 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Training Methods for Semi-Supervised Text Classification
May 06, 2017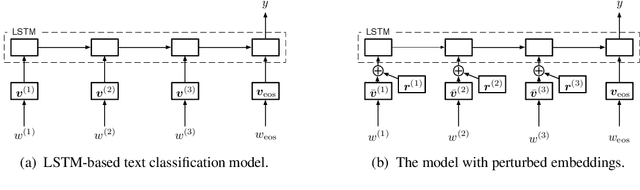
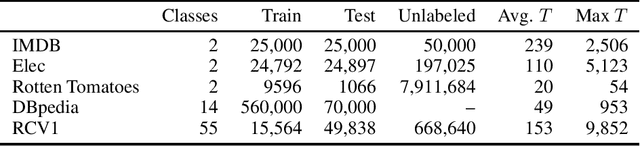
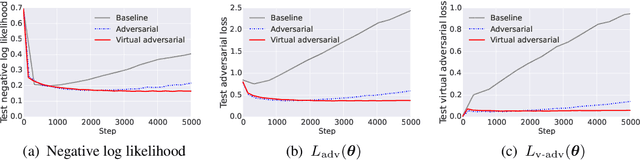

Adversarial training provides a means of regularizing supervised learning algorithms while virtual adversarial training is able to extend supervised learning algorithms to the semi-supervised setting. However, both methods require making small perturbations to numerous entries of the input vector, which is inappropriate for sparse high-dimensional inputs such as one-hot word representations. We extend adversarial and virtual adversarial training to the text domain by applying perturbations to the word embeddings in a recurrent neural network rather than to the original input itself. The proposed method achieves state of the art results on multiple benchmark semi-supervised and purely supervised tasks. We provide visualizations and analysis showing that the learned word embeddings have improved in quality and that while training, the model is less prone to overfitting.
NIPS 2016 Tutorial: Generative Adversarial Networks
Apr 03, 2017
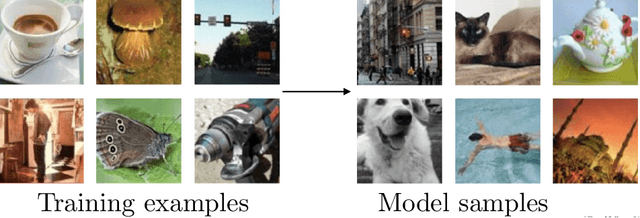
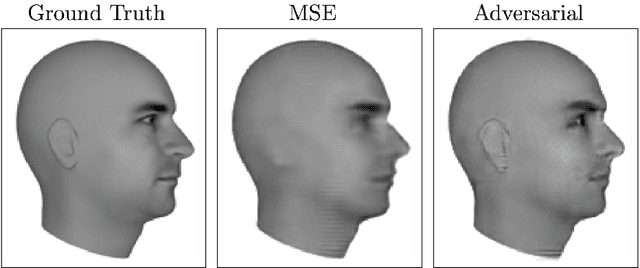
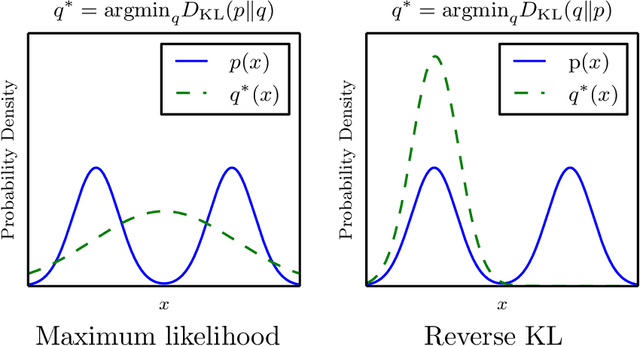
This report summarizes the tutorial presented by the author at NIPS 2016 on generative adversarial networks (GANs). The tutorial describes: (1) Why generative modeling is a topic worth studying, (2) how generative models work, and how GANs compare to other generative models, (3) the details of how GANs work, (4) research frontiers in GANs, and (5) state-of-the-art image models that combine GANs with other methods. Finally, the tutorial contains three exercises for readers to complete, and the solutions to these exercises.
Practical Black-Box Attacks against Machine Learning
Mar 19, 2017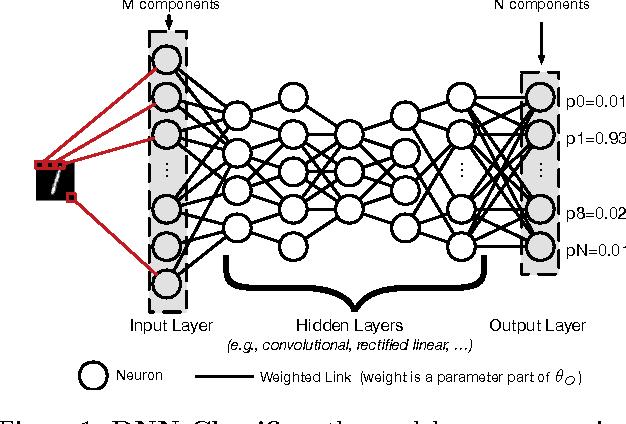
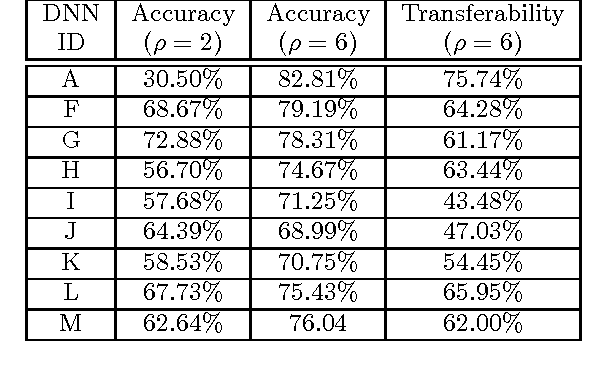

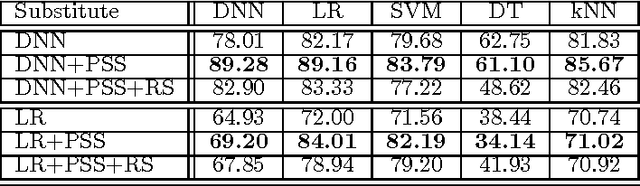
Machine learning (ML) models, e.g., deep neural networks (DNNs), are vulnerable to adversarial examples: malicious inputs modified to yield erroneous model outputs, while appearing unmodified to human observers. Potential attacks include having malicious content like malware identified as legitimate or controlling vehicle behavior. Yet, all existing adversarial example attacks require knowledge of either the model internals or its training data. We introduce the first practical demonstration of an attacker controlling a remotely hosted DNN with no such knowledge. Indeed, the only capability of our black-box adversary is to observe labels given by the DNN to chosen inputs. Our attack strategy consists in training a local model to substitute for the target DNN, using inputs synthetically generated by an adversary and labeled by the target DNN. We use the local substitute to craft adversarial examples, and find that they are misclassified by the targeted DNN. To perform a real-world and properly-blinded evaluation, we attack a DNN hosted by MetaMind, an online deep learning API. We find that their DNN misclassifies 84.24% of the adversarial examples crafted with our substitute. We demonstrate the general applicability of our strategy to many ML techniques by conducting the same attack against models hosted by Amazon and Google, using logistic regression substitutes. They yield adversarial examples misclassified by Amazon and Google at rates of 96.19% and 88.94%. We also find that this black-box attack strategy is capable of evading defense strategies previously found to make adversarial example crafting harder.
Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data
Mar 03, 2017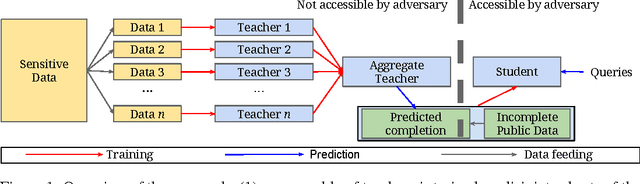
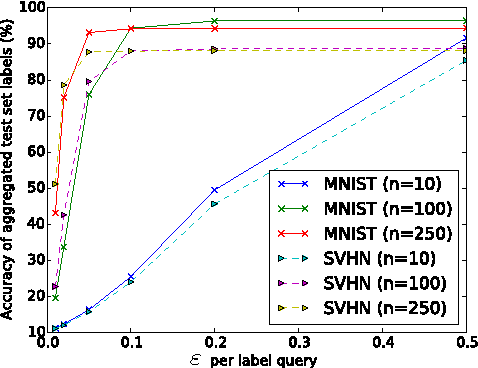
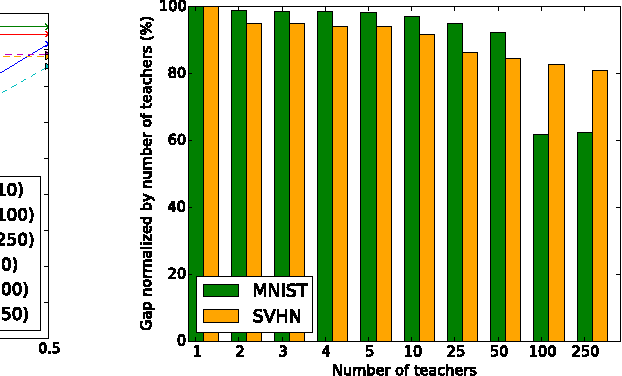

Some machine learning applications involve training data that is sensitive, such as the medical histories of patients in a clinical trial. A model may inadvertently and implicitly store some of its training data; careful analysis of the model may therefore reveal sensitive information. To address this problem, we demonstrate a generally applicable approach to providing strong privacy guarantees for training data: Private Aggregation of Teacher Ensembles (PATE). The approach combines, in a black-box fashion, multiple models trained with disjoint datasets, such as records from different subsets of users. Because they rely directly on sensitive data, these models are not published, but instead used as "teachers" for a "student" model. The student learns to predict an output chosen by noisy voting among all of the teachers, and cannot directly access an individual teacher or the underlying data or parameters. The student's privacy properties can be understood both intuitively (since no single teacher and thus no single dataset dictates the student's training) and formally, in terms of differential privacy. These properties hold even if an adversary can not only query the student but also inspect its internal workings. Compared with previous work, the approach imposes only weak assumptions on how teachers are trained: it applies to any model, including non-convex models like DNNs. We achieve state-of-the-art privacy/utility trade-offs on MNIST and SVHN thanks to an improved privacy analysis and semi-supervised learning.
Adversarial examples in the physical world
Feb 11, 2017
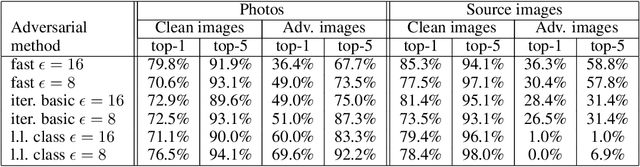

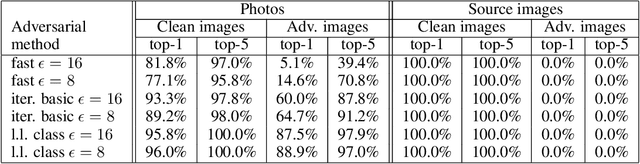
Most existing machine learning classifiers are highly vulnerable to adversarial examples. An adversarial example is a sample of input data which has been modified very slightly in a way that is intended to cause a machine learning classifier to misclassify it. In many cases, these modifications can be so subtle that a human observer does not even notice the modification at all, yet the classifier still makes a mistake. Adversarial examples pose security concerns because they could be used to perform an attack on machine learning systems, even if the adversary has no access to the underlying model. Up to now, all previous work have assumed a threat model in which the adversary can feed data directly into the machine learning classifier. This is not always the case for systems operating in the physical world, for example those which are using signals from cameras and other sensors as an input. This paper shows that even in such physical world scenarios, machine learning systems are vulnerable to adversarial examples. We demonstrate this by feeding adversarial images obtained from cell-phone camera to an ImageNet Inception classifier and measuring the classification accuracy of the system. We find that a large fraction of adversarial examples are classified incorrectly even when perceived through the camera.
Adversarial Machine Learning at Scale
Feb 11, 2017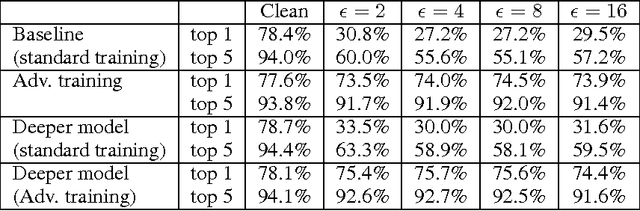
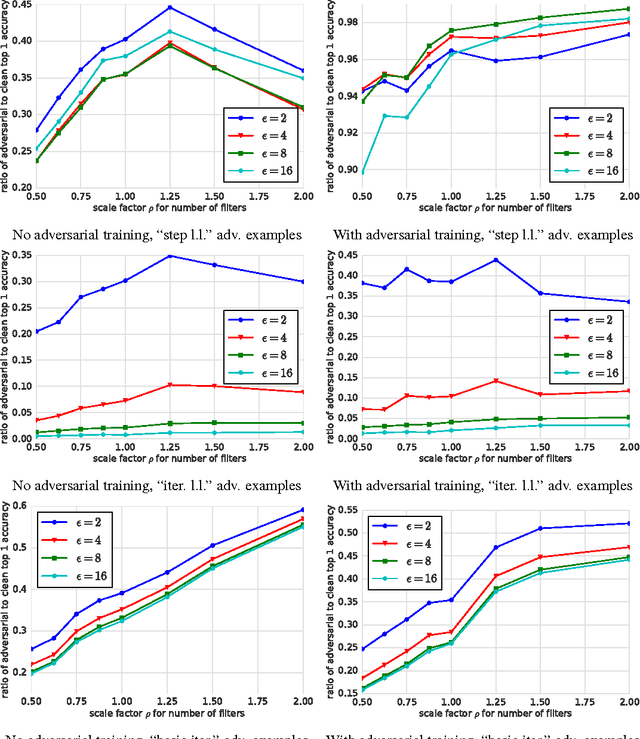
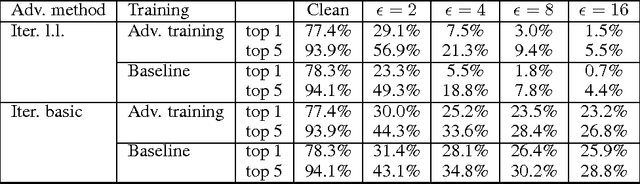
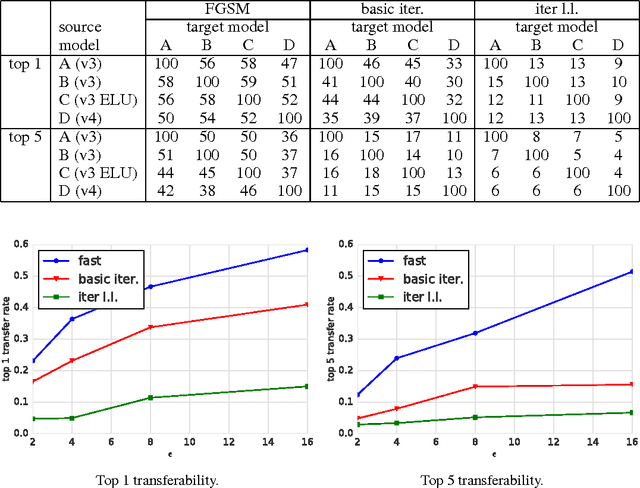
Adversarial examples are malicious inputs designed to fool machine learning models. They often transfer from one model to another, allowing attackers to mount black box attacks without knowledge of the target model's parameters. Adversarial training is the process of explicitly training a model on adversarial examples, in order to make it more robust to attack or to reduce its test error on clean inputs. So far, adversarial training has primarily been applied to small problems. In this research, we apply adversarial training to ImageNet. Our contributions include: (1) recommendations for how to succesfully scale adversarial training to large models and datasets, (2) the observation that adversarial training confers robustness to single-step attack methods, (3) the finding that multi-step attack methods are somewhat less transferable than single-step attack methods, so single-step attacks are the best for mounting black-box attacks, and (4) resolution of a "label leaking" effect that causes adversarially trained models to perform better on adversarial examples than on clean examples, because the adversarial example construction process uses the true label and the model can learn to exploit regularities in the construction process.
Adversarial Attacks on Neural Network Policies
Feb 08, 2017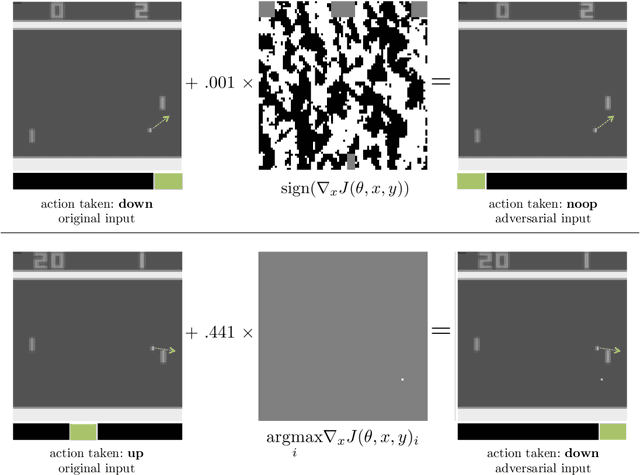
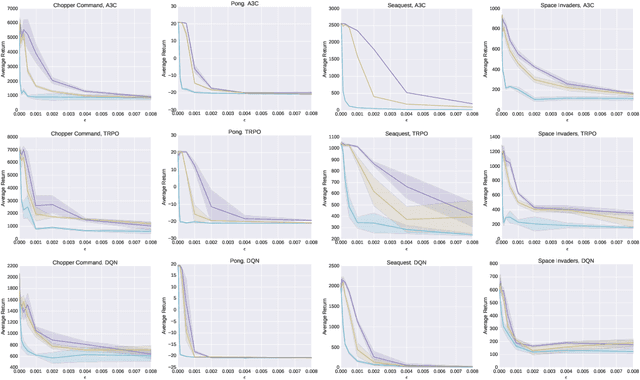
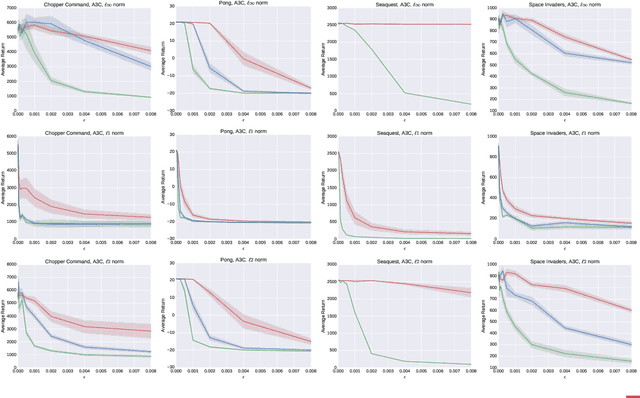
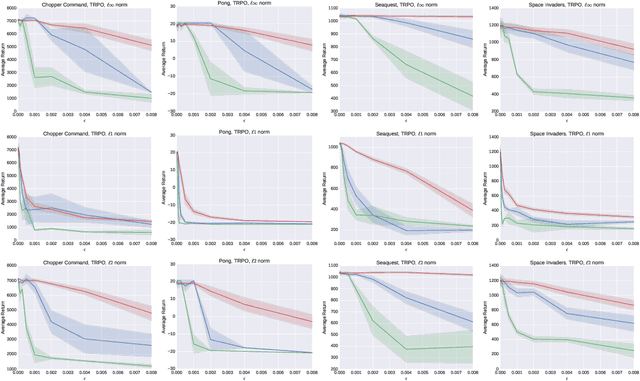
Machine learning classifiers are known to be vulnerable to inputs maliciously constructed by adversaries to force misclassification. Such adversarial examples have been extensively studied in the context of computer vision applications. In this work, we show adversarial attacks are also effective when targeting neural network policies in reinforcement learning. Specifically, we show existing adversarial example crafting techniques can be used to significantly degrade test-time performance of trained policies. Our threat model considers adversaries capable of introducing small perturbations to the raw input of the policy. We characterize the degree of vulnerability across tasks and training algorithms, for a subclass of adversarial-example attacks in white-box and black-box settings. Regardless of the learned task or training algorithm, we observe a significant drop in performance, even with small adversarial perturbations that do not interfere with human perception. Videos are available at http://rll.berkeley.edu/adversarial.
Deep Learning with Differential Privacy
Oct 24, 2016
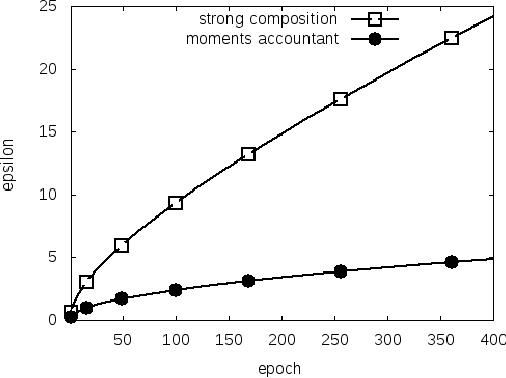
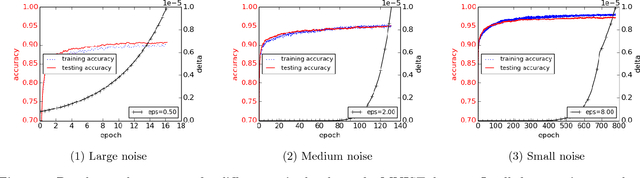
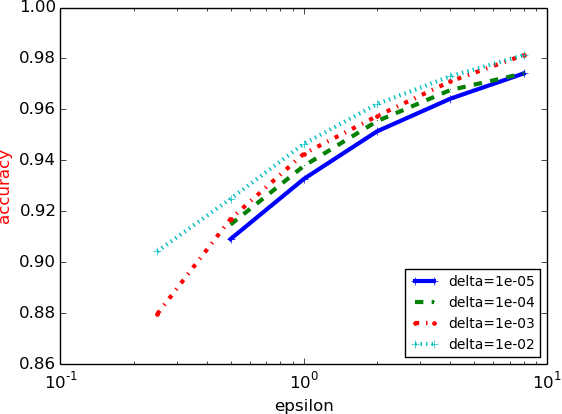
Machine learning techniques based on neural networks are achieving remarkable results in a wide variety of domains. Often, the training of models requires large, representative datasets, which may be crowdsourced and contain sensitive information. The models should not expose private information in these datasets. Addressing this goal, we develop new algorithmic techniques for learning and a refined analysis of privacy costs within the framework of differential privacy. Our implementation and experiments demonstrate that we can train deep neural networks with non-convex objectives, under a modest privacy budget, and at a manageable cost in software complexity, training efficiency, and model quality.
Unsupervised Learning for Physical Interaction through Video Prediction
Oct 17, 2016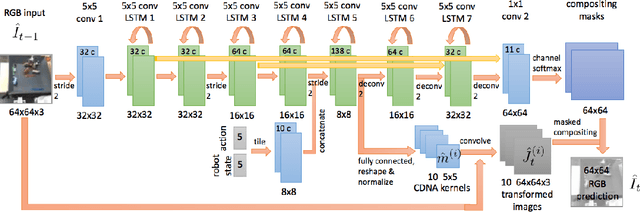

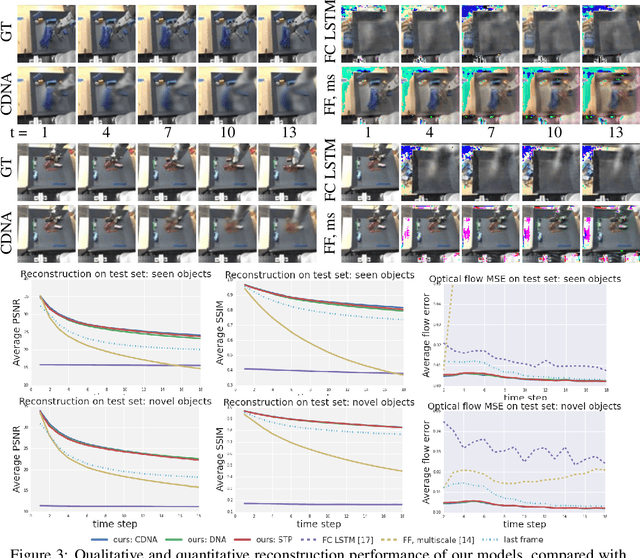
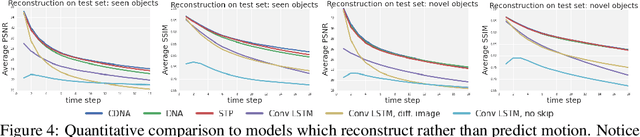
A core challenge for an agent learning to interact with the world is to predict how its actions affect objects in its environment. Many existing methods for learning the dynamics of physical interactions require labeled object information. However, to scale real-world interaction learning to a variety of scenes and objects, acquiring labeled data becomes increasingly impractical. To learn about physical object motion without labels, we develop an action-conditioned video prediction model that explicitly models pixel motion, by predicting a distribution over pixel motion from previous frames. Because our model explicitly predicts motion, it is partially invariant to object appearance, enabling it to generalize to previously unseen objects. To explore video prediction for real-world interactive agents, we also introduce a dataset of 59,000 robot interactions involving pushing motions, including a test set with novel objects. In this dataset, accurate prediction of videos conditioned on the robot's future actions amounts to learning a "visual imagination" of different futures based on different courses of action. Our experiments show that our proposed method produces more accurate video predictions both quantitatively and qualitatively, when compared to prior methods.
Improved Techniques for Training GANs
Jun 10, 2016



We present a variety of new architectural features and training procedures that we apply to the generative adversarial networks (GANs) framework. We focus on two applications of GANs: semi-supervised learning, and the generation of images that humans find visually realistic. Unlike most work on generative models, our primary goal is not to train a model that assigns high likelihood to test data, nor do we require the model to be able to learn well without using any labels. Using our new techniques, we achieve state-of-the-art results in semi-supervised classification on MNIST, CIFAR-10 and SVHN. The generated images are of high quality as confirmed by a visual Turing test: our model generates MNIST samples that humans cannot distinguish from real data, and CIFAR-10 samples that yield a human error rate of 21.3%. We also present ImageNet samples with unprecedented resolution and show that our methods enable the model to learn recognizable features of ImageNet classes.