 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-blurred Video Interpolation and Extrapolation
Mar 10, 2021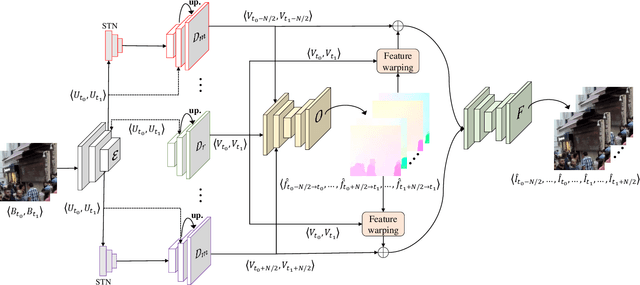
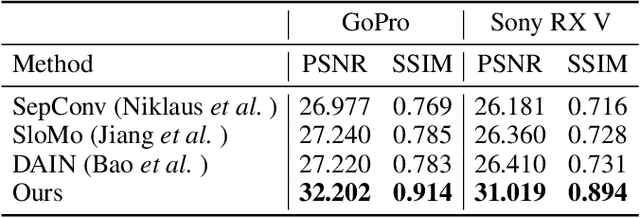

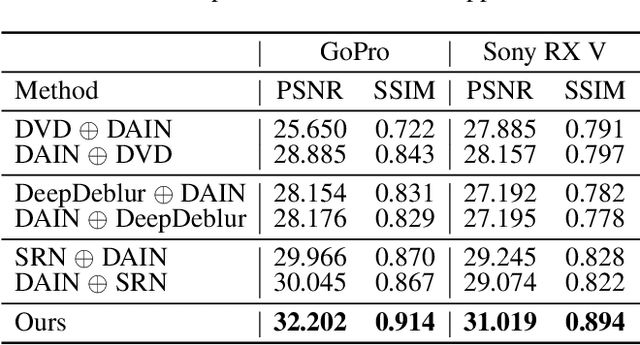
Abrupt motion of camera or objects in a scene result in a blurry video, and therefore recovering high quality video requires two types of enhancements: visual enhancement and temporal upsampling. A broad range of research attempted to recover clean frames from blurred image sequences or temporally upsample frames by interpolation, yet there are very limited studies handling both problems jointly. In this work, we present a novel framework for deblurring, interpolating and extrapolating sharp frames from a motion-blurred video in an end-to-end manner. We design our framework by first learning the pixel-level motion that caused the blur from the given inputs via optical flow estimation and then predict multiple clean frames by warping the decoded features with the estimated flows. To ensure temporal coherence across predicted frames and address potential temporal ambiguity, we propose a simple, yet effective flow-based rule. The effectiveness and favorability of our approach are highlighted through extensive qualitative and quantitative evaluations on motion-blurred datasets from high speed videos.
Optical Flow Estimation from a Single Motion-blurred Image
Mar 10, 2021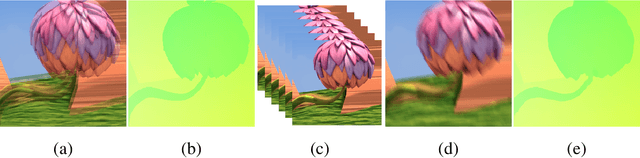

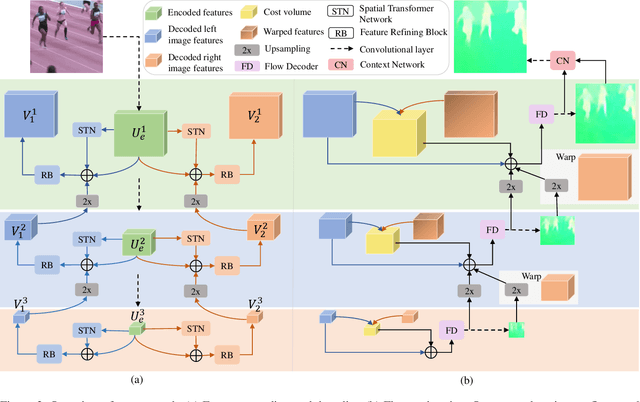
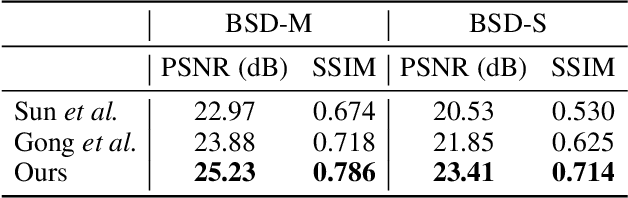
In most of computer vision applications, motion blur is regarded as an undesirable artifact. However, it has been shown that motion blur in an image may have practical interests in fundamental computer vision problems. In this work, we propose a novel framework to estimate optical flow from a single motion-blurred image in an end-to-end manner. We design our network with transformer networks to learn globally and locally varying motions from encoded features of a motion-blurred input, and decode left and right frame features without explicit frame supervision. A flow estimator network is then used to estimate optical flow from the decoded features in a coarse-to-fine manner. We qualitatively and quantitatively evaluate our model through a large set of experiments on synthetic and real motion-blur datasets. We also provide in-depth analysis of our model in connection with related approaches to highlight the effectiveness and favorability of our approach. Furthermore, we showcase the applicability of the flow estimated by our method on deblurring and moving object segmentation tasks.
Unsupervised Depth and Ego-motion Estimation for Monocular Thermal Video using Multi-spectral Consistency Loss
Mar 03, 2021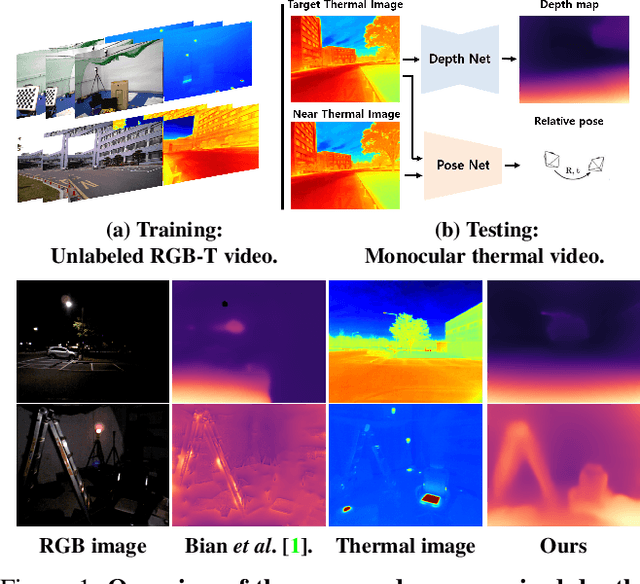
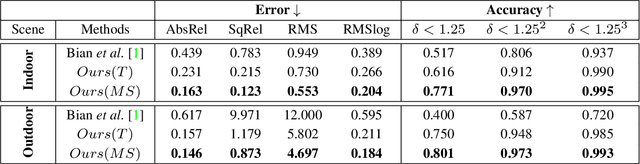

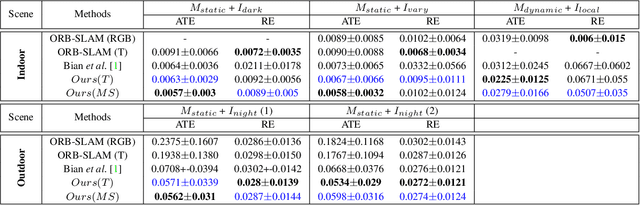
Most of the deep-learning based depth and ego-motion networks have been designed for visible cameras. However, visible cameras heavily rely on the presence of an external light source. Therefore, it is challenging to use them under low-light conditions such as night scenes, tunnels, and other harsh conditions. A thermal camera is one solution to compensate for this problem because it detects Long Wave Infrared Radiation(LWIR) regardless of any external light sources. However, despite this advantage, both depth and ego-motion estimation research for the thermal camera are not actively explored until so far. In this paper, we propose an unsupervised learning method for the all-day depth and ego-motion estimation. The proposed method exploits multi-spectral consistency loss to gives complementary supervision for the networks by reconstructing visible and thermal images with the depth and pose estimated from thermal images. The networks trained with the proposed method robustly estimate the depth and pose from monocular thermal video under low-light and even zero-light conditions. To the best of our knowledge, this is the first work to simultaneously estimate both depth and ego-motion from the monocular thermal video in an unsupervised manner.
A Brief Survey on Deep Learning Based Data Hiding, Steganography and Watermarking
Mar 02, 2021


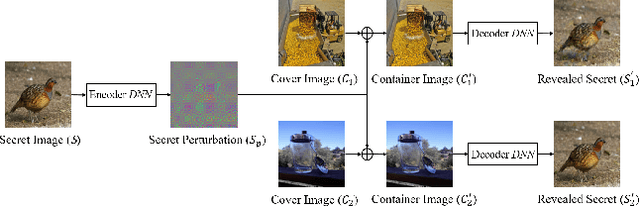
Data hiding is the art of concealing messages with limited perceptual changes. Recently, deep learning has provided enriching perspectives for it and made significant progress. In this work, we conduct a brief yet comprehensive review of existing literature and outline three meta-architectures. Based on this, we summarize specific strategies for various applications of deep hiding, including steganography, light field messaging and watermarking. Finally, further insight into deep hiding is provided through incorporating the perspective of adversarial attack.
A Survey On Universal Adversarial Attack
Mar 02, 2021
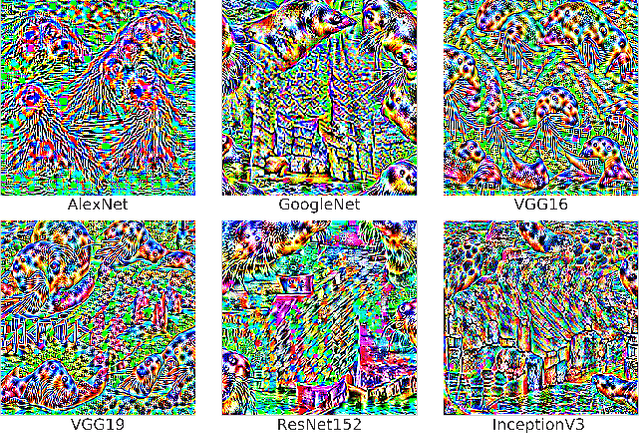

Deep neural networks (DNNs) have demonstrated remarkable performance for various applications, meanwhile, they are widely known to be vulnerable to the attack of adversarial perturbations. This intriguing phenomenon has attracted significant attention in machine learning and what might be more surprising to the community is the existence of universal adversarial perturbations (UAPs), i.e. a single perturbation to fool the target DNN for most images. The advantage of UAP is that it can be generated beforehand and then be applied on-the-fly during the attack. With the focus on UAP against deep classifiers, this survey summarizes the recent progress on universal adversarial attacks, discussing the challenges from both the attack and defense sides, as well as the reason for the existence of UAP. Additionally, universal attacks in a wide range of applications beyond deep classification are also covered.
Universal Adversarial Perturbations Through the Lens of Deep Steganography: Towards A Fourier Perspective
Feb 12, 2021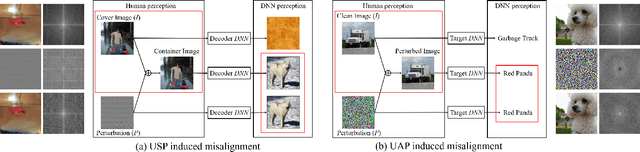

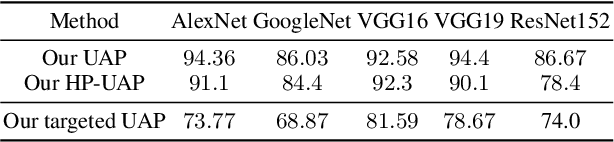
The booming interest in adversarial attacks stems from a misalignment between human vision and a deep neural network (DNN), i.e. a human imperceptible perturbation fools the DNN. Moreover, a single perturbation, often called universal adversarial perturbation (UAP), can be generated to fool the DNN for most images. A similar misalignment phenomenon has recently also been observed in the deep steganography task, where a decoder network can retrieve a secret image back from a slightly perturbed cover image. We attempt explaining the success of both in a unified manner from the Fourier perspective. We perform task-specific and joint analysis and reveal that (a) frequency is a key factor that influences their performance based on the proposed entropy metric for quantifying the frequency distribution; (b) their success can be attributed to a DNN being highly sensitive to high-frequency content. We also perform feature layer analysis for providing deep insight on model generalization and robustness. Additionally, we propose two new variants of universal perturbations: (1) Universal Secret Adversarial Perturbation (USAP) that simultaneously achieves attack and hiding; (2) high-pass UAP (HP-UAP) that is less visible to the human eye.
Learning Monocular Depth in Dynamic Scenes via Instance-Aware Projection Consistency
Feb 04, 2021

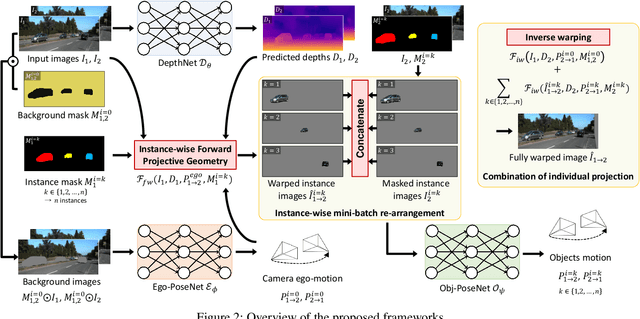
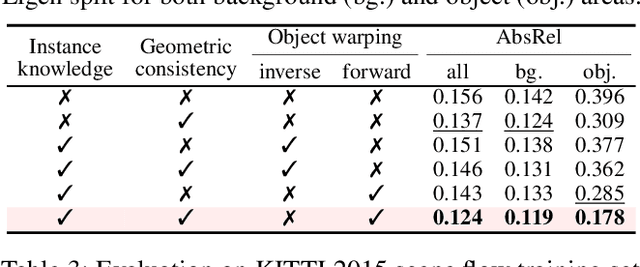
We present an end-to-end joint training framework that explicitly models 6-DoF motion of multiple dynamic objects, ego-motion and depth in a monocular camera setup without supervision. Our technical contributions are three-fold. First, we highlight the fundamental difference between inverse and forward projection while modeling the individual motion of each rigid object, and propose a geometrically correct projection pipeline using a neural forward projection module. Second, we design a unified instance-aware photometric and geometric consistency loss that holistically imposes self-supervisory signals for every background and object region. Lastly, we introduce a general-purpose auto-annotation scheme using any off-the-shelf instance segmentation and optical flow models to produce video instance segmentation maps that will be utilized as input to our training pipeline. These proposed elements are validated in a detailed ablation study. Through extensive experiments conducted on the KITTI and Cityscapes dataset, our framework is shown to outperform the state-of-the-art depth and motion estimation methods. Our code, dataset, and models are available at https://github.com/SeokjuLee/Insta-DM .
An Efficient Asynchronous Method for Integrating Evolutionary and Gradient-based Policy Search
Jan 06, 2021
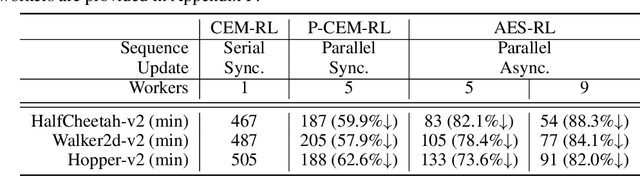
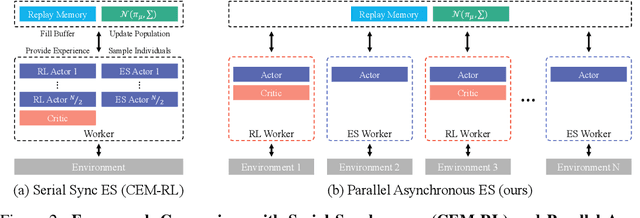

Deep reinforcement learning (DRL) algorithms and evolution strategies (ES) have been applied to various tasks, showing excellent performances. These have the opposite properties, with DRL having good sample efficiency and poor stability, while ES being vice versa. Recently, there have been attempts to combine these algorithms, but these methods fully rely on synchronous update scheme, making it not ideal to maximize the benefits of the parallelism in ES. To solve this challenge, asynchronous update scheme was introduced, which is capable of good time-efficiency and diverse policy exploration. In this paper, we introduce an Asynchronous Evolution Strategy-Reinforcement Learning (AES-RL) that maximizes the parallel efficiency of ES and integrates it with policy gradient methods. Specifically, we propose 1) a novel framework to merge ES and DRL asynchronously and 2) various asynchronous update methods that can take all advantages of asynchronism, ES, and DRL, which are exploration and time efficiency, stability, and sample efficiency, respectively. The proposed framework and update methods are evaluated in continuous control benchmark work, showing superior performance as well as time efficiency compared to the previous methods.
Towards Robust Data Hiding Against (JPEG) Compression: A Pseudo-Differentiable Deep Learning Approach
Dec 30, 2020
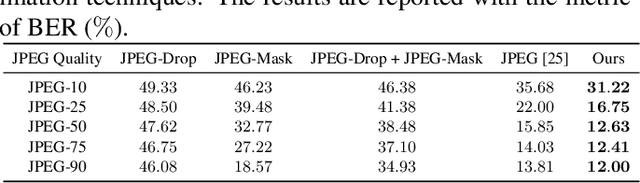
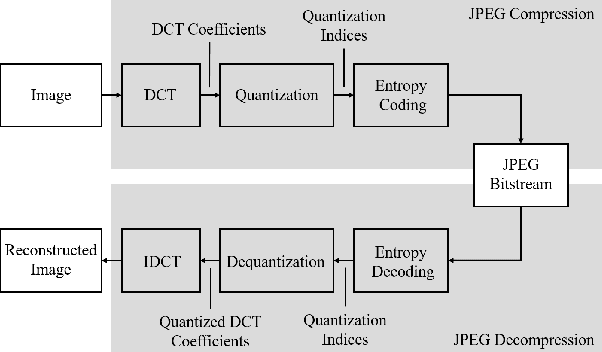

Data hiding is one widely used approach for protecting authentication and ownership. Most multimedia content like images and videos are transmitted or saved in the compressed form. This kind of lossy compression, such as JPEG, can destroy the hidden data, which raises the need of robust data hiding. It is still an open challenge to achieve the goal of data hiding that can be against these compressions. Recently, deep learning has shown large success in data hiding, while non-differentiability of JPEG makes it challenging to train a deep pipeline for improving robustness against lossy compression. The existing SOTA approaches replace the non-differentiable parts with differentiable modules that perform similar operations. Multiple limitations exist: (a) large engineering effort; (b) requiring a white-box knowledge of compression attacks; (c) only works for simple compression like JPEG. In this work, we propose a simple yet effective approach to address all the above limitations at once. Beyond JPEG, our approach has been shown to improve robustness against various image and video lossy compression algorithms.
The Devil is in the Boundary: Exploiting Boundary Representation for Basis-based Instance Segmentation
Nov 26, 2020
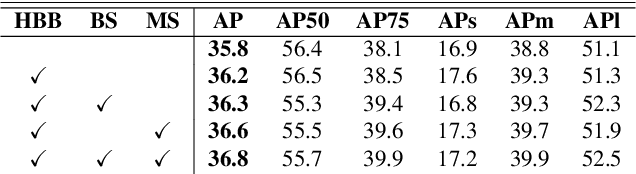
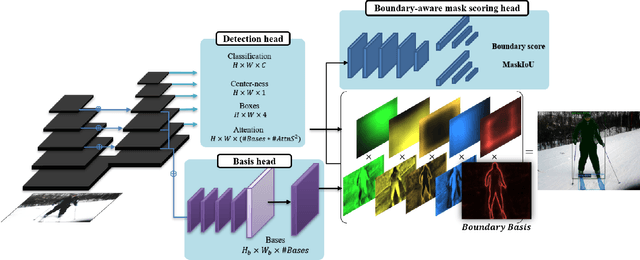
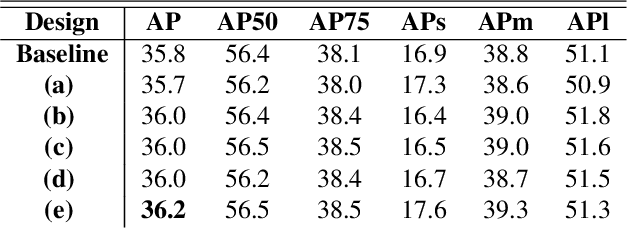
Pursuing a more coherent scene understanding towards real-time vision applications, single-stage instance segmentation has recently gained popularity, achieving a simpler and more efficient design than its two-stage counterparts. Besides, its global mask representation often leads to superior accuracy to the two-stage Mask R-CNN which has been dominant thus far. Despite the promising advances in single-stage methods, finer delineation of instance boundaries still remains unexcavated. Indeed, boundary information provides a strong shape representation that can operate in synergy with the fully-convolutional mask features of the single-stage segmenter. In this work, we propose Boundary Basis based Instance Segmentation(B2Inst) to learn a global boundary representation that can complement existing global-mask-based methods that are often lacking high-frequency details. Besides, we devise a unified quality measure of both mask and boundary and introduce a network block that learns to score the per-instance predictions of itself. When applied to the strongest baselines in single-stage instance segmentation, our B2Inst leads to consistent improvements and accurately parse out the instance boundaries in a scene. Regardless of being single-stage or two-stage frameworks, we outperform the existing state-of-the-art methods on the COCO dataset with the same ResNet-50 and ResNet-101 backbones.