 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness May Be at Odds with Fairness: An Empirical Study on Class-wise Accuracy
Oct 26, 2020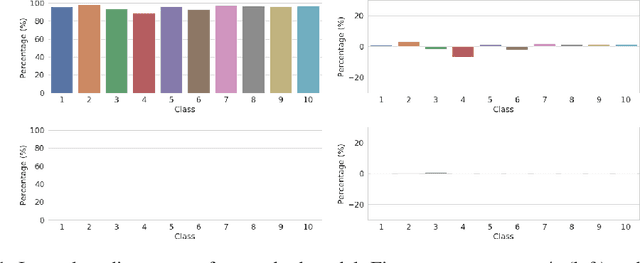
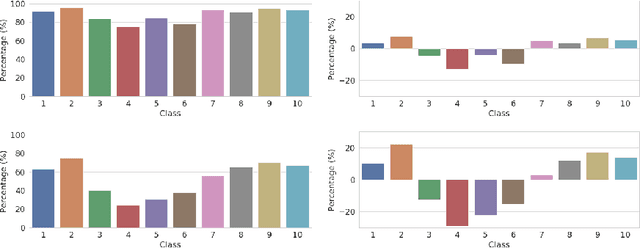
Recently, convolutional neural networks (CNNs) have made significant advancement, however, they are widely known to be vulnerable to adversarial attacks. Adversarial training is the most widely used technique for improving adversarial robustness to strong white-box attacks. Prior works have been evaluating and improving the model average robustness without per-class evaluation. The average evaluation alone might provide a false sense of robustness. For example, the attacker can focus on attacking the vulnerable class, which can be dangerous, especially, when the vulnerable class is a critical one, such as "human" in autonomous driving. In this preregistration submission, we propose an empirical study on the class-wise accuracy and robustness of adversarially trained models. Given that the CIFAR10 training dataset has an equal number of samples for each class, interestingly, preliminary results on it with Resnet18 show that there exists inter-class discrepancy for accuracy and robustness on standard models, for instance, "cat" is more vulnerable than other classes. Moreover, adversarial training increases inter-class discrepancy. Our work aims to investigate the following questions: (a) is the phenomenon of inter-class discrepancy universal for other classification benchmark datasets on other seminal model architectures with various optimization hyper-parameters? (b) If so, what can be possible explanations for the inter-class discrepancy? (c) Can the techniques proposed in the long tail classification be readily extended to adversarial training for addressing the inter-class discrepancy?
ResNet or DenseNet? Introducing Dense Shortcuts to ResNet
Oct 23, 2020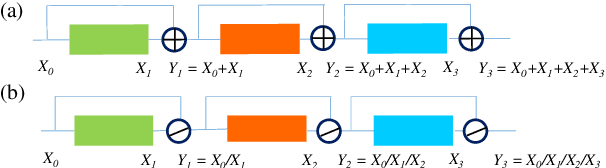

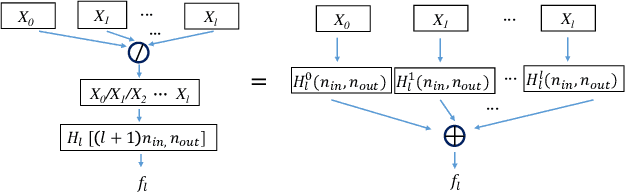

ResNet or DenseNet? Nowadays, most deep learning based approaches are implemented with seminal backbone networks, among them the two arguably most famous ones are ResNet and DenseNet. Despite their competitive performance and overwhelming popularity, inherent drawbacks exist for both of them. For ResNet, the identity shortcut that stabilizes training also limits its representation capacity, while DenseNet has a higher capacity with multi-layer feature concatenation. However, the dense concatenation causes a new problem of requiring high GPU memory and more training time. Partially due to this, it is not a trivial choice between ResNet and DenseNet. This paper provides a unified perspective of dense summation to analyze them, which facilitates a better understanding of their core difference. We further propose dense weighted normalized shortcuts as a solution to the dilemma between them. Our proposed dense shortcut inherits the design philosophy of simple design in ResNet and DenseNet. On several benchmark datasets, the experimental results show that the proposed DSNet achieves significantly better results than ResNet, and achieves comparable performance as DenseNet but requiring fewer computation resources.
Dense Relational Image Captioning via Multi-task Triple-Stream Networks
Oct 12, 2020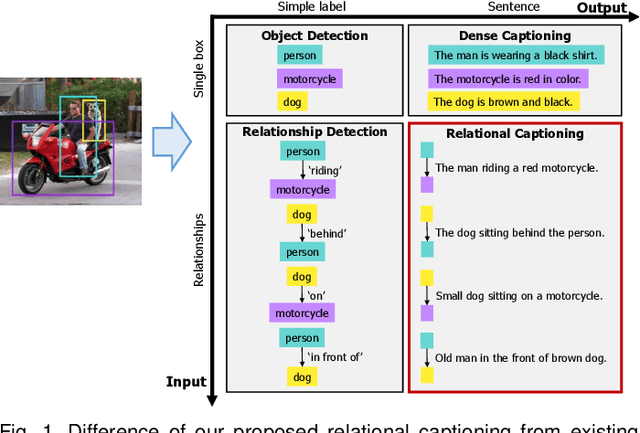
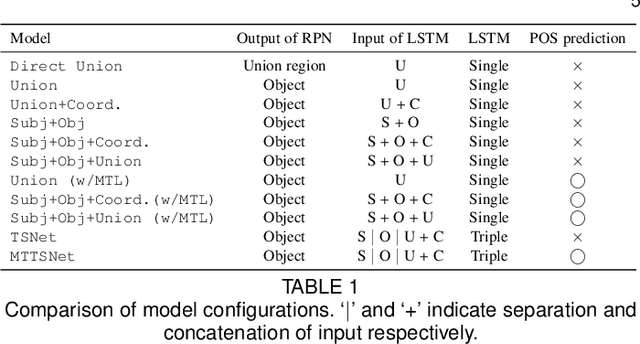
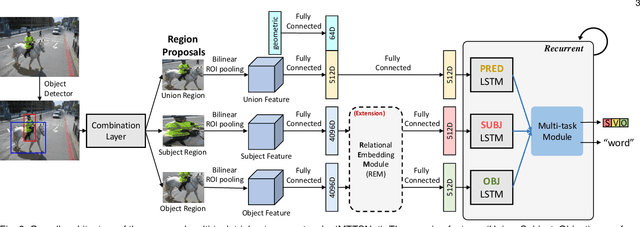
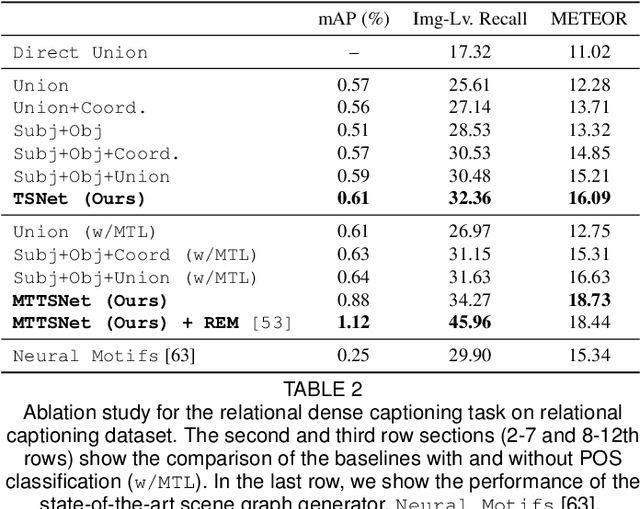
We introduce dense relational captioning, a novel image captioning task which aims to generate multiple captions with respect to relational information between objects in a visual scene. Relational captioning provides explicit descriptions of each relationship between object combinations. This framework is advantageous in both diversity and amount of information, leading to a comprehensive image understanding based on relationships, e.g., relational proposal generation. For relational understanding between objects, the part-of-speech (POS, i.e., subject-object-predicate categories) can be a valuable prior information to guide the causal sequence of words in a caption. We enforce our framework to not only learn to generate captions but also predict the POS of each word. To this end, we propose the multi-task triple-stream network (MTTSNet) which consists of three recurrent units responsible for each POS which is trained by jointly predicting the correct captions and POS for each word. In addition, we found that the performance of MTTSNet can be improved by modulating the object embeddings with an explicit relational module. We demonstrate that our proposed model can generate more diverse and richer captions, via extensive experimental analysis on large scale datasets and several metrics. We additionally extend analysis to an ablation study, applications on holistic image captioning, scene graph generation, and retrieval tasks.
Revisiting Batch Normalization for Improving Corruption Robustness
Oct 07, 2020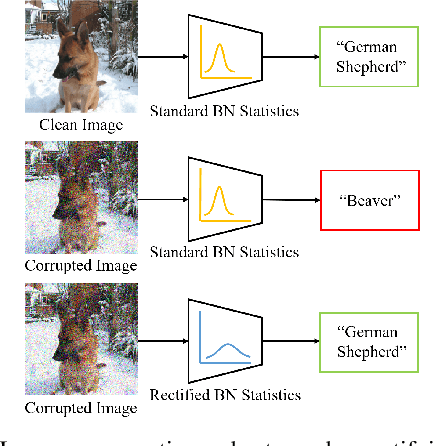
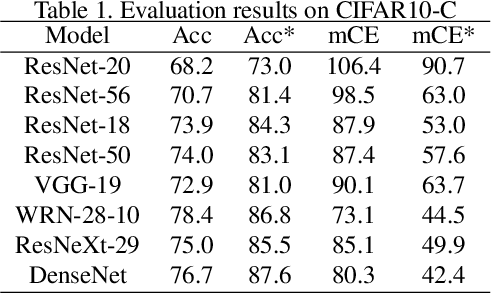
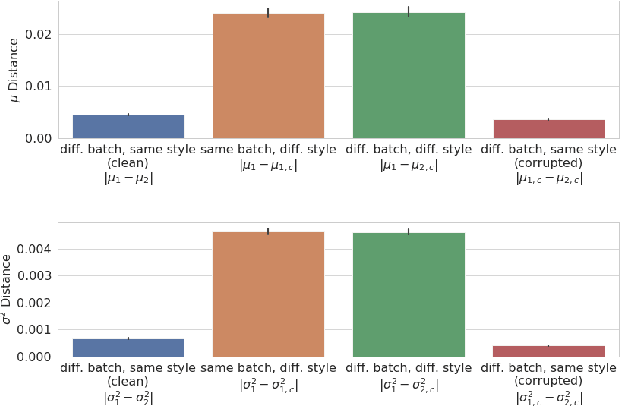
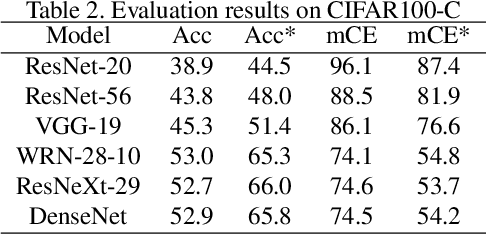
Modern deep neural networks (DNN) have demonstrated remarkable success in image recognition tasks when the test dataset and training dataset are from the same distribution. In practical applications, however, this assumption is often not valid and results in performance drop when there is a domain shift. For example, the performance of DNNs trained on clean images has been shown to decrease when the test images have common corruptions, limiting their use in performance-sensitive applications. In this work, we interpret corruption robustness as a domain shift problem and propose to rectify batch normalization (BN) statistics for improving model robustness. This shift from the clean domain to the corruption domain can be interpreted as a style shift that is represented by the BN statistics. Straightforwardly, adapting BN statistics is beneficial for rectifying this style shift. Specifically, we find that simply estimating and adapting the BN statistics on a few (32 for instance) representation samples, without retraining the model, improves the corruption robustness by a large margin on several benchmark datasets with a wide range of model architectures. For example, on ImageNet-C, statistics adaptation improves the top1 accuracy from 40.2% to 49%. Moreover, we find that this technique can further improve state-of-the-art robust models from 59.0% to 63.5%.
Batch Normalization Increases Adversarial Vulnerability: Disentangling Usefulness and Robustness of Model Features
Oct 07, 2020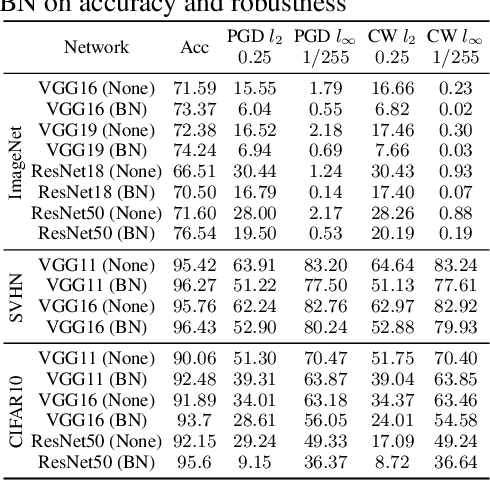
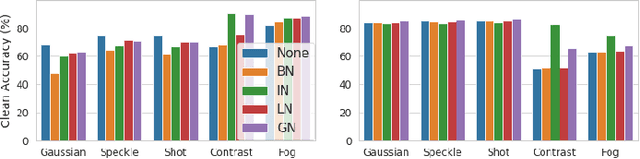
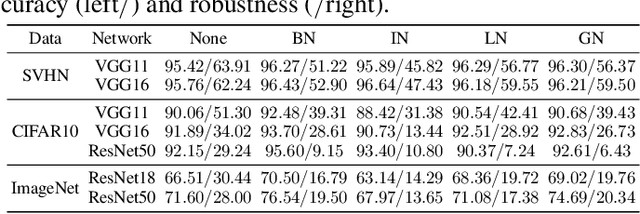
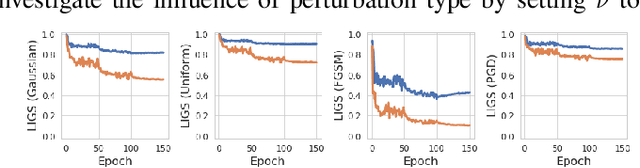
Batch normalization (BN) has been widely used in modern deep neural networks (DNNs) due to fast convergence. BN is observed to increase the model accuracy while at the cost of adversarial robustness. We conjecture that the increased adversarial vulnerability is caused by BN shifting the model to rely more on non-robust features (NRFs). Our exploration finds that other normalization techniques also increase adversarial vulnerability and our conjecture is also supported by analyzing the model corruption robustness and feature transferability. With a classifier DNN defined as a feature set $F$ we propose a framework for disentangling $F$ robust usefulness into $F$ usefulness and $F$ robustness. We adopt a local linearity based metric, termed LIGS, to define and quantify $F$ robustness. Measuring the $F$ robustness with the LIGS provides direct insight on the feature robustness shift independent of usefulness. Moreover, the LIGS trend during the whole training stage sheds light on the order of learned features, i.e. from RFs (robust features) to NRFs, or vice versa. Our work analyzes how BN and other factors influence the DNN from the feature perspective. Prior works mainly adopt accuracy to evaluate their influence regarding $F$ usefulness, while we believe evaluating $F$ robustness is equally important, for which our work fills the gap.
CD-UAP: Class Discriminative Universal Adversarial Perturbation
Oct 07, 2020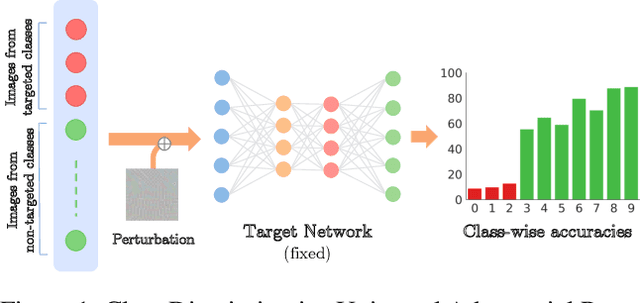
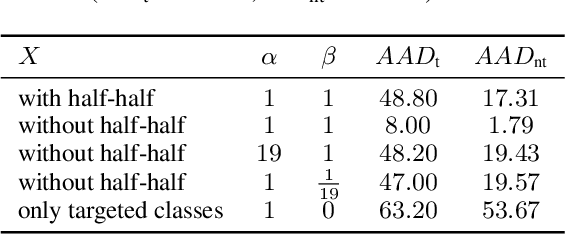
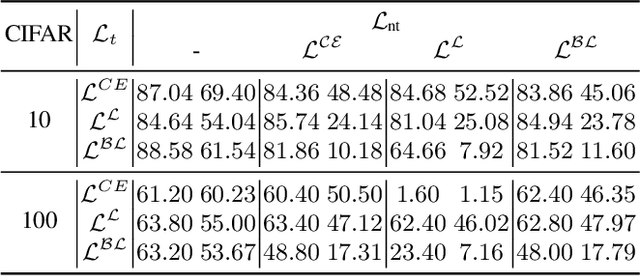
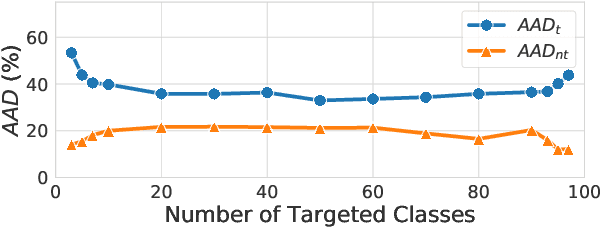
A single universal adversarial perturbation (UAP) can be added to all natural images to change most of their predicted class labels. It is of high practical relevance for an attacker to have flexible control over the targeted classes to be attacked, however, the existing UAP method attacks samples from all classes. In this work, we propose a new universal attack method to generate a single perturbation that fools a target network to misclassify only a chosen group of classes, while having limited influence on the remaining classes. Since the proposed attack generates a universal adversarial perturbation that is discriminative to targeted and non-targeted classes, we term it class discriminative universal adversarial perturbation (CD-UAP). We propose one simple yet effective algorithm framework, under which we design and compare various loss function configurations tailored for the class discriminative universal attack. The proposed approach has been evaluated with extensive experiments on various benchmark datasets. Additionally, our proposed approach achieves state-of-the-art performance for the original task of UAP attacking all classes, which demonstrates the effectiveness of our approach.
Double Targeted Universal Adversarial Perturbations
Oct 07, 2020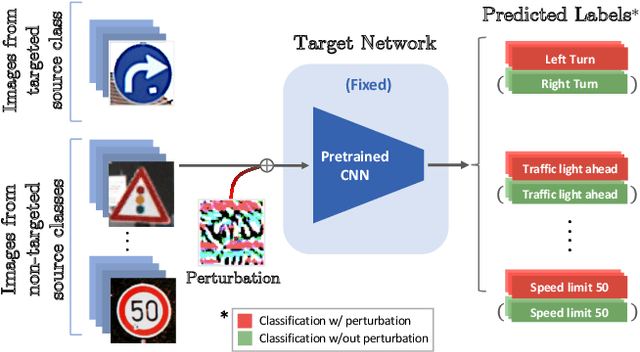
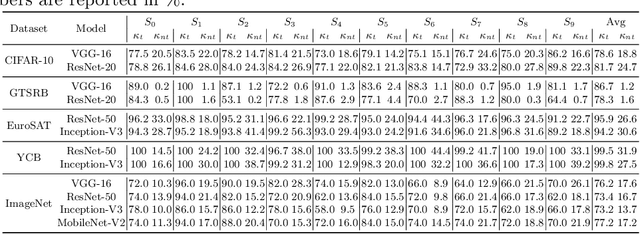


Despite their impressive performance, deep neural networks (DNNs) are widely known to be vulnerable to adversarial attacks, which makes it challenging for them to be deployed in security-sensitive applications, such as autonomous driving. Image-dependent perturbations can fool a network for one specific image, while universal adversarial perturbations are capable of fooling a network for samples from all classes without selection. We introduce a double targeted universal adversarial perturbations (DT-UAPs) to bridge the gap between the instance-discriminative image-dependent perturbations and the generic universal perturbations. This universal perturbation attacks one targeted source class to sink class, while having a limited adversarial effect on other non-targeted source classes, for avoiding raising suspicions. Targeting the source and sink class simultaneously, we term it double targeted attack (DTA). This provides an attacker with the freedom to perform precise attacks on a DNN model while raising little suspicion. We show the effectiveness of the proposed DTA algorithm on a wide range of datasets and also demonstrate its potential as a physical attack.
Detecting Human-Object Interactions with Action Co-occurrence Priors
Jul 27, 2020
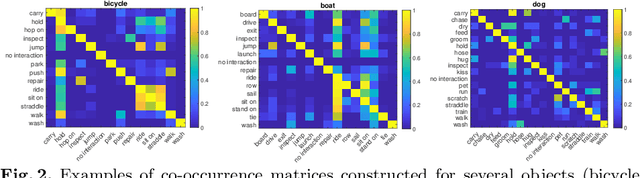
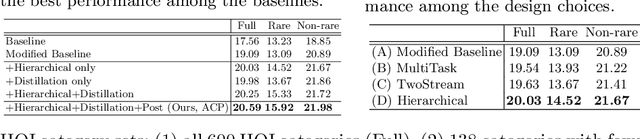
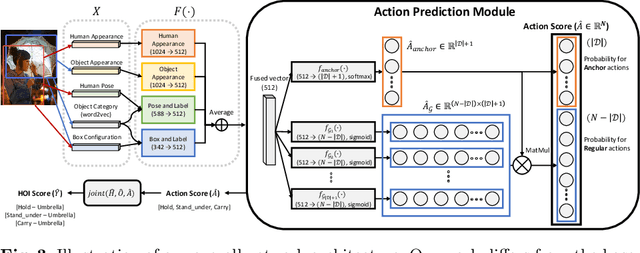
A common problem in human-object interaction (HOI) detection task is that numerous HOI classes have only a small number of labeled examples, resulting in training sets with a long-tailed distribution. The lack of positive labels can lead to low classification accuracy for these classes. Towards addressing this issue, we observe that there exist natural correlations and anti-correlations among human-object interactions. In this paper, we model the correlations as action co-occurrence matrices and present techniques to learn these priors and leverage them for more effective training, especially in rare classes. The utility of our approach is demonstrated experimentally, where the performance of our approach exceeds the state-of-the-art methods on both of the two leading HOI detection benchmark datasets, HICO-Det and V-COCO.
Non-Local Spatial Propagation Network for Depth Completion
Jul 20, 2020
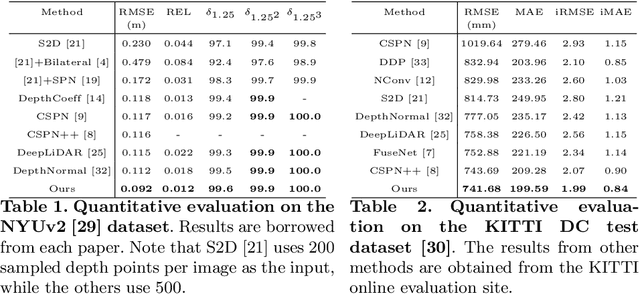
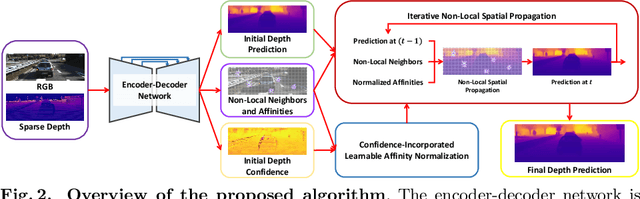
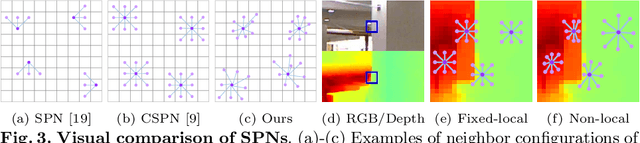
In this paper, we propose a robust and efficient end-to-end non-local spatial propagation network for depth completion. The proposed network takes RGB and sparse depth images as inputs and estimates non-local neighbors and their affinities of each pixel, as well as an initial depth map with pixel-wise confidences. The initial depth prediction is then iteratively refined by its confidence and non-local spatial propagation procedure based on the predicted non-local neighbors and corresponding affinities. Unlike previous algorithms that utilize fixed-local neighbors, the proposed algorithm effectively avoids irrelevant local neighbors and concentrates on relevant non-local neighbors during propagation. In addition, we introduce a learnable affinity normalization to better learn the affinity combinations compared to conventional methods. The proposed algorithm is inherently robust to the mixed-depth problem on depth boundaries, which is one of the major issues for existing depth estimation/completion algorithms. Experimental results on indoor and outdoor datasets demonstrate that the proposed algorithm is superior to conventional algorithms in terms of depth completion accuracy and robustness to the mixed-depth problem. Our implementation is publicly available on the project page.
Video Panoptic Segmentation
Jun 19, 2020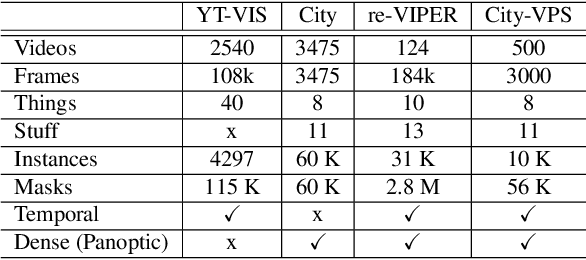
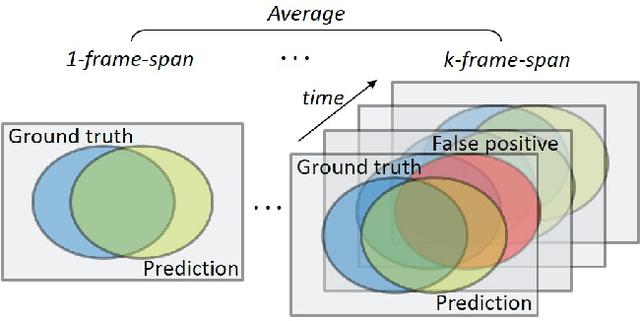
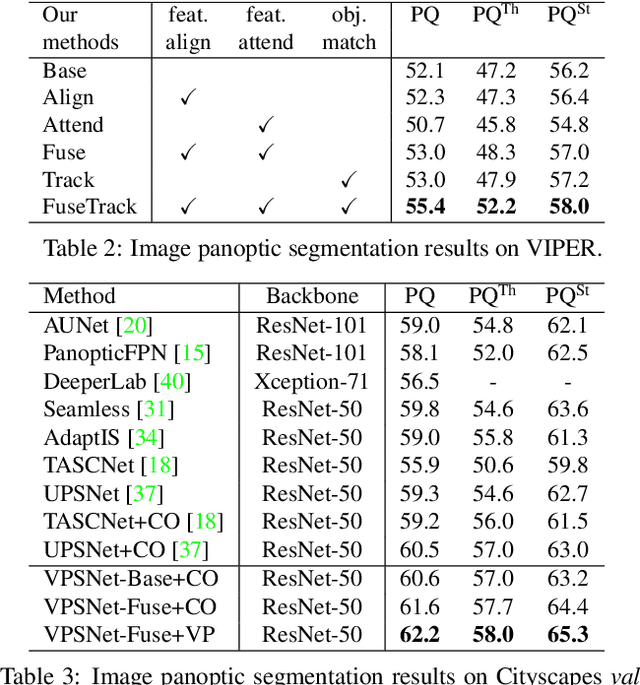
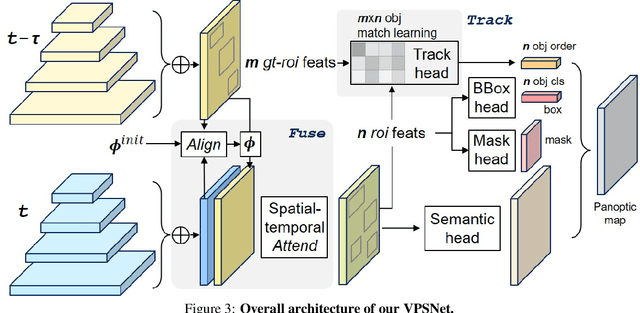
Panoptic segmentation has become a new standard of visual recognition task by unifying previous semantic segmentation and instance segmentation tasks in concert. In this paper, we propose and explore a new video extension of this task, called video panoptic segmentation. The task requires generating consistent panoptic segmentation as well as an association of instance ids across video frames. To invigorate research on this new task, we present two types of video panoptic datasets. The first is a re-organization of the synthetic VIPER dataset into the video panoptic format to exploit its large-scale pixel annotations. The second is a temporal extension on the Cityscapes val. set, by providing new video panoptic annotations (Cityscapes-VPS). Moreover, we propose a novel video panoptic segmentation network (VPSNet) which jointly predicts object classes, bounding boxes, masks, instance id tracking, and semantic segmentation in video frames. To provide appropriate metrics for this task, we propose a video panoptic quality (VPQ) metric and evaluate our method and several other baselines. Experimental results demonstrate the effectiveness of the presented two datasets. We achieve state-of-the-art results in image PQ on Cityscapes and also in VPQ on Cityscapes-VPS and VIPER datasets. The datasets and code are made publicly available.