 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2023 Task 12: Sentiment Analysis for African Languages
May 01, 2023



We present the first Africentric SemEval Shared task, Sentiment Analysis for African Languages (AfriSenti-SemEval) - The dataset is available at https://github.com/afrisenti-semeval/afrisent-semeval-2023. AfriSenti-SemEval is a sentiment classification challenge in 14 African languages: Amharic, Algerian Arabic, Hausa, Igbo, Kinyarwanda, Moroccan Arabic, Mozambican Portuguese, Nigerian Pidgin, Oromo, Swahili, Tigrinya, Twi, Xitsonga, and Yor\`ub\'a (Muhammad et al., 2023), using data labeled with 3 sentiment classes. We present three subtasks: (1) Task A: monolingual classification, which received 44 submissions; (2) Task B: multilingual classification, which received 32 submissions; and (3) Task C: zero-shot classification, which received 34 submissions. The best performance for tasks A and B was achieved by NLNDE team with 71.31 and 75.06 weighted F1, respectively. UCAS-IIE-NLP achieved the best average score for task C with 58.15 weighted F1. We describe the various approaches adopted by the top 10 systems and their approaches.
AfriSenti: A Twitter Sentiment Analysis Benchmark for African Languages
Feb 17, 2023



Africa is home to over 2000 languages from over six language families and has the highest linguistic diversity among all continents. This includes 75 languages with at least one million speakers each. Yet, there is little NLP research conducted on African languages. Crucial in enabling such research is the availability of high-quality annotated datasets. In this paper, we introduce AfriSenti, which consists of 14 sentiment datasets of 110,000+ tweets in 14 African languages (Amharic, Algerian Arabic, Hausa, Igbo, Kinyarwanda, Moroccan Arabic, Mozambican Portuguese, Nigerian Pidgin, Oromo, Swahili, Tigrinya, Twi, Xitsonga, and Yor\`ub\'a) from four language families annotated by native speakers. The data is used in SemEval 2023 Task 12, the first Afro-centric SemEval shared task. We describe the data collection methodology, annotation process, and related challenges when curating each of the datasets. We conduct experiments with different sentiment classification baselines and discuss their usefulness. We hope AfriSenti enables new work on under-represented languages. The dataset is available at https://github.com/afrisenti-semeval/afrisent-semeval-2023 and can also be loaded as a huggingface datasets (https://huggingface.co/datasets/shmuhammad/AfriSenti).
Hausa Visual Genome: A Dataset for Multi-Modal English to Hausa Machine Translation
May 06, 2022
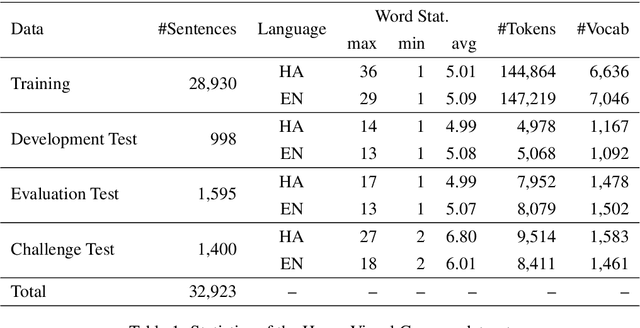

Multi-modal Machine Translation (MMT) enables the use of visual information to enhance the quality of translations. The visual information can serve as a valuable piece of context information to decrease the ambiguity of input sentences. Despite the increasing popularity of such a technique, good and sizeable datasets are scarce, limiting the full extent of their potential. Hausa, a Chadic language, is a member of the Afro-Asiatic language family. It is estimated that about 100 to 150 million people speak the language, with more than 80 million indigenous speakers. This is more than any of the other Chadic languages. Despite a large number of speakers, the Hausa language is considered low-resource in natural language processing (NLP). This is due to the absence of sufficient resources to implement most NLP tasks. While some datasets exist, they are either scarce, machine-generated, or in the religious domain. Therefore, there is a need to create training and evaluation data for implementing machine learning tasks and bridging the research gap in the language. This work presents the Hausa Visual Genome (HaVG), a dataset that contains the description of an image or a section within the image in Hausa and its equivalent in English. To prepare the dataset, we started by translating the English description of the images in the Hindi Visual Genome (HVG) into Hausa automatically. Afterward, the synthetic Hausa data was carefully post-edited considering the respective images. The dataset comprises 32,923 images and their descriptions that are divided into training, development, test, and challenge test set. The Hausa Visual Genome is the first dataset of its kind and can be used for Hausa-English machine translation, multi-modal research, and image description, among various other natural language processing and generation tasks.