 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Performance Predictors: Learning When to Escalate in Hybrid Human-AI Moderation Systems
Jan 11, 2026As LLMs are increasingly integrated into human-in-the-loop content moderation systems, a central challenge is deciding when their outputs can be trusted versus when escalation for human review is preferable. We propose a novel framework for supervised LLM uncertainty quantification, learning a dedicated meta-model based on LLM Performance Predictors (LPPs) derived from LLM outputs: log-probabilities, entropy, and novel uncertainty attribution indicators. We demonstrate that our method enables cost-aware selective classification in real-world human-AI workflows: escalating high-risk cases while automating the rest. Experiments across state-of-the-art LLMs, including both off-the-shelf (Gemini, GPT) and open-source (Llama, Qwen), on multimodal and multilingual moderation tasks, show significant improvements over existing uncertainty estimators in accuracy-cost trade-offs. Beyond uncertainty estimation, the LPPs enhance explainability by providing new insights into failure conditions (e.g., ambiguous content vs. under-specified policy). This work establishes a principled framework for uncertainty-aware, scalable, and responsible human-AI moderation workflows.
AI vs. Human Moderators: A Comparative Evaluation of Multimodal LLMs in Content Moderation for Brand Safety
Aug 07, 2025As the volume of video content online grows exponentially, the demand for moderation of unsafe videos has surpassed human capabilities, posing both operational and mental health challenges. While recent studies demonstrated the merits of Multimodal Large Language Models (MLLMs) in various video understanding tasks, their application to multimodal content moderation, a domain that requires nuanced understanding of both visual and textual cues, remains relatively underexplored. In this work, we benchmark the capabilities of MLLMs in brand safety classification, a critical subset of content moderation for safe-guarding advertising integrity. To this end, we introduce a novel, multimodal and multilingual dataset, meticulously labeled by professional reviewers in a multitude of risk categories. Through a detailed comparative analysis, we demonstrate the effectiveness of MLLMs such as Gemini, GPT, and Llama in multimodal brand safety, and evaluate their accuracy and cost efficiency compared to professional human reviewers. Furthermore, we present an in-depth discussion shedding light on limitations of MLLMs and failure cases. We are releasing our dataset alongside this paper to facilitate future research on effective and responsible brand safety and content moderation.
Sequential Modeling with Multiple Attributes for Watchlist Recommendation in E-Commerce
Oct 24, 2021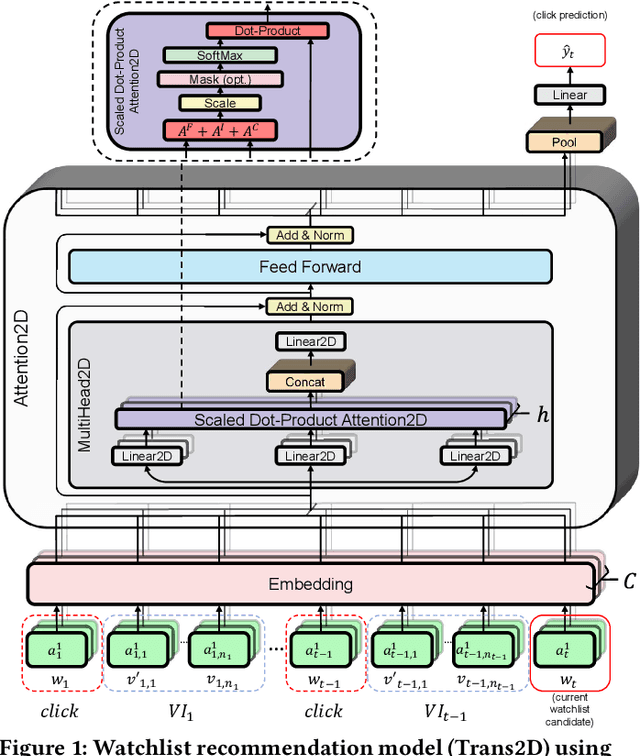
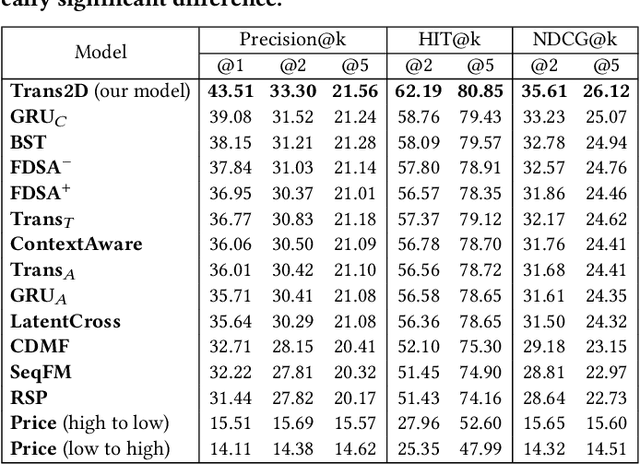

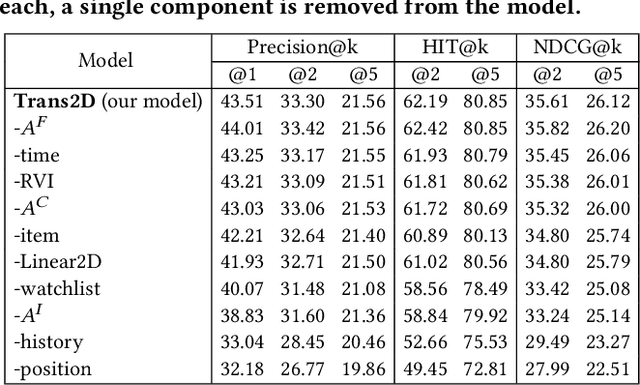
In e-commerce, the watchlist enables users to track items over time and has emerged as a primary feature, playing an important role in users' shopping journey. Watchlist items typically have multiple attributes whose values may change over time (e.g., price, quantity). Since many users accumulate dozens of items on their watchlist, and since shopping intents change over time, recommending the top watchlist items in a given context can be valuable. In this work, we study the watchlist functionality in e-commerce and introduce a novel watchlist recommendation task. Our goal is to prioritize which watchlist items the user should pay attention to next by predicting the next items the user will click. We cast this task as a specialized sequential recommendation task and discuss its characteristics. Our proposed recommendation model, Trans2D, is built on top of the Transformer architecture, where we further suggest a novel extended attention mechanism (Attention2D) that allows to learn complex item-item, attribute-attribute and item-attribute patterns from sequential-data with multiple item attributes. Using a large-scale watchlist dataset from eBay, we evaluate our proposed model, where we demonstrate its superiority compared to multiple state-of-the-art baselines, many of which are adapted for this task.
PreSizE: Predicting Size in E-Commerce using Transformers
May 04, 2021
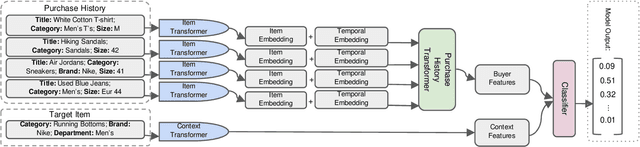
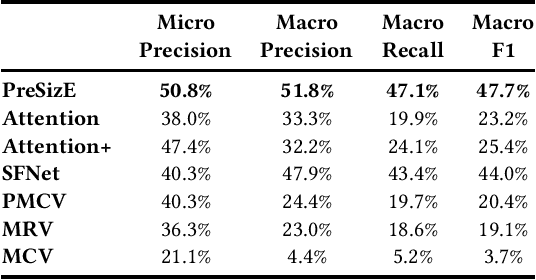
Recent advances in the e-commerce fashion industry have led to an exploration of novel ways to enhance buyer experience via improved personalization. Predicting a proper size for an item to recommend is an important personalization challenge, and is being studied in this work. Earlier works in this field either focused on modeling explicit buyer fitment feedback or modeling of only a single aspect of the problem (e.g., specific category, brand, etc.). More recent works proposed richer models, either content-based or sequence-based, better accounting for content-based aspects of the problem or better modeling the buyer's online journey. However, both these approaches fail in certain scenarios: either when encountering unseen items (sequence-based models) or when encountering new users (content-based models). To address the aforementioned gaps, we propose PreSizE - a novel deep learning framework which utilizes Transformers for accurate size prediction. PreSizE models the effect of both content-based attributes, such as brand and category, and the buyer's purchase history on her size preferences. Using an extensive set of experiments on a large-scale e-commerce dataset, we demonstrate that PreSizE is capable of achieving superior prediction performance compared to previous state-of-the-art baselines. By encoding item attributes, PreSizE better handles cold-start cases with unseen items, and cases where buyers have little past purchase data. As a proof of concept, we demonstrate that size predictions made by PreSizE can be effectively integrated into an existing production recommender system yielding very effective features and significantly improving recommendations.
A Multi-Modal Method for Satire Detection using Textual and Visual Cues
Oct 13, 2020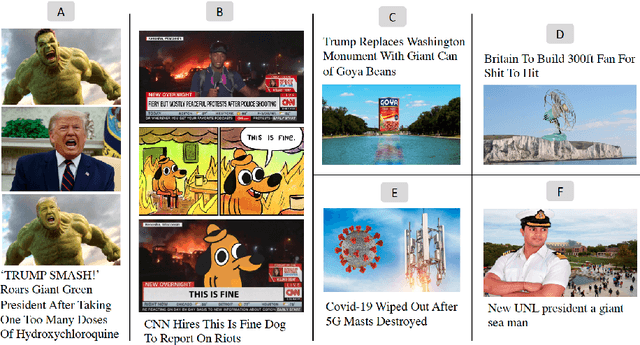
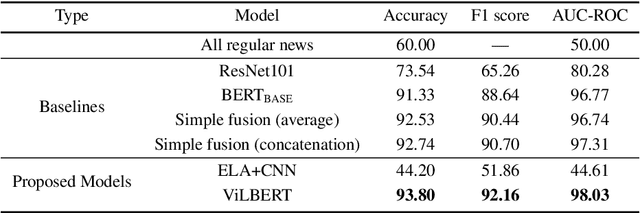

Satire is a form of humorous critique, but it is sometimes misinterpreted by readers as legitimate news, which can lead to harmful consequences. We observe that the images used in satirical news articles often contain absurd or ridiculous content and that image manipulation is used to create fictional scenarios. While previous work have studied text-based methods, in this work we propose a multi-modal approach based on state-of-the-art visiolinguistic model ViLBERT. To this end, we create a new dataset consisting of images and headlines of regular and satirical news for the task of satire detection. We fine-tune ViLBERT on the dataset and train a convolutional neural network that uses an image forensics technique. Evaluation on the dataset shows that our proposed multi-modal approach outperforms image-only, text-only, and simple fusion baselines.
Identifying Nuances in Fake News vs. Satire: Using Semantic and Linguistic Cues
Nov 05, 2019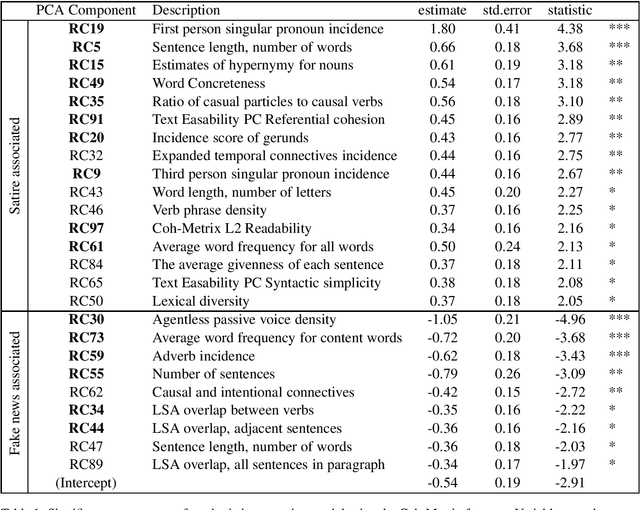
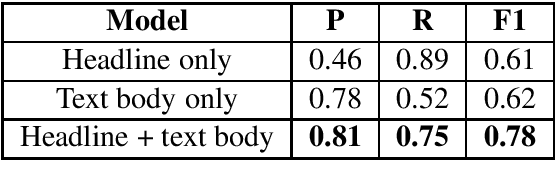

The blurry line between nefarious fake news and protected-speech satire has been a notorious struggle for social media platforms. Further to the efforts of reducing exposure to misinformation on social media, purveyors of fake news have begun to masquerade as satire sites to avoid being demoted. In this work, we address the challenge of automatically classifying fake news versus satire. Previous work have studied whether fake news and satire can be distinguished based on language differences. Contrary to fake news, satire stories are usually humorous and carry some political or social message. We hypothesize that these nuances could be identified using semantic and linguistic cues. Consequently, we train a machine learning method using semantic representation, with a state-of-the-art contextual language model, and with linguistic features based on textual coherence metrics. Empirical evaluation attests to the merits of our approach compared to the language-based baseline and sheds light on the nuances between fake news and satire. As avenues for future work, we consider studying additional linguistic features related to the humor aspect, and enriching the data with current news events, to help identify a political or social message.