 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCAD: Multimodal Context-Aware Audio Description Generation For Soccer
Nov 12, 2025Audio Descriptions (AD) are essential for making visual content accessible to individuals with visual impairments. Recent works have shown a promising step towards automating AD, but they have been limited to describing high-quality movie content using human-annotated ground truth AD in the process. In this work, we present an end-to-end pipeline, MCAD, that extends AD generation beyond movies to the domain of sports, with a focus on soccer games, without relying on ground truth AD. To address the absence of domain-specific AD datasets, we fine-tune a Video Large Language Model on publicly available movie AD datasets so that it learns the narrative structure and conventions of AD. During inference, MCAD incorporates multimodal contextual cues such as player identities, soccer events and actions, and commentary from the game. These cues, combined with input prompts to the fine-tuned VideoLLM, allow the system to produce complete AD text for each video segment. We further introduce a new evaluation metric, ARGE-AD, designed to accurately assess the quality of generated AD. ARGE-AD evaluates the generated AD for the presence of five characteristics: (i) usage of people's names, (ii) mention of actions and events, (iii) appropriate length of AD, (iv) absence of pronouns, and (v) overlap from commentary or subtitles. We present an in-depth analysis of our approach on both movie and soccer datasets. We also validate the use of this metric to quantitatively comment on the quality of generated AD using our metric across domains. Additionally, we contribute audio descriptions for 100 soccer game clips annotated by two AD experts.
AutoMisty: A Multi-Agent LLM Framework for Automated Code Generation in the Misty Social Robot
Mar 09, 2025The social robot's open API allows users to customize open-domain interactions. However, it remains inaccessible to those without programming experience. In this work, we introduce AutoMisty, the first multi-agent collaboration framework powered by large language models (LLMs), to enable the seamless generation of executable Misty robot code from natural language instructions. AutoMisty incorporates four specialized agent modules to manage task decomposition, assignment, problem-solving, and result synthesis. Each agent incorporates a two-layer optimization mechanism, with self-reflection for iterative refinement and human-in-the-loop for better alignment with user preferences. AutoMisty ensures a transparent reasoning process, allowing users to iteratively refine tasks through natural language feedback for precise execution. To evaluate AutoMisty's effectiveness, we designed a benchmark task set spanning four levels of complexity and conducted experiments in a real Misty robot environment. Extensive evaluations demonstrate that AutoMisty not only consistently generates high-quality code but also enables precise code control, significantly outperforming direct reasoning with ChatGPT-4o and ChatGPT-o1. All code, optimized APIs, and experimental videos will be publicly released through the webpage: https://wangxiaoshawn.github.io/AutoMisty.html
Towards the Synthesis of Non-speech Vocalizations
Oct 12, 2024In this report, we focus on the unconditional generation of infant cry sounds using the DiffWave framework, which has shown great promise in generating high-quality audio from noise. We use two distinct datasets of infant cries: the Baby Chillanto and the deBarbaro cry dataset. These datasets are used to train the DiffWave model to generate new cry sounds that maintain high fidelity and diversity. The focus here is on DiffWave's capability to handle the unconditional generation task.
Cross-Attention Based Influence Model for Manual and Nonmanual Sign Language Analysis
Sep 12, 2024Both manual (relating to the use of hands) and non-manual markers (NMM), such as facial expressions or mouthing cues, are important for providing the complete meaning of phrases in American Sign Language (ASL). Efforts have been made in advancing sign language to spoken/written language understanding, but most of these have primarily focused on manual features only. In this work, using advanced neural machine translation methods, we examine and report on the extent to which facial expressions contribute to understanding sign language phrases. We present a sign language translation architecture consisting of two-stream encoders, with one encoder handling the face and the other handling the upper body (with hands). We propose a new parallel cross-attention decoding mechanism that is useful for quantifying the influence of each input modality on the output. The two streams from the encoder are directed simultaneously to different attention stacks in the decoder. Examining the properties of the parallel cross-attention weights allows us to analyze the importance of facial markers compared to body and hand features during a translating task.
Ig3D: Integrating 3D Face Representations in Facial Expression Inference
Aug 29, 2024Reconstructing 3D faces with facial geometry from single images has allowed for major advances in animation, generative models, and virtual reality. However, this ability to represent faces with their 3D features is not as fully explored by the facial expression inference (FEI) community. This study therefore aims to investigate the impacts of integrating such 3D representations into the FEI task, specifically for facial expression classification and face-based valence-arousal (VA) estimation. To accomplish this, we first assess the performance of two 3D face representations (both based on the 3D morphable model, FLAME) for the FEI tasks. We further explore two fusion architectures, intermediate fusion and late fusion, for integrating the 3D face representations with existing 2D inference frameworks. To evaluate our proposed architecture, we extract the corresponding 3D representations and perform extensive tests on the AffectNet and RAF-DB datasets. Our experimental results demonstrate that our proposed method outperforms the state-of-the-art AffectNet VA estimation and RAF-DB classification tasks. Moreover, our method can act as a complement to other existing methods to boost performance in many emotion inference tasks.
Towards Open Domain Text-Driven Synthesis of Multi-Person Motions
May 28, 2024This work aims to generate natural and diverse group motions of multiple humans from textual descriptions. While single-person text-to-motion generation is extensively studied, it remains challenging to synthesize motions for more than one or two subjects from in-the-wild prompts, mainly due to the lack of available datasets. In this work, we curate human pose and motion datasets by estimating pose information from large-scale image and video datasets. Our models use a transformer-based diffusion framework that accommodates multiple datasets with any number of subjects or frames. Experiments explore both generation of multi-person static poses and generation of multi-person motion sequences. To our knowledge, our method is the first to generate multi-subject motion sequences with high diversity and fidelity from a large variety of textual prompts.
SignAvatar: Sign Language 3D Motion Reconstruction and Generation
May 13, 2024Achieving expressive 3D motion reconstruction and automatic generation for isolated sign words can be challenging, due to the lack of real-world 3D sign-word data, the complex nuances of signing motions, and the cross-modal understanding of sign language semantics. To address these challenges, we introduce SignAvatar, a framework capable of both word-level sign language reconstruction and generation. SignAvatar employs a transformer-based conditional variational autoencoder architecture, effectively establishing relationships across different semantic modalities. Additionally, this approach incorporates a curriculum learning strategy to enhance the model's robustness and generalization, resulting in more realistic motions. Furthermore, we contribute the ASL3DWord dataset, composed of 3D joint rotation data for the body, hands, and face, for unique sign words. We demonstrate the effectiveness of SignAvatar through extensive experiments, showcasing its superior reconstruction and automatic generation capabilities. The code and dataset are available on the project page.
Language-guided Human Motion Synthesis with Atomic Actions
Aug 18, 2023Language-guided human motion synthesis has been a challenging task due to the inherent complexity and diversity of human behaviors. Previous methods face limitations in generalization to novel actions, often resulting in unrealistic or incoherent motion sequences. In this paper, we propose ATOM (ATomic mOtion Modeling) to mitigate this problem, by decomposing actions into atomic actions, and employing a curriculum learning strategy to learn atomic action composition. First, we disentangle complex human motions into a set of atomic actions during learning, and then assemble novel actions using the learned atomic actions, which offers better adaptability to new actions. Moreover, we introduce a curriculum learning training strategy that leverages masked motion modeling with a gradual increase in the mask ratio, and thus facilitates atomic action assembly. This approach mitigates the overfitting problem commonly encountered in previous methods while enforcing the model to learn better motion representations. We demonstrate the effectiveness of ATOM through extensive experiments, including text-to-motion and action-to-motion synthesis tasks. We further illustrate its superiority in synthesizing plausible and coherent text-guided human motion sequences.
SignNet: Single Channel Sign Generation using Metric Embedded Learning
Dec 06, 2022A true interpreting agent not only understands sign language and translates to text, but also understands text and translates to signs. Much of the AI work in sign language translation to date has focused mainly on translating from signs to text. Towards the latter goal, we propose a text-to-sign translation model, SignNet, which exploits the notion of similarity (and dissimilarity) of visual signs in translating. This module presented is only one part of a dual-learning two task process involving text-to-sign (T2S) as well as sign-to-text (S2T). We currently implement SignNet as a single channel architecture so that the output of the T2S task can be fed into S2T in a continuous dual learning framework. By single channel, we refer to a single modality, the body pose joints. In this work, we present SignNet, a T2S task using a novel metric embedding learning process, to preserve the distances between sign embeddings relative to their dissimilarity. We also describe how to choose positive and negative examples of signs for similarity testing. From our analysis, we observe that metric embedding learning-based model perform significantly better than the other models with traditional losses, when evaluated using BLEU scores. In the task of gloss to pose, SignNet performed as well as its state-of-the-art (SoTA) counterparts and outperformed them in the task of text to pose, by showing noteworthy enhancements in BLEU 1 - BLEU 4 scores (BLEU 1: 31->39; ~26% improvement and BLEU 4: 10.43->11.84; ~14\% improvement) when tested on the popular RWTH PHOENIX-Weather-2014T benchmark dataset
A Probabilistic Model Of Interaction Dynamics for Dyadic Face-to-Face Settings
Jul 10, 2022
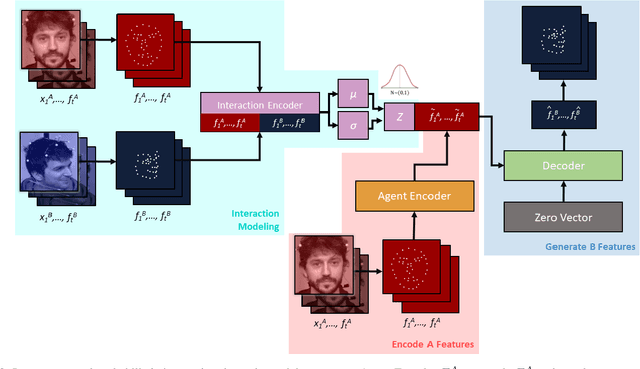


Natural conversations between humans often involve a large number of non-verbal nuanced expressions, displayed at key times throughout the conversation. Understanding and being able to model these complex interactions is essential for creating realistic human-agent communication, whether in the virtual or physical world. As social robots and intelligent avatars emerge in popularity and utility, being able to realistically model and generate these dynamic expressions throughout conversations is critical. We develop a probabilistic model to capture the interaction dynamics between pairs of participants in a face-to-face setting, allowing for the encoding of synchronous expressions between the interlocutors. This interaction encoding is then used to influence the generation when predicting one agent's future dynamics, conditioned on the other's current dynamics. FLAME features are extracted from videos containing natural conversations between subjects to train our interaction model. We successfully assess the efficacy of our proposed model via quantitative metrics and qualitative metrics, and show that it successfully captures the dynamics of a pair of interacting dyads. We also test the model with a never-before-seen parent-infant dataset comprising of two different modes of communication between the dyads, and show that our model successfully delineates between the modes, based on their interacting dynamics.