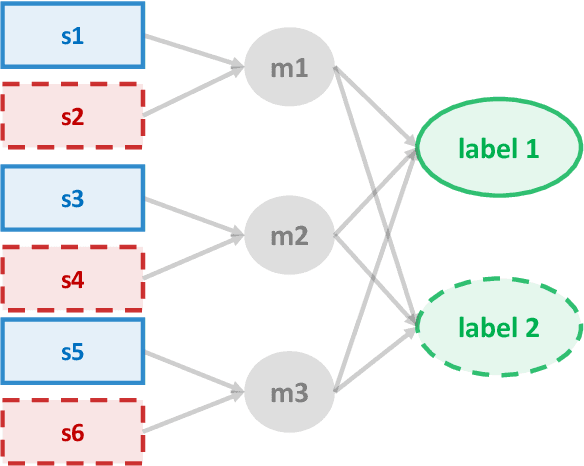



Extreme multi-label classification (XMC) is the problem of finding the relevant labels for an input, from a very large universe of possible labels. We consider XMC in the setting where labels are available only for groups of samples - but not for individual ones. Current XMC approaches are not built for such multi-instance multi-label (MIML) training data, and MIML approaches do not scale to XMC sizes. We develop a new and scalable algorithm to impute individual-sample labels from the group labels; this can be paired with any existing XMC method to solve the aggregated label problem. We characterize the statistical properties of our algorithm under mild assumptions, and provide a new end-to-end framework for MIML as an extension. Experiments on both aggregated label XMC and MIML tasks show the advantages over existing approaches.
Learning to Encode Position for Transformer with Continuous Dynamical Model
Mar 13, 2020
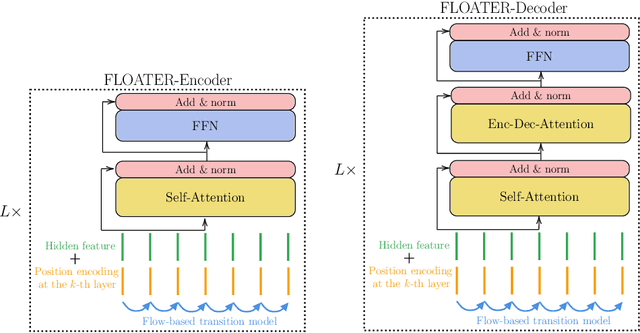
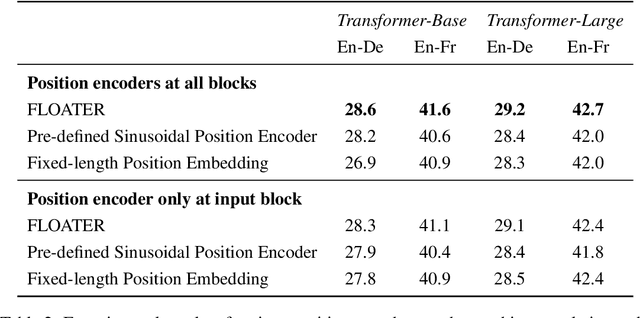
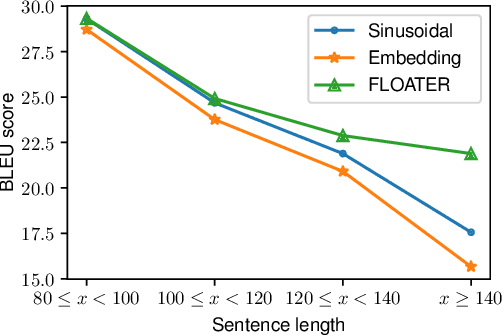
We introduce a new way of learning to encode position information for non-recurrent models, such as Transformer models. Unlike RNN and LSTM, which contain inductive bias by loading the input tokens sequentially, non-recurrent models are less sensitive to position. The main reason is that position information among input units is not inherently encoded, i.e., the models are permutation equivalent; this problem justifies why all of the existing models are accompanied by a sinusoidal encoding/embedding layer at the input. However, this solution has clear limitations: the sinusoidal encoding is not flexible enough as it is manually designed and does not contain any learnable parameters, whereas the position embedding restricts the maximum length of input sequences. It is thus desirable to design a new position layer that contains learnable parameters to adjust to different datasets and different architectures. At the same time, we would also like the encodings to extrapolate in accordance with the variable length of inputs. In our proposed solution, we borrow from the recent Neural ODE approach, which may be viewed as a versatile continuous version of a ResNet. This model is capable of modeling many kinds of dynamical systems. We model the evolution of encoded results along position index by such a dynamical system, thereby overcoming the above limitations of existing methods. We evaluate our new position layers on a variety of neural machine translation and language understanding tasks, the experimental results show consistent improvements over the baselines.
CAT: Customized Adversarial Training for Improved Robustness
Feb 17, 2020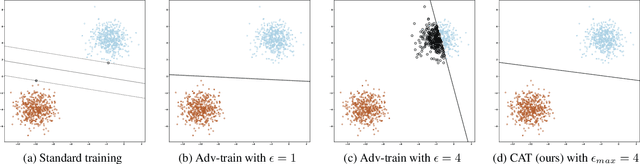
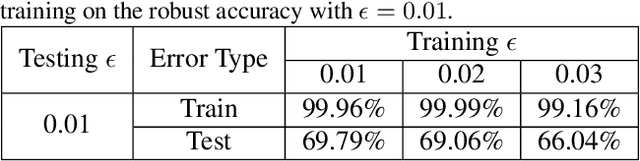

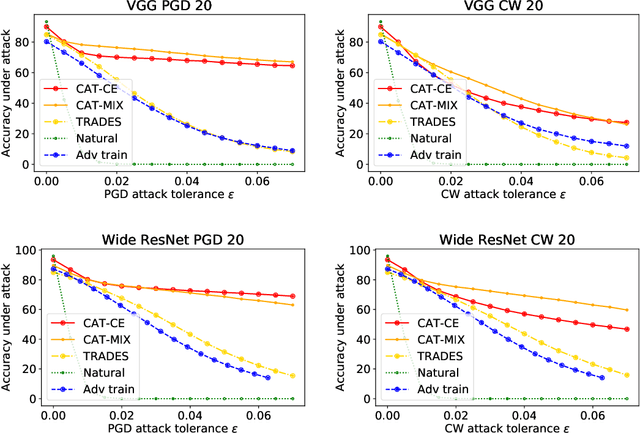
Adversarial training has become one of the most effective methods for improving robustness of neural networks. However, it often suffers from poor generalization on both clean and perturbed data. In this paper, we propose a new algorithm, named Customized Adversarial Training (CAT), which adaptively customizes the perturbation level and the corresponding label for each training sample in adversarial training. We show that the proposed algorithm achieves better clean and robust accuracy than previous adversarial training methods through extensive experiments.
Think Globally, Act Locally: A Deep Neural Network Approach to High-Dimensional Time Series Forecasting
May 09, 2019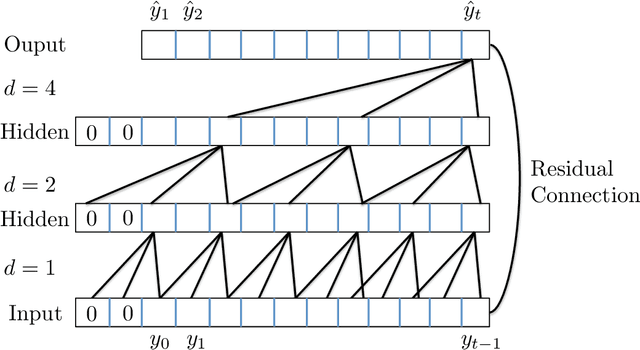
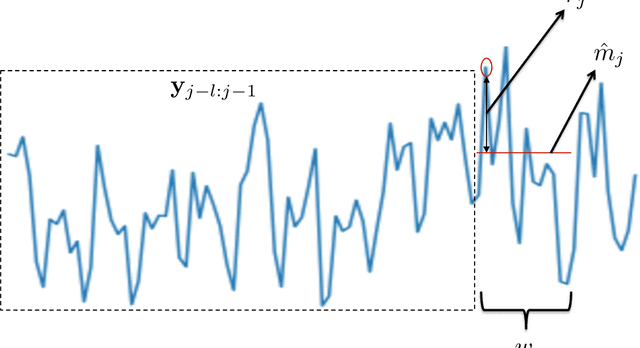

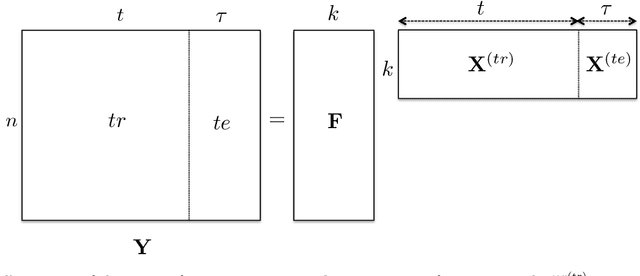
Forecasting high-dimensional time series plays a crucial role in many applications such as demand forecasting and financial predictions. Modern real-world datasets can have millions of correlated time-series that evolve together, i.e they are extremely high dimensional (one dimension for each individual time-series). Thus there is need for exploiting these global patterns and coupling them with local calibration for better prediction. However, most recent deep learning approaches in the literature are one-dimensional, i.e, even though they are trained on the whole dataset, during prediction, the future forecast for a single dimension mainly depends on past values from the same dimension. In this paper, we seek to correct this deficiency and propose DeepGLO, a deep forecasting model which thinks globally and acts locally. In particular, DeepGLO is a hybrid model that combines a global matrix factorization model regularized by a temporal deep network with a local deep temporal model that captures patterns specific to each dimension. The global and local models are combined via a data-driven attention mechanism for each dimension. The proposed deep architecture used is a variation of temporal convolution termed as leveled network which can be trained effectively on high-dimensional but diverse time series, where different time series can have vastly different scales, without a priori normalization or rescaling. Empirical results demonstrate that DeepGLO outperforms state-of-the-art approaches on various datasets; for example, we see more than 30% improvement in WAPE over other methods on a real-world dataset that contains more than 100K-dimensional time series.
A Modular Deep Learning Approach for Extreme Multi-label Text Classification
May 07, 2019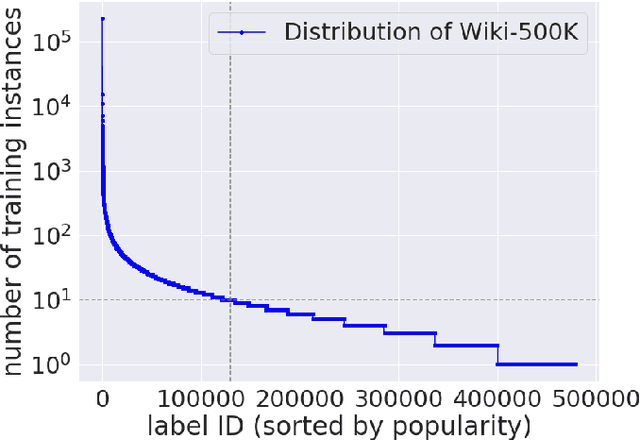

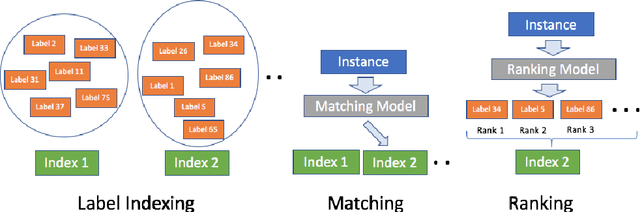
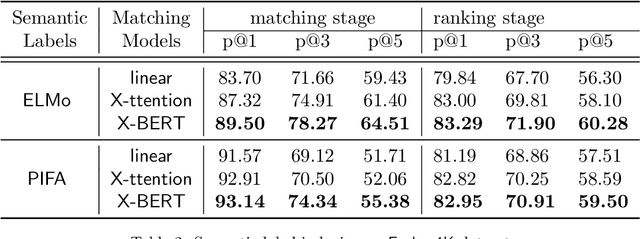
Extreme multi-label classification (XMC) aims to assign to an instance the most relevant subset of labels from a colossal label set. Due to modern applications that lead to massive label sets, the scalability of XMC has attracted much recent attention from both academia and industry. In this paper, we establish a three-stage framework to solve XMC efficiently, which includes 1) indexing the labels, 2) matching the instance to the relevant indices, and 3) ranking the labels from the relevant indices. This framework unifies many existing XMC approaches. Based on this framework, we propose a modular deep learning approach SLINMER: Semantic Label Indexing, Neural Matching, and Efficient Ranking. The label indexing stage of SLINMER can adopt different semantic label representations leading to different configurations of SLINMER. Empirically, we demonstrate that several individual configurations of SLINMER achieve superior performance than the state-of-the-art XMC approaches on several benchmark datasets. Moreover, by ensembling those configurations, SLINMER can achieve even better results. In particular, on a Wiki dataset with around 0.5 millions of labels, the precision@1 is increased from 61% to 67%.