 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Language Model Deployment with Risk Cards
Mar 31, 2023

This paper introduces RiskCards, a framework for structured assessment and documentation of risks associated with an application of language models. As with all language, text generated by language models can be harmful, or used to bring about harm. Automating language generation adds both an element of scale and also more subtle or emergent undesirable tendencies to the generated text. Prior work establishes a wide variety of language model harms to many different actors: existing taxonomies identify categories of harms posed by language models; benchmarks establish automated tests of these harms; and documentation standards for models, tasks and datasets encourage transparent reporting. However, there is no risk-centric framework for documenting the complexity of a landscape in which some risks are shared across models and contexts, while others are specific, and where certain conditions may be required for risks to manifest as harms. RiskCards address this methodological gap by providing a generic framework for assessing the use of a given language model in a given scenario. Each RiskCard makes clear the routes for the risk to manifest harm, their placement in harm taxonomies, and example prompt-output pairs. While RiskCards are designed to be open-source, dynamic and participatory, we present a "starter set" of RiskCards taken from a broad literature survey, each of which details a concrete risk presentation. Language model RiskCards initiate a community knowledge base which permits the mapping of risks and harms to a specific model or its application scenario, ultimately contributing to a better, safer and shared understanding of the risk landscape.
AfriSenti: A Twitter Sentiment Analysis Benchmark for African Languages
Feb 17, 2023



Africa is home to over 2000 languages from over six language families and has the highest linguistic diversity among all continents. This includes 75 languages with at least one million speakers each. Yet, there is little NLP research conducted on African languages. Crucial in enabling such research is the availability of high-quality annotated datasets. In this paper, we introduce AfriSenti, which consists of 14 sentiment datasets of 110,000+ tweets in 14 African languages (Amharic, Algerian Arabic, Hausa, Igbo, Kinyarwanda, Moroccan Arabic, Mozambican Portuguese, Nigerian Pidgin, Oromo, Swahili, Tigrinya, Twi, Xitsonga, and Yor\`ub\'a) from four language families annotated by native speakers. The data is used in SemEval 2023 Task 12, the first Afro-centric SemEval shared task. We describe the data collection methodology, annotation process, and related challenges when curating each of the datasets. We conduct experiments with different sentiment classification baselines and discuss their usefulness. We hope AfriSenti enables new work on under-represented languages. The dataset is available at https://github.com/afrisenti-semeval/afrisent-semeval-2023 and can also be loaded as a huggingface datasets (https://huggingface.co/datasets/shmuhammad/AfriSenti).
From Once Upon a Time to Happily Ever After: Tracking Emotions in Novels and Fairy Tales
Sep 23, 2013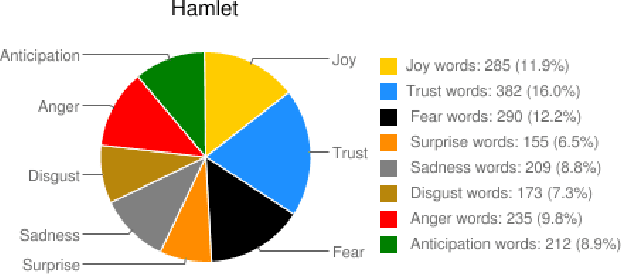

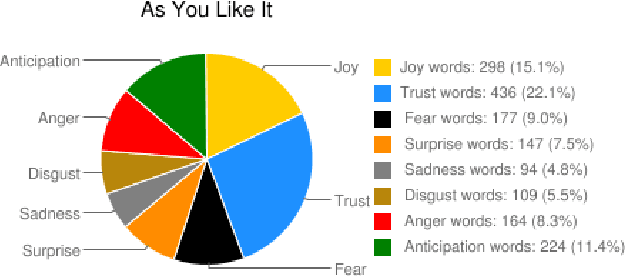

Today we have access to unprecedented amounts of literary texts. However, search still relies heavily on key words. In this paper, we show how sentiment analysis can be used in tandem with effective visualizations to quantify and track emotions in both individual books and across very large collections. We introduce the concept of emotion word density, and using the Brothers Grimm fairy tales as example, we show how collections of text can be organized for better search. Using the Google Books Corpus we show how to determine an entity's emotion associations from co-occurring words. Finally, we compare emotion words in fairy tales and novels, to show that fairy tales have a much wider range of emotion word densities than novels.
Colourful Language: Measuring Word-Colour Associations
Sep 20, 2013
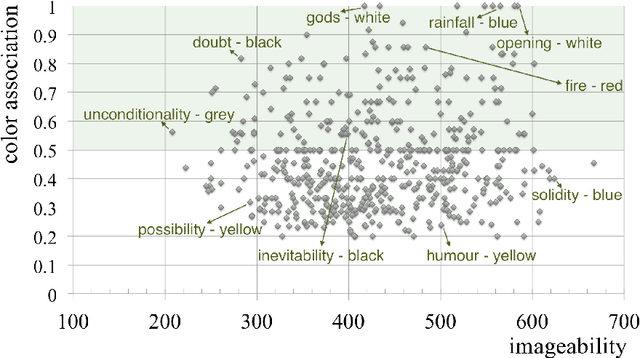
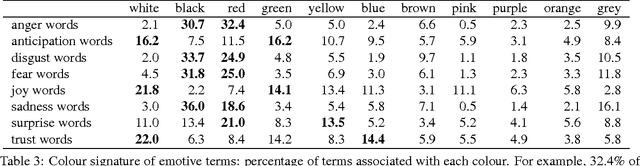
Since many real-world concepts are associated with colour, for example danger with red, linguistic information is often complimented with the use of appropriate colours in information visualization and product marketing. Yet, there is no comprehensive resource that captures concept-colour associations. We present a method to create a large word-colour association lexicon by crowdsourcing. We focus especially on abstract concepts and emotions to show that even though they cannot be physically visualized, they too tend to have strong colour associations. Finally, we show how word-colour associations manifest themselves in language, and quantify usefulness of co-occurrence and polarity cues in automatically detecting colour associations.
* arXiv admin note: substantial text overlap with arXiv:1309.5391