 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Experts with Intermediate CTC Supervision for Accented Speech Recognition
Feb 02, 2026Accented speech remains a persistent challenge for automatic speech recognition (ASR), as most models are trained on data dominated by a few high-resource English varieties, leading to substantial performance degradation for other accents. Accent-agnostic approaches improve robustness yet struggle with heavily accented or unseen varieties, while accent-specific methods rely on limited and often noisy labels. We introduce Moe-Ctc, a Mixture-of-Experts architecture with intermediate CTC supervision that jointly promotes expert specialization and generalization. During training, accent-aware routing encourages experts to capture accent-specific patterns, which gradually transitions to label-free routing for inference. Each expert is equipped with its own CTC head to align routing with transcription quality, and a routing-augmented loss further stabilizes optimization. Experiments on the Mcv-Accent benchmark demonstrate consistent gains across both seen and unseen accents in low- and high-resource conditions, achieving up to 29.3% relative WER reduction over strong FastConformer baselines.
Why Do Multilingual Reasoning Gaps Emerge in Reasoning Language Models?
Oct 31, 2025Reasoning language models (RLMs) achieve strong performance on complex reasoning tasks, yet they still suffer from a multilingual reasoning gap, performing better in high-resource languages than in low-resource ones. While recent efforts have reduced this gap, its underlying causes remain largely unexplored. In this paper, we address this by showing that the multilingual reasoning gap largely stems from failures in language understanding-the model's inability to represent the multilingual input meaning into the dominant language (i.e., English) within its reasoning trace. This motivates us to examine whether understanding failures can be detected, as this ability could help mitigate the multilingual reasoning gap. To this end, we evaluate a range of detection methods and find that understanding failures can indeed be identified, with supervised approaches performing best. Building on this, we propose Selective Translation, a simple yet effective strategy that translates the multilingual input into English only when an understanding failure is detected. Experimental results show that Selective Translation bridges the multilingual reasoning gap, achieving near full-translation performance while using translation for only about 20% of inputs. Together, our work demonstrates that understanding failures are the primary cause of the multilingual reasoning gap and can be detected and selectively mitigated, providing key insight into its origin and a promising path toward more equitable multilingual reasoning. Our code and data are publicly available at https://github.com/deokhk/RLM_analysis.
Self-Correcting Code Generation Using Small Language Models
May 29, 2025Self-correction has demonstrated potential in code generation by allowing language models to revise and improve their outputs through successive refinement. Recent studies have explored prompting-based strategies that incorporate verification or feedback loops using proprietary models, as well as training-based methods that leverage their strong reasoning capabilities. However, whether smaller models possess the capacity to effectively guide their outputs through self-reflection remains unexplored. Our findings reveal that smaller models struggle to exhibit reflective revision behavior across both self-correction paradigms. In response, we introduce CoCoS, an approach designed to enhance the ability of small language models for multi-turn code correction. Specifically, we propose an online reinforcement learning objective that trains the model to confidently maintain correct outputs while progressively correcting incorrect outputs as turns proceed. Our approach features an accumulated reward function that aggregates rewards across the entire trajectory and a fine-grained reward better suited to multi-turn correction scenarios. This facilitates the model in enhancing initial response quality while achieving substantial improvements through self-correction. With 1B-scale models, CoCoS achieves improvements of 35.8% on the MBPP and 27.7% on HumanEval compared to the baselines.
Collective Critics for Creative Story Generation
Oct 03, 2024



Generating a long story of several thousand words with narrative coherence using Large Language Models (LLMs) has been a challenging task. Previous research has addressed this challenge by proposing different frameworks that create a story plan and generate a long story based on that plan. However, these frameworks have been mainly focusing on maintaining narrative coherence in stories, often overlooking creativity in story planning and the expressiveness of the stories generated from those plans, which are desirable properties to captivate readers' interest. In this paper, we propose Collective Critics for Creative Story Generation framework (CritiCS), which is composed of plan refining stage (CrPlan) and story generation stage (CrText), to integrate a collective revision mechanism that promotes those properties into long-form story generation process. Specifically, in each stage, a group of LLM critics and one leader collaborate to incrementally refine drafts of plan and story throughout multiple rounds. Extensive human evaluation shows that the CritiCS can significantly enhance story creativity and reader engagement, while also maintaining narrative coherence. Furthermore, the design of the framework allows active participation from human writers in any role within the critique process, enabling interactive human-machine collaboration in story writing.
Response Tuning: Aligning Large Language Models without Instruction
Oct 03, 2024Instruction tuning-supervised fine-tuning using instruction-response pairs-is a foundational step in transitioning pre-trained Large Language Models (LLMs) into helpful and safe chat assistants. Our hypothesis is that establishing an adequate output space can enable such a transition given the capabilities inherent in pre-trained LLMs. To verify this, we propose Response Tuning (RT), which eliminates the instruction-conditioning step in instruction tuning and solely focuses on response space supervision. Our experiments demonstrate that RT models, trained only using responses, can effectively respond to a wide range of instructions and exhibit helpfulness comparable to that of their instruction-tuned counterparts. Furthermore, we observe that controlling the training response distribution can significantly improve their user preference or elicit target behaviors such as refusing assistance for unsafe queries. Our findings illuminate the role of establishing an adequate output space in alignment, highlighting the potential of the extensive inherent capabilities of pre-trained LLMs.
Mixed-Session Conversation with Egocentric Memory
Oct 03, 2024



Recently introduced dialogue systems have demonstrated high usability. However, they still fall short of reflecting real-world conversation scenarios. Current dialogue systems exhibit an inability to replicate the dynamic, continuous, long-term interactions involving multiple partners. This shortfall arises because there have been limited efforts to account for both aspects of real-world dialogues: deeply layered interactions over the long-term dialogue and widely expanded conversation networks involving multiple participants. As the effort to incorporate these aspects combined, we introduce Mixed-Session Conversation, a dialogue system designed to construct conversations with various partners in a multi-session dialogue setup. We propose a new dataset called MiSC to implement this system. The dialogue episodes of MiSC consist of 6 consecutive sessions, with four speakers (one main speaker and three partners) appearing in each episode. Also, we propose a new dialogue model with a novel memory management mechanism, called Egocentric Memory Enhanced Mixed-Session Conversation Agent (EMMA). EMMA collects and retains memories from the main speaker's perspective during conversations with partners, enabling seamless continuity in subsequent interactions. Extensive human evaluations validate that the dialogues in MiSC demonstrate a seamless conversational flow, even when conversation partners change in each session. EMMA trained with MiSC is also evaluated to maintain high memorability without contradiction throughout the entire conversation.
Sound of Story: Multi-modal Storytelling with Audio
Oct 30, 2023



Storytelling is multi-modal in the real world. When one tells a story, one may use all of the visualizations and sounds along with the story itself. However, prior studies on storytelling datasets and tasks have paid little attention to sound even though sound also conveys meaningful semantics of the story. Therefore, we propose to extend story understanding and telling areas by establishing a new component called "background sound" which is story context-based audio without any linguistic information. For this purpose, we introduce a new dataset, called "Sound of Story (SoS)", which has paired image and text sequences with corresponding sound or background music for a story. To the best of our knowledge, this is the largest well-curated dataset for storytelling with sound. Our SoS dataset consists of 27,354 stories with 19.6 images per story and 984 hours of speech-decoupled audio such as background music and other sounds. As benchmark tasks for storytelling with sound and the dataset, we propose retrieval tasks between modalities, and audio generation tasks from image-text sequences, introducing strong baselines for them. We believe the proposed dataset and tasks may shed light on the multi-modal understanding of storytelling in terms of sound. Downloading the dataset and baseline codes for each task will be released in the link: https://github.com/Sosdatasets/SoS_Dataset.
Conversation Chronicles: Towards Diverse Temporal and Relational Dynamics in Multi-Session Conversations
Oct 20, 2023In the field of natural language processing, open-domain chatbots have emerged as an important research topic. However, a major limitation of existing open-domain chatbot research is its singular focus on short single-session dialogue, neglecting the potential need for understanding contextual information in multiple consecutive sessions that precede an ongoing dialogue. Among the elements that compose the context in multi-session conversation settings, the time intervals between sessions and the relationships between speakers would be particularly important. Despite their importance, current research efforts have not sufficiently addressed these dialogical components. In this paper, we introduce a new 1M multi-session dialogue dataset, called Conversation Chronicles, for implementing a long-term conversation setup in which time intervals and fine-grained speaker relationships are incorporated. Following recent works, we exploit a large language model to produce the data. The extensive human evaluation shows that dialogue episodes in Conversation Chronicles reflect those properties while maintaining coherent and consistent interactions across all the sessions. We also propose a dialogue model, called ReBot, which consists of chronological summarization and dialogue generation modules using only around 630M parameters. When trained on Conversation Chronicles, ReBot demonstrates long-term context understanding with a high human engagement score.
CoSIm: Commonsense Reasoning for Counterfactual Scene Imagination
Jul 08, 2022
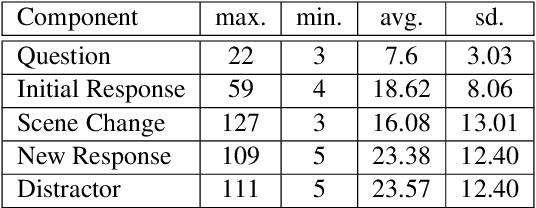
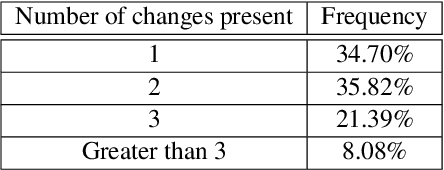
As humans, we can modify our assumptions about a scene by imagining alternative objects or concepts in our minds. For example, we can easily anticipate the implications of the sun being overcast by rain clouds (e.g., the street will get wet) and accordingly prepare for that. In this paper, we introduce a new task/dataset called Commonsense Reasoning for Counterfactual Scene Imagination (CoSIm) which is designed to evaluate the ability of AI systems to reason about scene change imagination. In this task/dataset, models are given an image and an initial question-response pair about the image. Next, a counterfactual imagined scene change (in textual form) is applied, and the model has to predict the new response to the initial question based on this scene change. We collect 3.5K high-quality and challenging data instances, with each instance consisting of an image, a commonsense question with a response, a description of a counterfactual change, a new response to the question, and three distractor responses. Our dataset contains various complex scene change types (such as object addition/removal/state change, event description, environment change, etc.) that require models to imagine many different scenarios and reason about the changed scenes. We present a baseline model based on a vision-language Transformer (i.e., LXMERT) and ablation studies. Through human evaluation, we demonstrate a large human-model performance gap, suggesting room for promising future work on this challenging counterfactual, scene imagination task. Our code and dataset are publicly available at: https://github.com/hyounghk/CoSIm
On the Limits of Evaluating Embodied Agent Model Generalization Using Validation Sets
May 18, 2022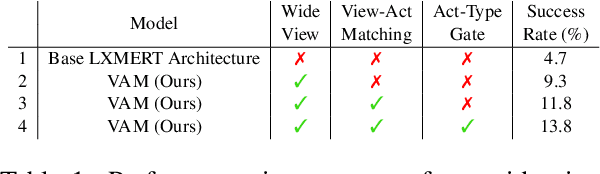
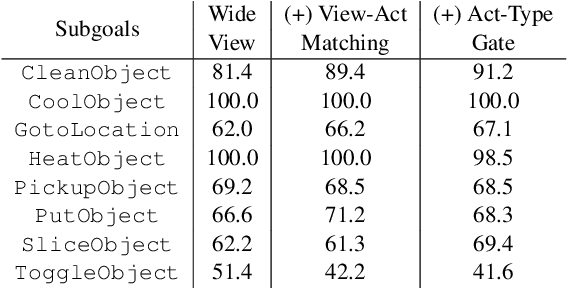
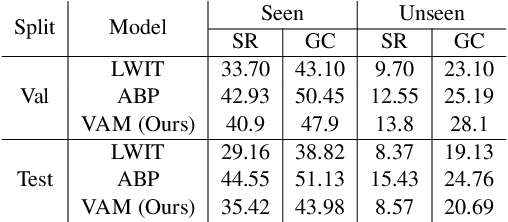
Natural language guided embodied task completion is a challenging problem since it requires understanding natural language instructions, aligning them with egocentric visual observations, and choosing appropriate actions to execute in the environment to produce desired changes. We experiment with augmenting a transformer model for this task with modules that effectively utilize a wider field of view and learn to choose whether the next step requires a navigation or manipulation action. We observed that the proposed modules resulted in improved, and in fact state-of-the-art performance on an unseen validation set of a popular benchmark dataset, ALFRED. However, our best model selected using the unseen validation set underperforms on the unseen test split of ALFRED, indicating that performance on the unseen validation set may not in itself be a sufficient indicator of whether model improvements generalize to unseen test sets. We highlight this result as we believe it may be a wider phenomenon in machine learning tasks but primarily noticeable only in benchmarks that limit evaluations on test splits, and highlights the need to modify benchmark design to better account for variance in model performance.