 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-$k$ eXtreme Contextual Bandits with Arm Hierarchy
Paper and Code
Feb 15, 2021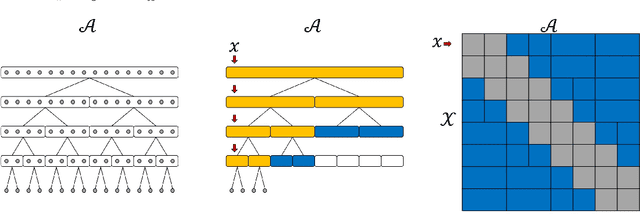
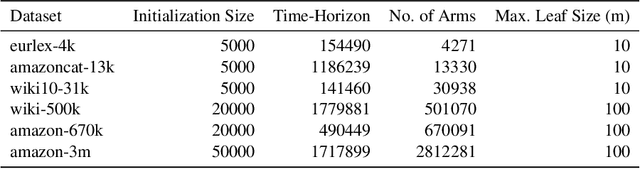
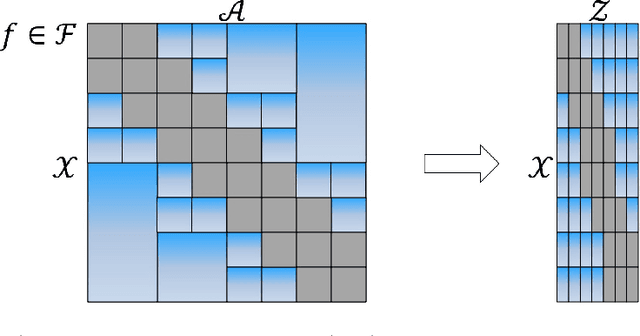
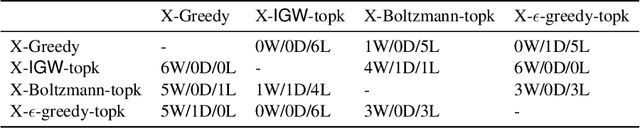
Motivated by modern applications, such as online advertisement and recommender systems, we study the top-$k$ extreme contextual bandits problem, where the total number of arms can be enormous, and the learner is allowed to select $k$ arms and observe all or some of the rewards for the chosen arms. We first propose an algorithm for the non-extreme realizable setting, utilizing the Inverse Gap Weighting strategy for selecting multiple arms. We show that our algorithm has a regret guarantee of $O(k\sqrt{(A-k+1)T \log (|\mathcal{F}|T)})$, where $A$ is the total number of arms and $\mathcal{F}$ is the class containing the regression function, while only requiring $\tilde{O}(A)$ computation per time step. In the extreme setting, where the total number of arms can be in the millions, we propose a practically-motivated arm hierarchy model that induces a certain structure in mean rewards to ensure statistical and computational efficiency. The hierarchical structure allows for an exponential reduction in the number of relevant arms for each context, thus resulting in a regret guarantee of $O(k\sqrt{(\log A-k+1)T \log (|\mathcal{F}|T)})$. Finally, we implement our algorithm using a hierarchical linear function class and show superior performance with respect to well-known benchmarks on simulated bandit feedback experiments using extreme multi-label classification datasets. On a dataset with three million arms, our reduction scheme has an average inference time of only 7.9 milliseconds, which is a 100x improvement.