 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Prevalence Estimation with Multicalibrated LLMs
Apr 23, 2026Estimating the prevalence of a category in a population using imperfect measurement devices (diagnostic tests, classifiers, or large language models) is fundamental to science, public health, and online trust and safety. Standard approaches correct for known device error rates but assume these rates remain stable across populations. We show this assumption fails under covariate shift and that multicalibration, which enforces calibration conditional on the input features rather than just on average, is sufficient for unbiased prevalence estimation under such shift. Standard calibration and quantification methods fail to provide this guarantee. Our work connects recent theoretical work on fairness to a longstanding measurement problem spanning nearly all academic disciplines. A simulation confirms that standard methods exhibit bias growing with shift magnitude, while a multicalibrated estimator maintains near-zero bias. While we focus the discussion mostly on LLMs, our theoretical results apply to any classification model. Two empirical applications -- estimating employment prevalence across U.S. states using the American Community Survey, and classifying political texts across four countries using an LLM -- demonstrate that multicalibration substantially reduces bias in practice, while highlighting that calibration data should cover the key feature dimensions along which target populations may differ.
On the Convergence of Multicalibration Gradient Boosting
Feb 06, 2026Multicalibration gradient boosting has recently emerged as a scalable method that empirically produces approximately multicalibrated predictors and has been deployed at web scale. Despite this empirical success, its convergence properties are not well understood. In this paper, we bridge the gap by providing convergence guarantees for multicalibration gradient boosting in regression with squared-error loss. We show that the magnitude of successive prediction updates decays at $O(1/\sqrt{T})$, which implies the same convergence rate bound for the multicalibration error over rounds. Under additional smoothness assumptions on the weak learners, this rate improves to linear convergence. We further analyze adaptive variants, showing local quadratic convergence of the training loss, and we study rescaling schemes that preserve convergence. Experiments on real-world datasets support our theory and clarify the regimes in which the method achieves fast convergence and strong multicalibration.
Multicalibration yields better matchings
Nov 14, 2025
Consider the problem of finding the best matching in a weighted graph where we only have access to predictions of the actual stochastic weights, based on an underlying context. If the predictor is the Bayes optimal one, then computing the best matching based on the predicted weights is optimal. However, in practice, this perfect information scenario is not realistic. Given an imperfect predictor, a suboptimal decision rule may compensate for the induced error and thus outperform the standard optimal rule. In this paper, we propose multicalibration as a way to address this problem. This fairness notion requires a predictor to be unbiased on each element of a family of protected sets of contexts. Given a class of matching algorithms $\mathcal C$ and any predictor $γ$ of the edge-weights, we show how to construct a specific multicalibrated predictor $\hat γ$, with the following property. Picking the best matching based on the output of $\hat γ$ is competitive with the best decision rule in $\mathcal C$ applied onto the original predictor $γ$. We complement this result by providing sample complexity bounds.
Measuring multi-calibration
Jun 12, 2025A suitable scalar metric can help measure multi-calibration, defined as follows. When the expected values of observed responses are equal to corresponding predicted probabilities, the probabilistic predictions are known as "perfectly calibrated." When the predicted probabilities are perfectly calibrated simultaneously across several subpopulations, the probabilistic predictions are known as "perfectly multi-calibrated." In practice, predicted probabilities are seldom perfectly multi-calibrated, so a statistic measuring the distance from perfect multi-calibration is informative. A recently proposed metric for calibration, based on the classical Kuiper statistic, is a natural basis for a new metric of multi-calibration and avoids well-known problems of metrics based on binning or kernel density estimation. The newly proposed metric weights the contributions of different subpopulations in proportion to their signal-to-noise ratios; data analyses' ablations demonstrate that the metric becomes noisy when omitting the signal-to-noise ratios from the metric. Numerical examples on benchmark data sets illustrate the new metric.
On the convergence of loss and uncertainty-based active learning algorithms
Dec 21, 2023We study convergence rates of loss and uncertainty-based active learning algorithms under various assumptions. First, we provide a set of conditions under which a convergence rate guarantee holds, and use this for linear classifiers and linearly separable datasets to show convergence rate guarantees for loss-based sampling and different loss functions. Second, we provide a framework that allows us to derive convergence rate bounds for loss-based sampling by deploying known convergence rate bounds for stochastic gradient descent algorithms. Third, and last, we propose an active learning algorithm that combines sampling of points and stochastic Polyak's step size. We show a condition on the sampling that ensures a convergence rate guarantee for this algorithm for smooth convex loss functions. Our numerical results demonstrate efficiency of our proposed algorithm.
Using Neural Generative Models to Release Synthetic Twitter Corpora with Reduced Stylometric Identifiability of Users
May 30, 2018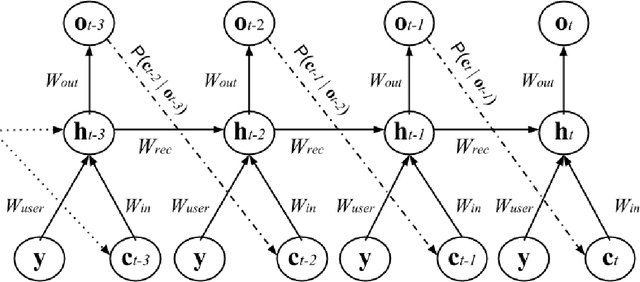
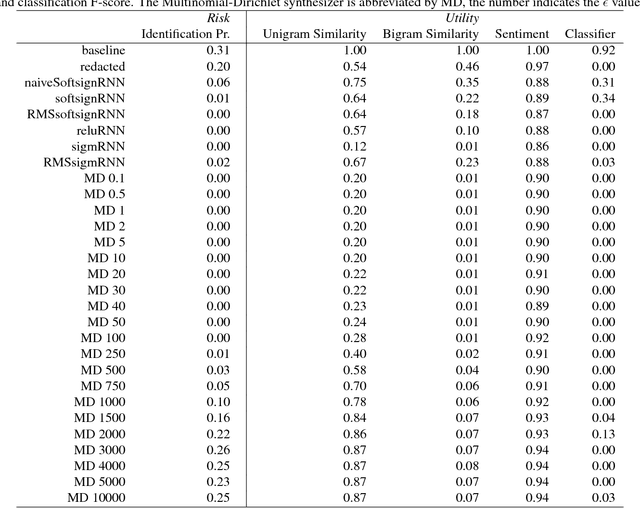
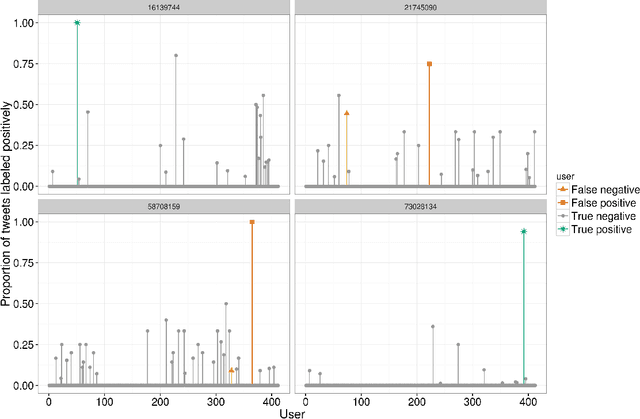
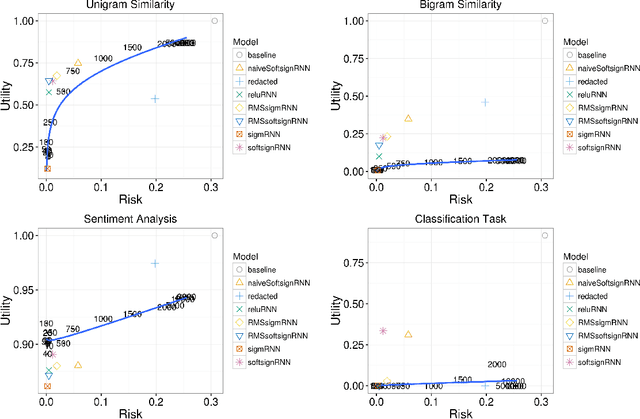
We present a method for generating synthetic versions of Twitter data using neural generative models. The goal is protecting individuals in the source data from stylometric re-identification attacks while still releasing data that carries research value. Specifically, we generate tweet corpora that maintain user-level word distributions by augmenting the neural language models with user-specific components. We compare our approach to two standard text data protection methods: redaction and iterative translation. We evaluate the three methods on measures of risk and utility. We define risk following the stylometric models of re-identification, and we define utility based on two general word distribution measures and two common text analysis research tasks. We find that neural models are able to significantly lower risk over previous methods with little cost to utility. We also demonstrate that the neural models allow data providers to actively control the risk-utility trade-off through model tuning parameters. This work presents promising results for a new tool addressing the problem of privacy for free text and sharing social media data in a way that respects privacy and is ethically responsible.