 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Datalog Reasoning with Hypertree Decompositions
May 15, 2023Datalog reasoning based on the semina\"ive evaluation strategy evaluates rules using traditional join plans, which often leads to redundancy and inefficiency in practice, especially when the rules are complex. Hypertree decompositions help identify efficient query plans and reduce similar redundancy in query answering. However, it is unclear how this can be applied to materialisation and incremental reasoning with recursive Datalog programs. Moreover, hypertree decompositions require additional data structures and thus introduce nonnegligible overhead in both runtime and memory consumption. In this paper, we provide algorithms that exploit hypertree decompositions for the materialisation and incremental evaluation of Datalog programs. Furthermore, we combine this approach with standard Datalog reasoning algorithms in a modular fashion so that the overhead caused by the decompositions is reduced. Our empirical evaluation shows that, when the program contains complex rules, the combined approach is usually significantly faster than the baseline approach, sometimes by orders of magnitude.
Reveal the Unknown: Out-of-Knowledge-Base Mention Discovery with Entity Linking
Feb 14, 2023



Discovering entity mentions that are out of a Knowledge Base (KB) from texts plays a critical role in KB maintenance, but has not yet been fully explored. The current methods are mostly limited to the simple threshold-based approach and feature-based classification; the datasets for evaluation are relatively rare. In this work, we propose BLINKout, a new BERT-based Entity Linking (EL) method which can identify mentions that do not have a corresponding KB entity by matching them to a special NIL entity. To this end, we integrate novel techniques including NIL representation, NIL classification, and synonym enhancement. We also propose Ontology Pruning and Versioning strategies to construct out-of-KB mentions from normal, in-KB EL datasets. Results on four datasets of clinical notes and publications show that BLINKout outperforms existing methods to detect out-of-KB mentions for medical ontologies UMLS and SNOMED CT.
Language Model Analysis for Ontology Subsumption Inference
Feb 14, 2023



Pre-trained language models (LMs) have made significant advances in various Natural Language Processing (NLP) domains, but it is unclear to what extent they can infer formal semantics in ontologies, which are often used to represent conceptual knowledge and serve as the schema of data graphs. To investigate an LM's knowledge of ontologies, we propose OntoLAMA, a set of inference-based probing tasks and datasets from ontology subsumption axioms involving both atomic and complex concepts. We conduct extensive experiments on ontologies of different domains and scales, and our results demonstrate that LMs encode relatively less background knowledge of Subsumption Inference (SI) than traditional Natural Language Inference (NLI) but can improve on SI significantly when a small number of samples are given. We will open-source our code and datasets.
Box$^2$EL: Concept and Role Box Embeddings for the Description Logic EL++
Feb 02, 2023



Representation learning in the form of semantic embeddings has been successfully applied to a variety of tasks in natural language processing and knowledge graphs. Recently, there has been growing interest in developing similar methods for learning embeddings of entire ontologies. We propose Box$^2$EL, a novel method for representation learning of ontologies in the Description Logic EL++, which represents both concepts and roles as boxes (i.e. axis-aligned hyperrectangles), such that the logical structure of the ontology is preserved. We theoretically prove the soundness of our model and conduct an extensive empirical evaluation, in which we achieve state-of-the-art results in subsumption prediction, link prediction, and deductive reasoning. As part of our evaluation, we introduce a novel benchmark for evaluating EL++ embedding models on predicting subsumptions involving both atomic and complex concepts.
Minimal Explanations for Neural Network Predictions
May 19, 2022

Explaining neural network predictions is known to be a challenging problem. In this paper, we propose a novel approach which can be effectively exploited, either in isolation or in combination with other methods, to enhance the interpretability of neural model predictions. For a given input to a trained neural model, our aim is to compute a smallest set of input features so that the model prediction changes when these features are disregarded by setting them to an uninformative baseline value. While computing such minimal explanations is computationally intractable in general for fully-connected neural networks, we show that the problem becomes solvable in polynomial time by a greedy algorithm under mild assumptions on the network's activation functions. We then show that our tractability result extends seamlessly to more advanced neural architectures such as convolutional and graph neural networks. We conduct experiments to showcase the capability of our method for identifying the input features that are essential to the model's prediction.
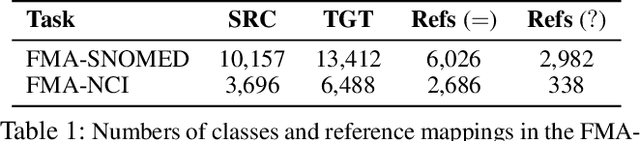
Machine Learning-Friendly Biomedical Datasets for Equivalence and Subsumption Ontology Matching
May 06, 2022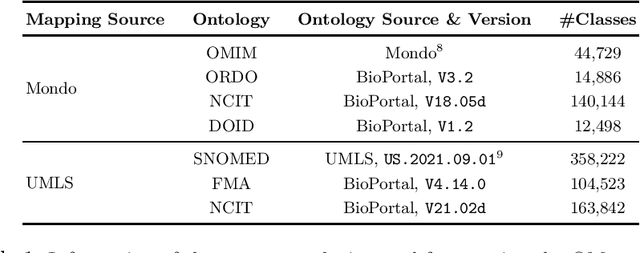
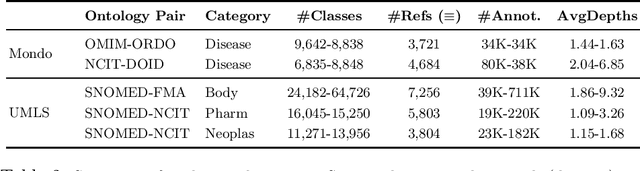
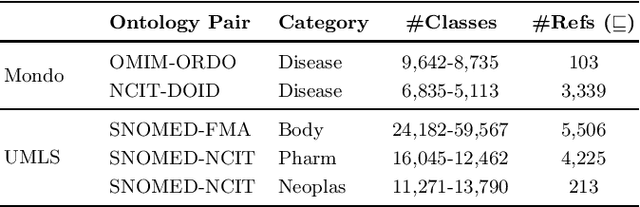
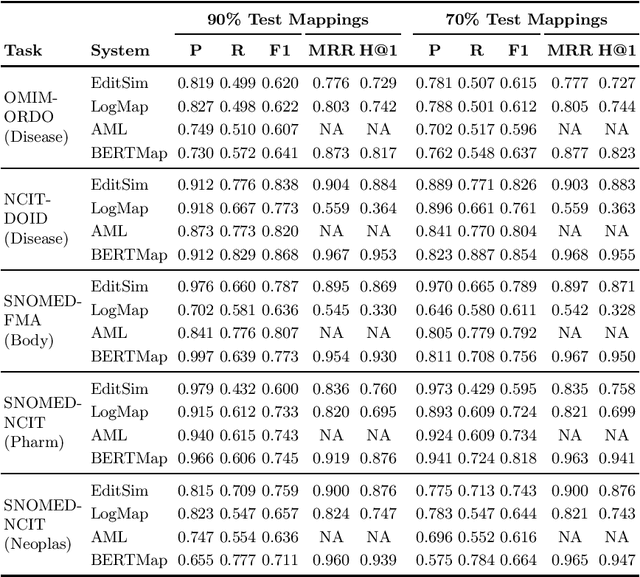
Ontology Matching (OM) plays an important role in many domains such as bioinformatics and the Semantic Web, and its research is becoming increasingly popular, especially with the application of machine learning (ML) techniques. Although the Ontology Alignment Evaluation Initiative (OAEI) represents an impressive effort for the systematic evaluation of OM systems, it still suffers from several limitations including limited evaluation of subsumption mappings, suboptimal reference mappings, and limited support for the evaluation of ML-based systems. To tackle these limitations, we introduce five new biomedical OM tasks involving ontologies extracted from Mondo and UMLS. Each task includes both equivalence and subsumption matching; the quality of reference mappings is ensured by human curation, ontology pruning, etc.; and a comprehensive evaluation framework is proposed to measure OM performance from various perspectives for both ML-based and non-ML-based OM systems. We report evaluation results for OM systems of different types to demonstrate the usage of these resources, all of which are publicly available
Contextual Semantic Embeddings for Ontology Subsumption Prediction
Feb 20, 2022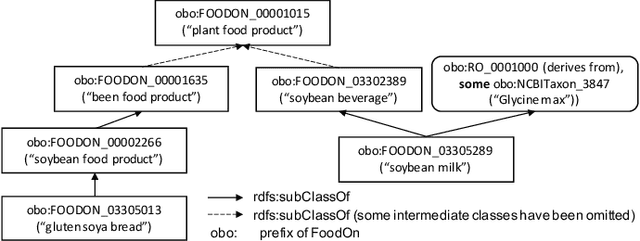
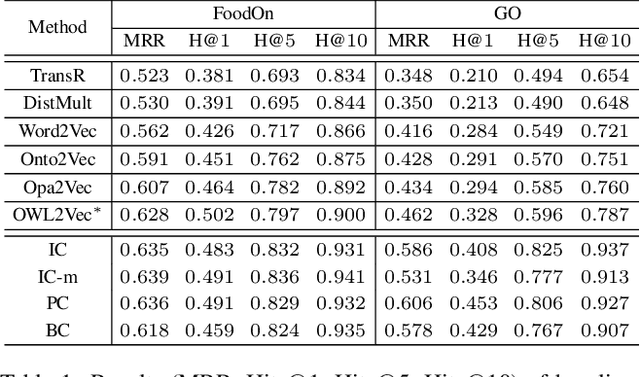
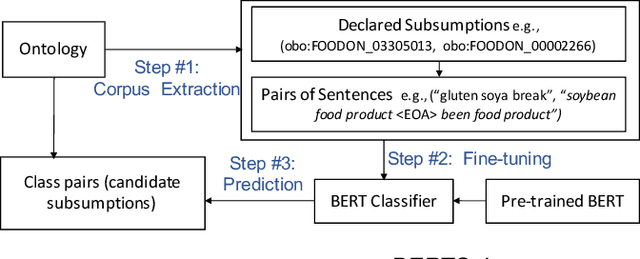
Automating ontology curation is a crucial task in knowledge engineering. Prediction by machine learning techniques such as semantic embedding is a promising direction, but the relevant research is still preliminary. In this paper, we present a class subsumption prediction method named BERTSubs, which uses the pre-trained language model BERT to compute contextual embeddings of the class labels and customized input templates to incorporate contexts of surrounding classes. The evaluation on two large-scale real-world ontologies has shown its better performance than the state-of-the-art.
Low-resource Learning with Knowledge Graphs: A Comprehensive Survey
Dec 28, 2021
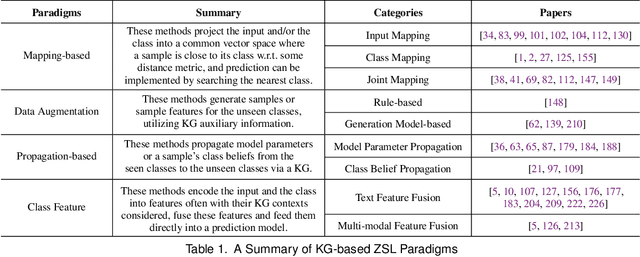
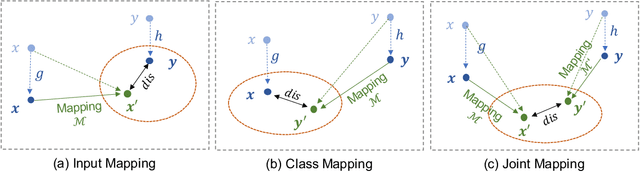
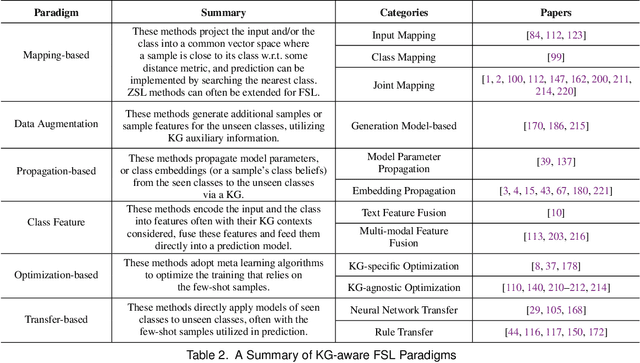
Machine learning methods especially deep neural networks have achieved great success but many of them often rely on a number of labeled samples for training. In real-world applications, we often need to address sample shortage due to e.g., dynamic contexts with emerging prediction targets and costly sample annotation. Therefore, low-resource learning, which aims to learn robust prediction models with no enough resources (especially training samples), is now being widely investigated. Among all the low-resource learning studies, many prefer to utilize some auxiliary information in the form of Knowledge Graph (KG), which is becoming more and more popular for knowledge representation, to reduce the reliance on labeled samples. In this survey, we very comprehensively reviewed over $90$ papers about KG-aware research for two major low-resource learning settings -- zero-shot learning (ZSL) where new classes for prediction have never appeared in training, and few-shot learning (FSL) where new classes for prediction have only a small number of labeled samples that are available. We first introduced the KGs used in ZSL and FSL studies as well as the existing and potential KG construction solutions, and then systematically categorized and summarized KG-aware ZSL and FSL methods, dividing them into different paradigms such as the mapping-based, the data augmentation, the propagation-based and the optimization-based. We next presented different applications, including not only KG augmented tasks in Computer Vision and Natural Language Processing (e.g., image classification, text classification and knowledge extraction), but also tasks for KG curation (e.g., inductive KG completion), and some typical evaluation resources for each task. We eventually discussed some challenges and future directions on aspects such as new learning and reasoning paradigms, and the construction of high quality KGs.
BERTMap: A BERT-based Ontology Alignment System
Dec 23, 2021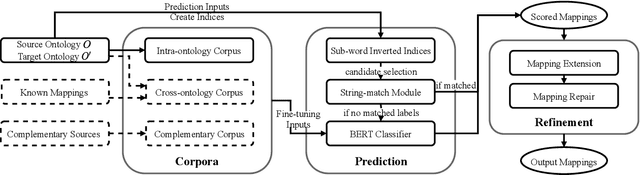
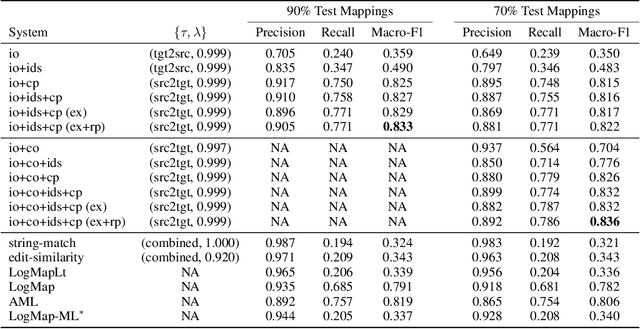
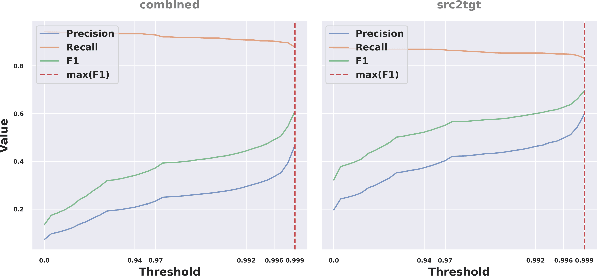
Ontology alignment (a.k.a ontology matching (OM)) plays a critical role in knowledge integration. Owing to the success of machine learning in many domains, it has been applied in OM. However, the existing methods, which often adopt ad-hoc feature engineering or non-contextual word embeddings, have not yet outperformed rule-based systems especially in an unsupervised setting. In this paper, we propose a novel OM system named BERTMap which can support both unsupervised and semi-supervised settings. It first predicts mappings using a classifier based on fine-tuning the contextual embedding model BERT on text semantics corpora extracted from ontologies, and then refines the mappings through extension and repair by utilizing the ontology structure and logic. Our evaluation with three alignment tasks on biomedical ontologies demonstrates that BERTMap can often perform better than the leading OM systems LogMap and AML.
On Event-Driven Knowledge Graph Completion in Digital Factories
Sep 08, 2021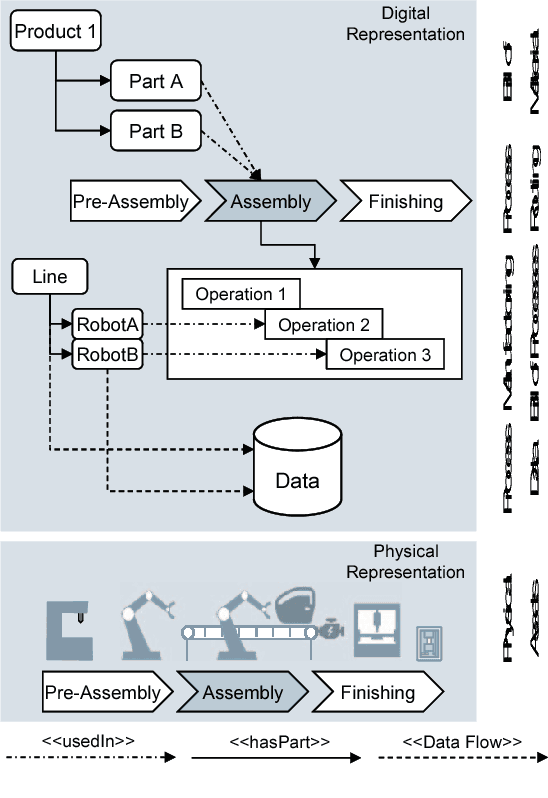
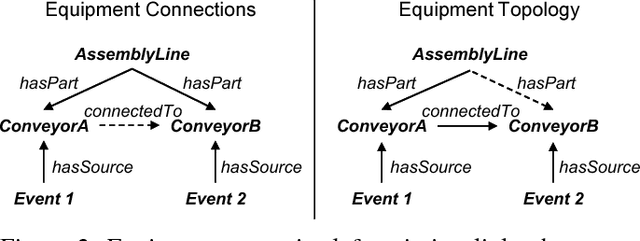
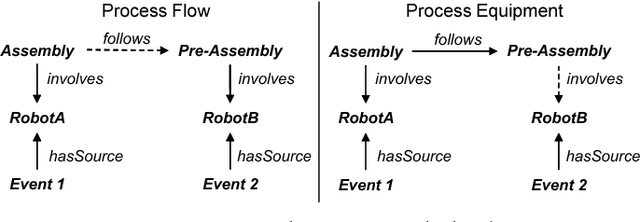
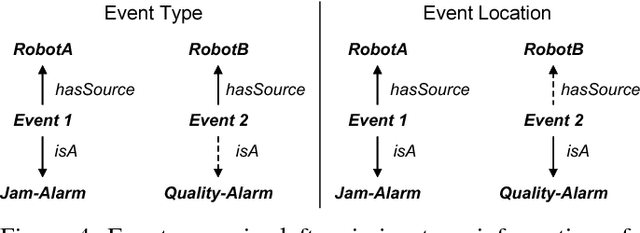
Smart factories are equipped with machines that can sense their manufacturing environments, interact with each other, and control production processes. Smooth operation of such factories requires that the machines and engineering personnel that conduct their monitoring and diagnostics share a detailed common industrial knowledge about the factory, e.g., in the form of knowledge graphs. Creation and maintenance of such knowledge is expensive and requires automation. In this work we show how machine learning that is specifically tailored towards industrial applications can help in knowledge graph completion. In particular, we show how knowledge completion can benefit from event logs that are common in smart factories. We evaluate this on the knowledge graph from a real world-inspired smart factory with encouraging results.