 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking by Associating Clips
Dec 20, 2022The tracking-by-detection paradigm today has become the dominant method for multi-object tracking and works by detecting objects in each frame and then performing data association across frames. However, its sequential frame-wise matching property fundamentally suffers from the intermediate interruptions in a video, such as object occlusions, fast camera movements, and abrupt light changes. Moreover, it typically overlooks temporal information beyond the two frames for matching. In this paper, we investigate an alternative by treating object association as clip-wise matching. Our new perspective views a single long video sequence as multiple short clips, and then the tracking is performed both within and between the clips. The benefits of this new approach are two folds. First, our method is robust to tracking error accumulation or propagation, as the video chunking allows bypassing the interrupted frames, and the short clip tracking avoids the conventional error-prone long-term track memory management. Second, the multiple frame information is aggregated during the clip-wise matching, resulting in a more accurate long-range track association than the current frame-wise matching. Given the state-of-the-art tracking-by-detection tracker, QDTrack, we showcase how the tracking performance improves with our new tracking formulation. We evaluate our proposals on two tracking benchmarks, TAO and MOT17 that have complementary characteristics and challenges each other.
Bridging Images and Videos: A Simple Learning Framework for Large Vocabulary Video Object Detection
Dec 20, 2022Scaling object taxonomies is one of the important steps toward a robust real-world deployment of recognition systems. We have faced remarkable progress in images since the introduction of the LVIS benchmark. To continue this success in videos, a new video benchmark, TAO, was recently presented. Given the recent encouraging results from both detection and tracking communities, we are interested in marrying those two advances and building a strong large vocabulary video tracker. However, supervisions in LVIS and TAO are inherently sparse or even missing, posing two new challenges for training the large vocabulary trackers. First, no tracking supervisions are in LVIS, which leads to inconsistent learning of detection (with LVIS and TAO) and tracking (only with TAO). Second, the detection supervisions in TAO are partial, which results in catastrophic forgetting of absent LVIS categories during video fine-tuning. To resolve these challenges, we present a simple but effective learning framework that takes full advantage of all available training data to learn detection and tracking while not losing any LVIS categories to recognize. With this new learning scheme, we show that consistent improvements of various large vocabulary trackers are capable, setting strong baseline results on the challenging TAO benchmarks.
Learning Classifiers of Prototypes and Reciprocal Points for Universal Domain Adaptation
Dec 16, 2022



Universal Domain Adaptation aims to transfer the knowledge between the datasets by handling two shifts: domain-shift and category-shift. The main challenge is correctly distinguishing the unknown target samples while adapting the distribution of known class knowledge from source to target. Most existing methods approach this problem by first training the target adapted known classifier and then relying on the single threshold to distinguish unknown target samples. However, this simple threshold-based approach prevents the model from considering the underlying complexities existing between the known and unknown samples in the high-dimensional feature space. In this paper, we propose a new approach in which we use two sets of feature points, namely dual Classifiers for Prototypes and Reciprocals (CPR). Our key idea is to associate each prototype with corresponding known class features while pushing the reciprocals apart from these prototypes to locate them in the potential unknown feature space. The target samples are then classified as unknown if they fall near any reciprocals at test time. To successfully train our framework, we collect the partial, confident target samples that are classified as known or unknown through on our proposed multi-criteria selection. We then additionally apply the entropy loss regularization to them. For further adaptation, we also apply standard consistency regularization that matches the predictions of two different views of the input to make more compact target feature space. We evaluate our proposal, CPR, on three standard benchmarks and achieve comparable or new state-of-the-art results. We also provide extensive ablation experiments to verify our main design choices in our framework.
CD-TTA: Compound Domain Test-time Adaptation for Semantic Segmentation
Dec 16, 2022



Test-time adaptation (TTA) has attracted significant attention due to its practical properties which enable the adaptation of a pre-trained model to a new domain with only target dataset during the inference stage. Prior works on TTA assume that the target dataset comes from the same distribution and thus constitutes a single homogeneous domain. In practice, however, the target domain can contain multiple homogeneous domains which are sufficiently distinctive from each other and those multiple domains might occur cyclically. Our preliminary investigation shows that domain-specific TTA outperforms vanilla TTA treating compound domain (CD) as a single one. However, domain labels are not available for CD, which makes domain-specific TTA not practicable. To this end, we propose an online clustering algorithm for finding pseudo-domain labels to obtain similar benefits as domain-specific configuration and accumulating knowledge of cyclic domains effectively. Moreover, we observe that there is a significant discrepancy in terms of prediction quality among samples, especially in the CD context. This further motivates us to boost its performance with gradient denoising by considering the image-wise similarity with the source distribution. Overall, the key contribution of our work lies in proposing a highly significant new task compound domain test-time adaptation (CD-TTA) on semantic segmentation as well as providing a strong baseline to facilitate future works to benchmark.
MATE: Masked Autoencoders are Online 3D Test-Time Learners
Nov 24, 2022



We propose MATE, the first Test-Time-Training (TTT) method designed for 3D data. It makes deep networks trained in point cloud classification robust to distribution shifts occurring in test data, which could not be anticipated during training. Like existing TTT methods, which focused on classifying 2D images in the presence of distribution shifts at test-time, MATE also leverages test data for adaptation. Its test-time objective is that of a Masked Autoencoder: Each test point cloud has a large portion of its points removed before it is fed to the network, tasked with reconstructing the full point cloud. Once the network is updated, it is used to classify the point cloud. We test MATE on several 3D object classification datasets and show that it significantly improves robustness of deep networks to several types of corruptions commonly occurring in 3D point clouds. Further, we show that MATE is very efficient in terms of the fraction of points it needs for the adaptation. It can effectively adapt given as few as 5% of tokens of each test sample, which reduces its memory footprint and makes it lightweight. We also highlight that MATE achieves competitive performance by adapting sparingly on the test data, which further reduces its computational overhead, making it ideal for real-time applications.
Signing Outside the Studio: Benchmarking Background Robustness for Continuous Sign Language Recognition
Nov 01, 2022



The goal of this work is background-robust continuous sign language recognition. Most existing Continuous Sign Language Recognition (CSLR) benchmarks have fixed backgrounds and are filmed in studios with a static monochromatic background. However, signing is not limited only to studios in the real world. In order to analyze the robustness of CSLR models under background shifts, we first evaluate existing state-of-the-art CSLR models on diverse backgrounds. To synthesize the sign videos with a variety of backgrounds, we propose a pipeline to automatically generate a benchmark dataset utilizing existing CSLR benchmarks. Our newly constructed benchmark dataset consists of diverse scenes to simulate a real-world environment. We observe even the most recent CSLR method cannot recognize glosses well on our new dataset with changed backgrounds. In this regard, we also propose a simple yet effective training scheme including (1) background randomization and (2) feature disentanglement for CSLR models. The experimental results on our dataset demonstrate that our method generalizes well to other unseen background data with minimal additional training images.
Moving from 2D to 3D: volumetric medical image classification for rectal cancer staging
Sep 13, 2022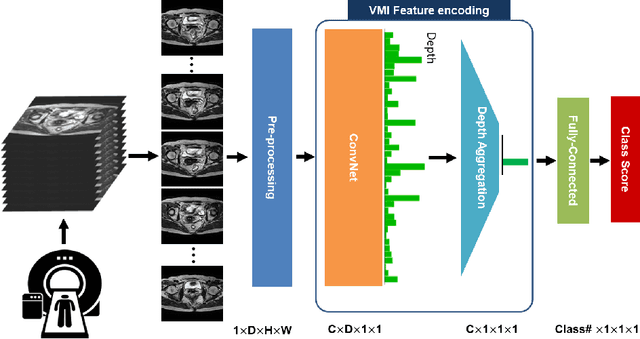
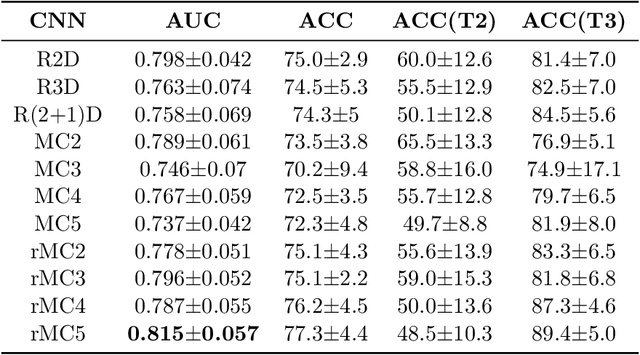
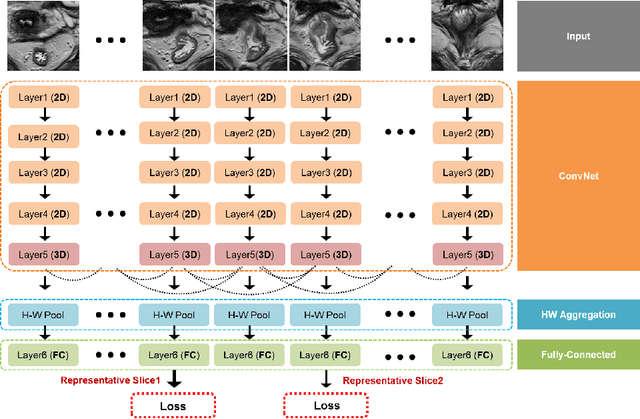

Volumetric images from Magnetic Resonance Imaging (MRI) provide invaluable information in preoperative staging of rectal cancer. Above all, accurate preoperative discrimination between T2 and T3 stages is arguably both the most challenging and clinically significant task for rectal cancer treatment, as chemo-radiotherapy is usually recommended to patients with T3 (or greater) stage cancer. In this study, we present a volumetric convolutional neural network to accurately discriminate T2 from T3 stage rectal cancer with rectal MR volumes. Specifically, we propose 1) a custom ResNet-based volume encoder that models the inter-slice relationship with late fusion (i.e., 3D convolution at the last layer), 2) a bilinear computation that aggregates the resulting features from the encoder to create a volume-wise feature, and 3) a joint minimization of triplet loss and focal loss. With MR volumes of pathologically confirmed T2/T3 rectal cancer, we perform extensive experiments to compare various designs within the framework of residual learning. As a result, our network achieves an AUC of 0.831, which is higher than the reported accuracy of the professional radiologist groups. We believe this method can be extended to other volume analysis tasks
Per-Clip Video Object Segmentation
Aug 03, 2022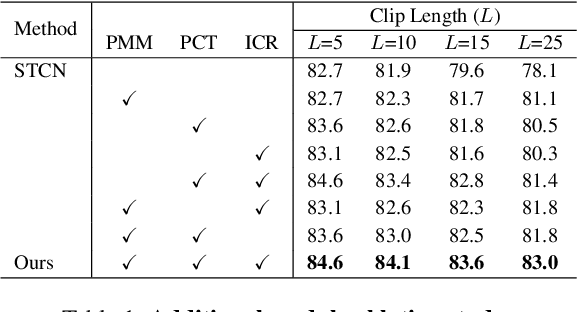
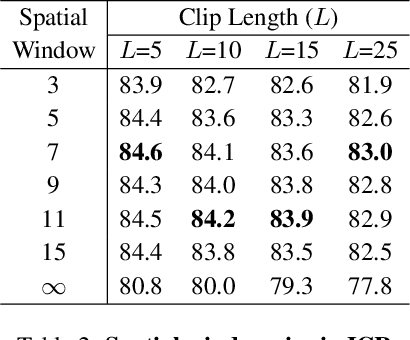
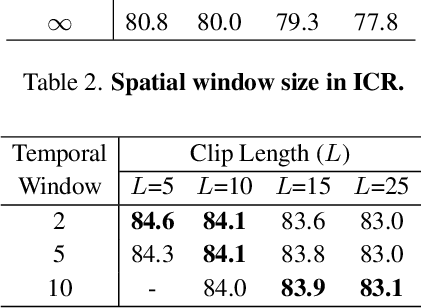

Recently, memory-based approaches show promising results on semi-supervised video object segmentation. These methods predict object masks frame-by-frame with the help of frequently updated memory of the previous mask. Different from this per-frame inference, we investigate an alternative perspective by treating video object segmentation as clip-wise mask propagation. In this per-clip inference scheme, we update the memory with an interval and simultaneously process a set of consecutive frames (i.e. clip) between the memory updates. The scheme provides two potential benefits: accuracy gain by clip-level optimization and efficiency gain by parallel computation of multiple frames. To this end, we propose a new method tailored for the per-clip inference. Specifically, we first introduce a clip-wise operation to refine the features based on intra-clip correlation. In addition, we employ a progressive matching mechanism for efficient information-passing within a clip. With the synergy of two modules and a newly proposed per-clip based training, our network achieves state-of-the-art performance on Youtube-VOS 2018/2019 val (84.6% and 84.6%) and DAVIS 2016/2017 val (91.9% and 86.1%). Furthermore, our model shows a great speed-accuracy trade-off with varying memory update intervals, which leads to huge flexibility.
Generative Bias for Visual Question Answering
Aug 02, 2022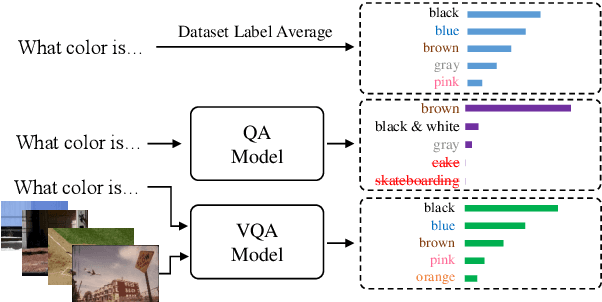
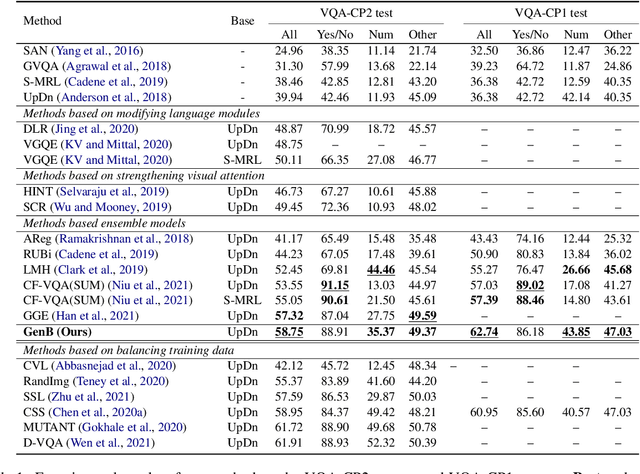

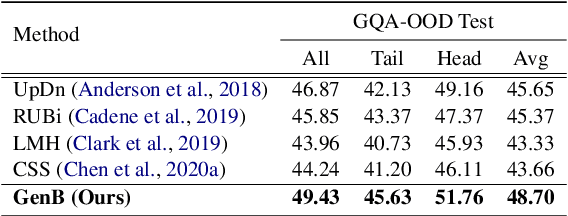
The task of Visual Question Answering (VQA) is known to be plagued by the issue of VQA models exploiting biases within the dataset to make its final prediction. Many previous ensemble based debiasing methods have been proposed where an additional model is purposefully trained to be biased in order to aid in training a robust target model. However, these methods compute the bias for a model from the label statistics of the training data or directly from single modal branches. In contrast, in this work, in order to better learn the bias a target VQA model suffers from, we propose a generative method to train the bias model \emph{directly from the target model}, called GenB. In particular, GenB employs a generative network to learn the bias through a combination of the adversarial objective and knowledge distillation. We then debias our target model with GenB as a bias model, and show through extensive experiments the effects of our method on various VQA bias datasets including VQA-CP2, VQA-CP1, GQA-OOD, and VQA-CE.
A Survey on Masked Autoencoder for Self-supervised Learning in Vision and Beyond
Jul 30, 2022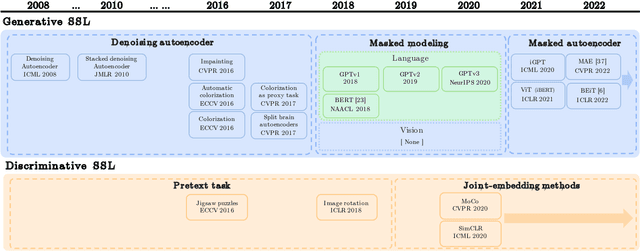

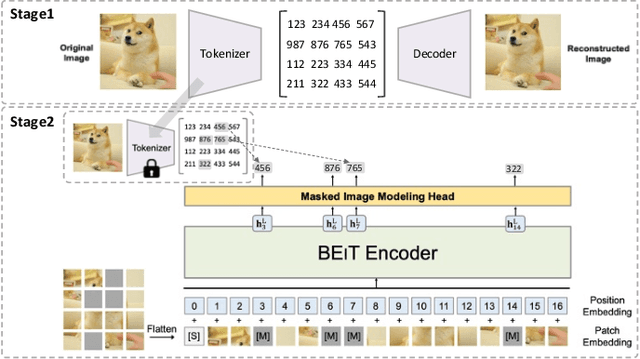
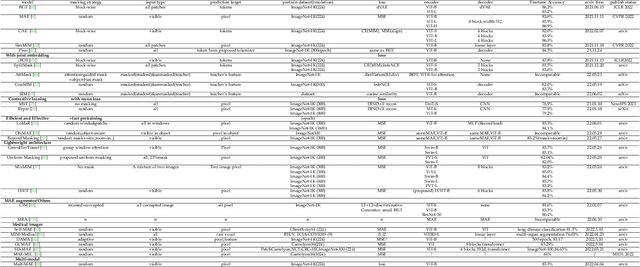
Masked autoencoders are scalable vision learners, as the title of MAE \cite{he2022masked}, which suggests that self-supervised learning (SSL) in vision might undertake a similar trajectory as in NLP. Specifically, generative pretext tasks with the masked prediction (e.g., BERT) have become a de facto standard SSL practice in NLP. By contrast, early attempts at generative methods in vision have been buried by their discriminative counterparts (like contrastive learning); however, the success of mask image modeling has revived the masking autoencoder (often termed denoising autoencoder in the past). As a milestone to bridge the gap with BERT in NLP, masked autoencoder has attracted unprecedented attention for SSL in vision and beyond. This work conducts a comprehensive survey of masked autoencoders to shed insight on a promising direction of SSL. As the first to review SSL with masked autoencoders, this work focuses on its application in vision by discussing its historical developments, recent progress, and implications for diverse applications.