 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Inception-Residual-Based Architecture with Multi-Objective Loss for Detecting Respiratory Anomalies
Mar 07, 2023This paper presents a deep learning system applied for detecting anomalies from respiratory sound recordings. Initially, our system begins with audio feature extraction using Gammatone and Continuous Wavelet transformation. This step aims to transform the respiratory sound input into a two-dimensional spectrogram where both spectral and temporal features are presented. Then, our proposed system integrates Inception-residual-based backbone models combined with multi-head attention and multi-objective loss to classify respiratory anomalies. In this work, we conducted experiments over the benchmark dataset of SPRSound (The Open-Source SJTU Paediatric Respiratory Sound) proposed by the IEEE BioCAS 2022 challenge. As regards the Score computed by an average between the average score and harmonic score, our proposed system gained significant improvements of 9.7%, 15.8%, 17.0%, and 9.4% in Task 1-1, Task 1-2, Task 2-1, and Task 2-2 compared to the challenge baseline system. Notably, we achieved the Top-1 performance in Task 2-1 with the highest Score of 73.7%.
cross-modal fusion techniques for utterance-level emotion recognition from text and speech
Feb 05, 2023



Multimodal emotion recognition (MER) is a fundamental complex research problem due to the uncertainty of human emotional expression and the heterogeneity gap between different modalities. Audio and text modalities are particularly important for a human participant in understanding emotions. Although many successful attempts have been designed multimodal representations for MER, there still exist multiple challenges to be addressed: 1) bridging the heterogeneity gap between multimodal features and model inter- and intra-modal interactions of multiple modalities; 2) effectively and efficiently modelling the contextual dynamics in the conversation sequence. In this paper, we propose Cross-Modal RoBERTa (CM-RoBERTa) model for emotion detection from spoken audio and corresponding transcripts. As the core unit of the CM-RoBERTa, parallel self- and cross- attention is designed to dynamically capture inter- and intra-modal interactions of audio and text. Specially, the mid-level fusion and residual module are employed to model long-term contextual dependencies and learn modality-specific patterns. We evaluate the approach on the MELD dataset and the experimental results show the proposed approach achieves the state-of-art performance on the dataset.
deep learning of segment-level feature representation for speech emotion recognition in conversations
Feb 05, 2023



Accurately detecting emotions in conversation is a necessary yet challenging task due to the complexity of emotions and dynamics in dialogues. The emotional state of a speaker can be influenced by many different factors, such as interlocutor stimulus, dialogue scene, and topic. In this work, we propose a conversational speech emotion recognition method to deal with capturing attentive contextual dependency and speaker-sensitive interactions. First, we use a pretrained VGGish model to extract segment-based audio representation in individual utterances. Second, an attentive bi-directional gated recurrent unit (GRU) models contextual-sensitive information and explores intra- and inter-speaker dependencies jointly in a dynamic manner. The experiments conducted on the standard conversational dataset MELD demonstrate the effectiveness of the proposed method when compared against state-of the-art methods.
L-SeqSleepNet: Whole-cycle Long Sequence Modelling for Automatic Sleep Staging
Jan 25, 2023



Human sleep is cyclical with a period of approximately 90 minutes, implying long temporal dependency in the sleep data. Yet, exploring this long-term dependency when developing sleep staging models has remained untouched. In this work, we show that while encoding the logic of a whole sleep cycle is crucial to improve sleep staging performance, the sequential modelling approach in existing state-of-the-art deep learning models are inefficient for that purpose. We thus introduce a method for efficient long sequence modelling and propose a new deep learning model, L-SeqSleepNet, which takes into account whole-cycle sleep information for sleep staging. Evaluating L-SeqSleepNet on four distinct databases of various sizes, we demonstrate state-of-the-art performance obtained by the model over three different EEG setups, including scalp EEG in conventional Polysomnography (PSG), in-ear EEG, and around-the-ear EEG (cEEGrid), even with a single EEG channel input. Our analyses also show that L-SeqSleepNet is able to alleviate the predominance of N2 sleep (the major class in terms of classification) to bring down errors in other sleep stages. Moreover the network becomes much more robust, meaning that for all subjects where the baseline method had exceptionally poor performance, their performance are improved significantly. Finally, the computation time only grows at a sub-linear rate when the sequence length increases.
Learning from Taxonomy: Multi-label Few-Shot Classification for Everyday Sound Recognition
Dec 17, 2022Everyday sound recognition aims to infer types of sound events in audio streams. While many works succeeded in training models with high performance in a fully-supervised manner, they are still restricted to the demand of large quantities of labelled data and the range of predefined classes. To overcome these drawbacks, this work firstly curates a new database named FSD-FS for multi-label few-shot audio classification. It then explores how to incorporate audio taxonomy in few-shot learning. Specifically, this work proposes label-dependent prototypical networks (LaD-protonet) to exploit parent-children relationships between labels. Plus, it applies taxonomy-aware label smoothing techniques to boost model performance. Experiments demonstrate that LaD-protonet outperforms original prototypical networks as well as other state-of-the-art methods. Moreover, its performance can be further boosted when combined with taxonomy-aware label smoothing.
Improving trajectory localization accuracy via direction-of-arrival derivative estimation
Dec 10, 2022Sound source localization is crucial in acoustic sensing and monitoring-related applications. In this paper, we do a comprehensive analysis of improvement in sound source localization by combining the direction of arrivals (DOAs) with their derivatives which quantify the changes in the positions of sources over time. This study uses the SALSA-Lite feature with a convolutional recurrent neural network (CRNN) model for predicting DOAs and their first-order derivatives. An update rule is introduced to combine the predicted DOAs with the estimated derivatives to obtain the final DOAs. The experimental validation is done using TAU-NIGENS Spatial Sound Events (TNSSE) 2021 dataset. We compare the performance of the networks predicting DOAs with derivative vs. the one predicting only the DOAs at low SNR levels. The results show that combining the derivatives with the DOAs improves the localization accuracy of moving sources.
CSTAR: Towards Compact and STructured Deep Neural Networks with Adversarial Robustness
Dec 04, 2022



Model compression and model defense for deep neural networks (DNNs) have been extensively and individually studied. Considering the co-importance of model compactness and robustness in practical applications, several prior works have explored to improve the adversarial robustness of the sparse neural networks. However, the structured sparse models obtained by the exiting works suffer severe performance degradation for both benign and robust accuracy, thereby causing a challenging dilemma between robustness and structuredness of the compact DNNs. To address this problem, in this paper, we propose CSTAR, an efficient solution that can simultaneously impose the low-rankness-based Compactness, high STructuredness and high Adversarial Robustness on the target DNN models. By formulating the low-rankness and robustness requirement within the same framework and globally determining the ranks, the compressed DNNs can simultaneously achieve high compression performance and strong adversarial robustness. Evaluations for various DNN models on different datasets demonstrate the effectiveness of CSTAR. Compared with the state-of-the-art robust structured pruning methods, CSTAR shows consistently better performance. For instance, when compressing ResNet-18 on CIFAR-10, CSTAR can achieve up to 20.07% and 11.91% improvement for benign accuracy and robust accuracy, respectively. For compressing ResNet-18 with 16x compression ratio on Imagenet, CSTAR can obtain 8.58% benign accuracy gain and 4.27% robust accuracy gain compared to the existing robust structured pruning method.
Modelling black-box audio effects with time-varying feature modulation
Nov 01, 2022



Deep learning approaches for black-box modelling of audio effects have shown promise, however, the majority of existing work focuses on nonlinear effects with behaviour on relatively short time-scales, such as guitar amplifiers and distortion. While recurrent and convolutional architectures can theoretically be extended to capture behaviour at longer time scales, we show that simply scaling the width, depth, or dilation factor of existing architectures does not result in satisfactory performance when modelling audio effects such as fuzz and dynamic range compression. To address this, we propose the integration of time-varying feature-wise linear modulation into existing temporal convolutional backbones, an approach that enables learnable adaptation of the intermediate activations. We demonstrate that our approach more accurately captures long-range dependencies for a range of fuzz and compressor implementations across both time and frequency domain metrics. We provide sound examples, source code, and pretrained models to faciliate reproducibility.
Personalized Longitudinal Assessment of Multiple Sclerosis Using Smartphones
Sep 20, 2022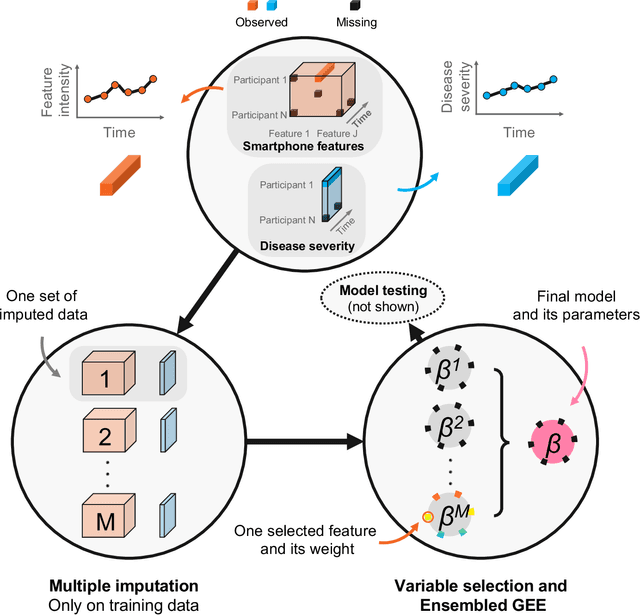

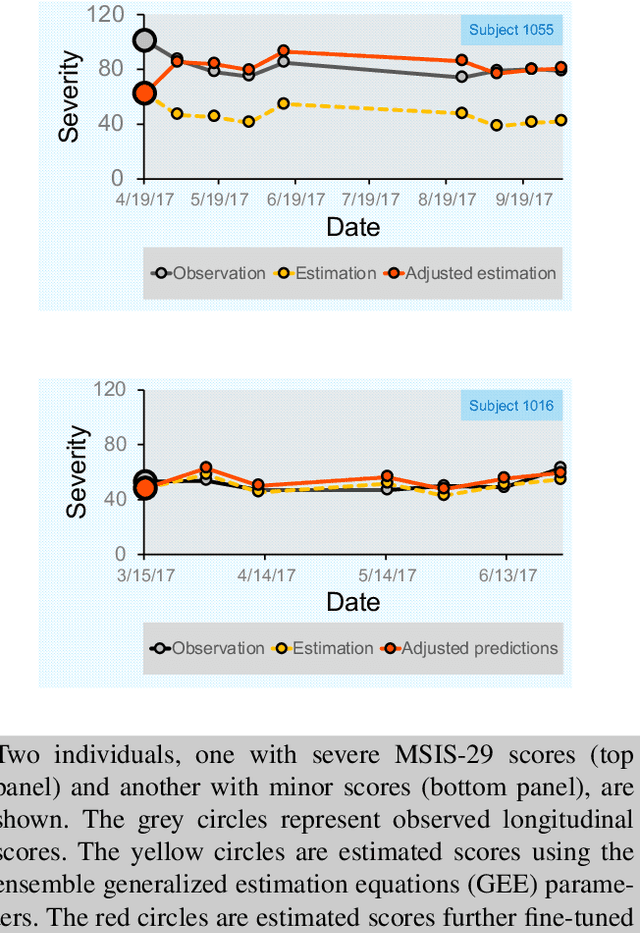
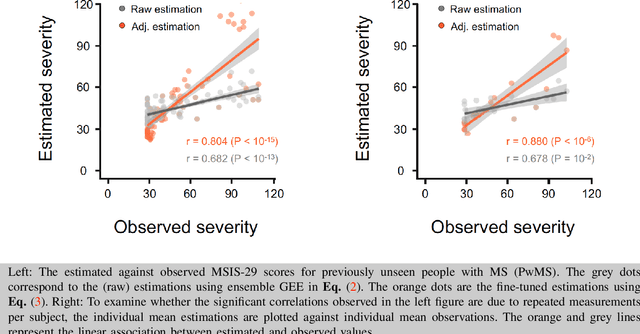
Personalized longitudinal disease assessment is central to quickly diagnosing, appropriately managing, and optimally adapting the therapeutic strategy of multiple sclerosis (MS). It is also important for identifying the idiosyncratic subject-specific disease profiles. Here, we design a novel longitudinal model to map individual disease trajectories in an automated way using sensor data that may contain missing values. First, we collect digital measurements related to gait and balance, and upper extremity functions using sensor-based assessments administered on a smartphone. Next, we treat missing data via imputation. We then discover potential markers of MS by employing a generalized estimation equation. Subsequently, parameters learned from multiple training datasets are ensembled to form a simple, unified longitudinal predictive model to forecast MS over time in previously unseen people with MS. To mitigate potential underestimation for individuals with severe disease scores, the final model incorporates additional subject-specific fine-tuning using data from the first day. The results show that the proposed model is promising to achieve personalized longitudinal MS assessment; they also suggest that features related to gait and balance as well as upper extremity function, remotely collected from sensor-based assessments, may be useful digital markers for predicting MS over time.
RIBAC: Towards Robust and Imperceptible Backdoor Attack against Compact DNN
Aug 22, 2022
Recently backdoor attack has become an emerging threat to the security of deep neural network (DNN) models. To date, most of the existing studies focus on backdoor attack against the uncompressed model; while the vulnerability of compressed DNNs, which are widely used in the practical applications, is little exploited yet. In this paper, we propose to study and develop Robust and Imperceptible Backdoor Attack against Compact DNN models (RIBAC). By performing systematic analysis and exploration on the important design knobs, we propose a framework that can learn the proper trigger patterns, model parameters and pruning masks in an efficient way. Thereby achieving high trigger stealthiness, high attack success rate and high model efficiency simultaneously. Extensive evaluations across different datasets, including the test against the state-of-the-art defense mechanisms, demonstrate the high robustness, stealthiness and model efficiency of RIBAC. Code is available at https://github.com/huyvnphan/ECCV2022-RIBAC
* Code is available at https://github.com/huyvnphan/ECCV2022-RIBAC