 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity R-C3D for Few-shot Temporal Activity Detection
Dec 25, 2018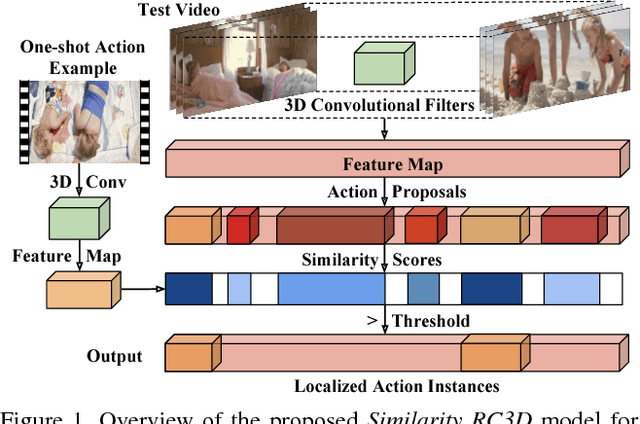
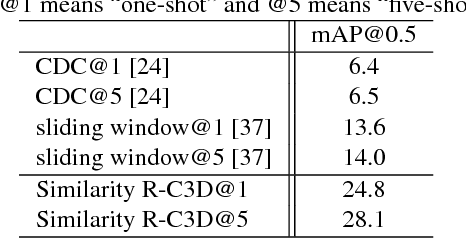
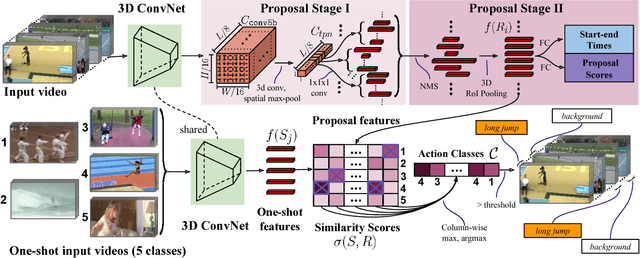
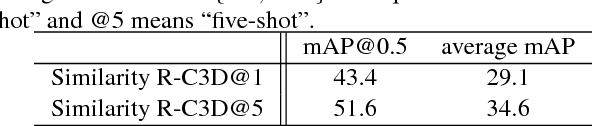
Many activities of interest are rare events, with only a few labeled examples available. Therefore models for temporal activity detection which are able to learn from a few examples are desirable. In this paper, we present a conceptually simple and general yet novel framework for few-shot temporal activity detection which detects the start and end time of the few-shot input activities in an untrimmed video. Our model is end-to-end trainable and can benefit from more few-shot examples. At test time, each proposal is assigned the label of the few-shot activity class corresponding to the maximum similarity score. Our Similarity R-C3D method outperforms previous work on three large-scale benchmarks for temporal activity detection (THUMOS14, ActivityNet1.2, and ActivityNet1.3 datasets) in the few-shot setting. Our code will be made available.
Classifying Collisions with Spatio-Temporal Action Graph Networks
Dec 04, 2018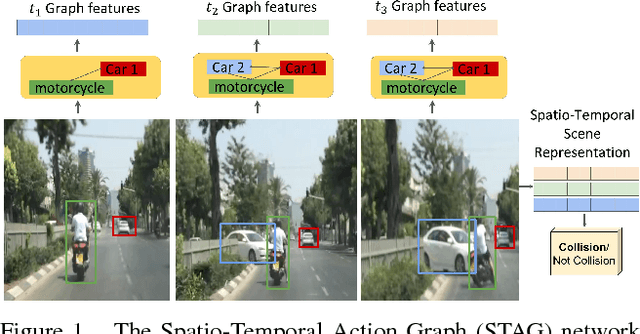
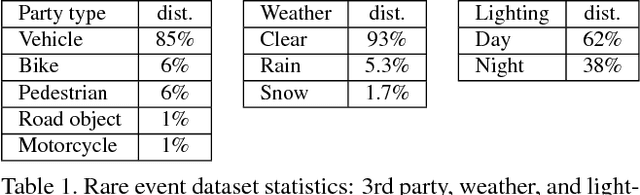
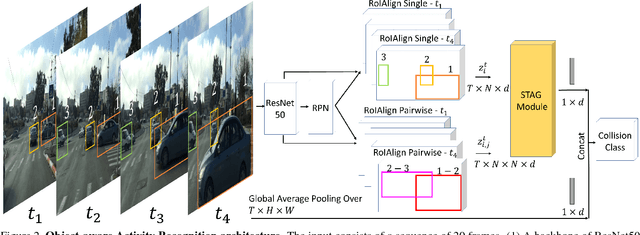
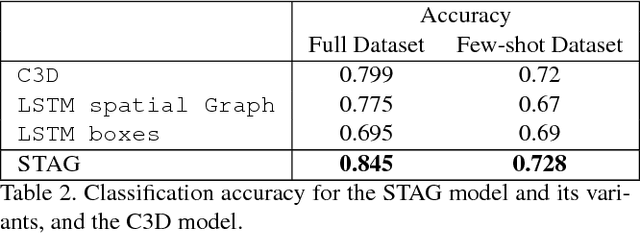
Events defined by the interaction of objects in a scene often are of critical importance, yet such events are typically rare and available labeled examples insufficient to train a conventional deep model that performs well across expected object appearances. Most deep learning activity recognition models focus on global context aggregation and do not explicitly consider object interactions inside the video, potentially overlooking important cues relevant to interpreting activity in the scene. In this paper, we show that a new model for explicit representation of object interactions significantly improves deep video activity classification for driving collision detection. We propose a Spatio-Temporal Action Graph (STAG) network, which incorporates spatial and temporal relations of objects. The network is automatically learned from data, with a latent graph structure inferred for the task. As a benchmark to evaluate performance on collision detection tasks, we introduce a novel data set based on data obtained from real life driving collisions and near-collisions. This data set reflects the challenging task of detecting and classifying accidents in a richly varying but yet highly constrained setting, that is very relevant to the evaluation of autonomous driving and alerting systems. Our experiments confirm that our STAG model offers significantly improved results for collision activity classification.
A Two-Stream Variational Adversarial Network for Video Generation
Dec 03, 2018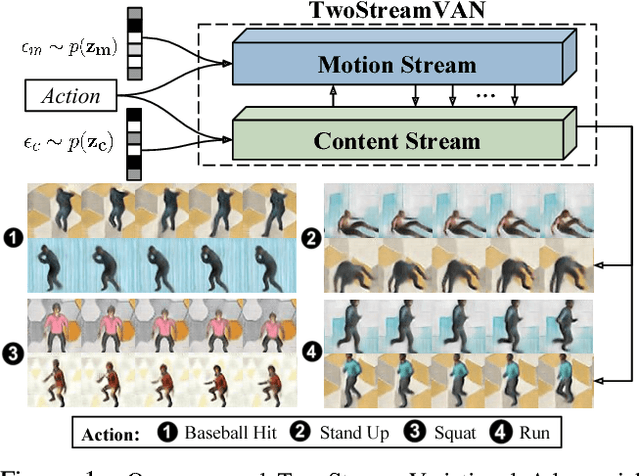
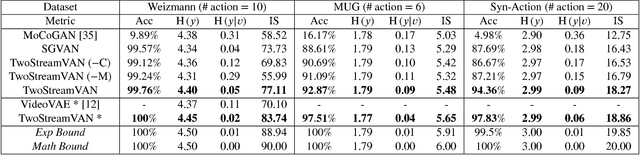
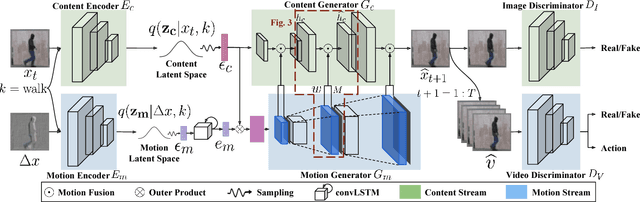

Video generation is an inherently challenging task, as it requires the model to generate realistic content and motion simultaneously. Existing methods generate both motion and content together using a single generator network, but this approach may fail on complex videos. In this paper, we propose a two-stream video generation model that separates content and motion generation into two parallel generators, called Two-Stream Variational Adversarial Network (TwoStreamVAN). Our model outputs a realistic video given an input action label by progressively generating and fusing motion and content features at multiple scales using adaptive motion kernels. In addition, to better evaluate video generation models, we design a new synthetic human action dataset to bridge the difficulty gap between over-complicated human action datasets and simple toy datasets. Our model significantly outperforms existing methods on the standard Weizmann Human Action and MUG Facial Expression datasets, as well as our new dataset.
Multilevel Language and Vision Integration for Text-to-Clip Retrieval
Sep 27, 2018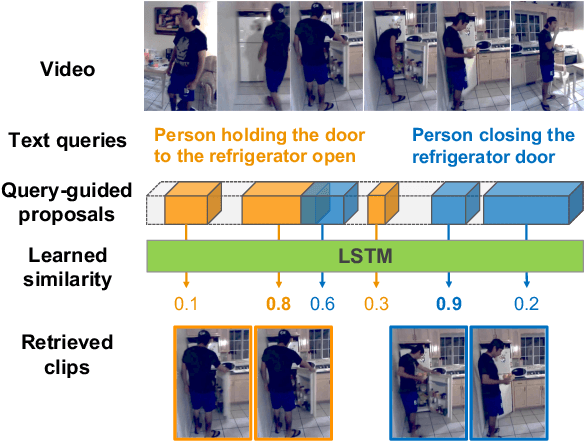
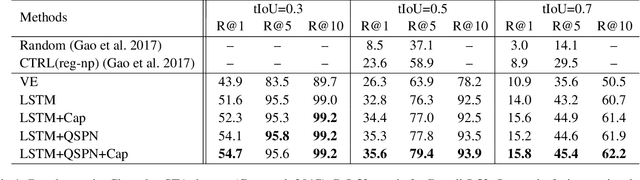
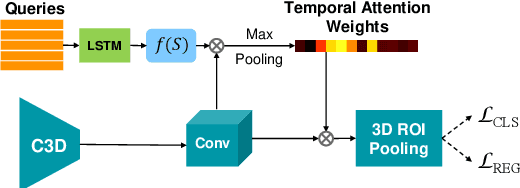
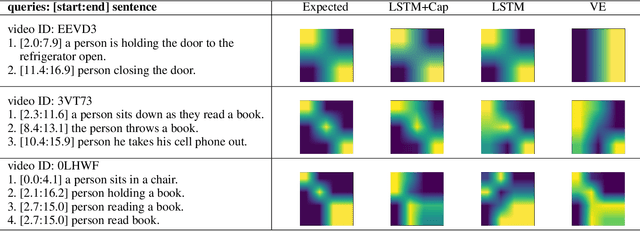
We address the problem of text-based activity retrieval in video. Given a sentence describing an activity, our task is to retrieve matching clips from an untrimmed video. To capture the inherent structures present in both text and video, we introduce a multilevel model that integrates vision and language features earlier and more tightly than prior work. First, we inject text features early on when generating clip proposals, to help eliminate unlikely clips and thus speed up processing and boost performance. Second, to learn a fine-grained similarity metric for retrieval, we use visual features to modulate the processing of query sentences at the word level in a recurrent neural network. A multi-task loss is also employed by adding query re-generation as an auxiliary task. Our approach significantly outperforms prior work on two challenging benchmarks: Charades-STA and ActivityNet Captions.
Joint Event Detection and Description in Continuous Video Streams
Apr 13, 2018
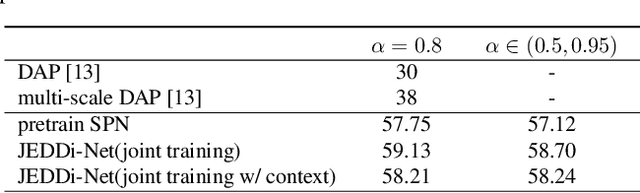
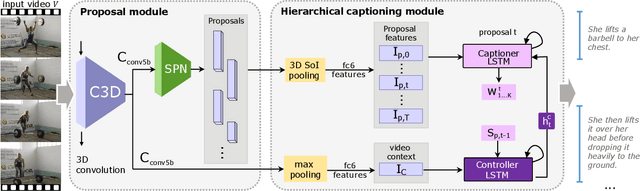
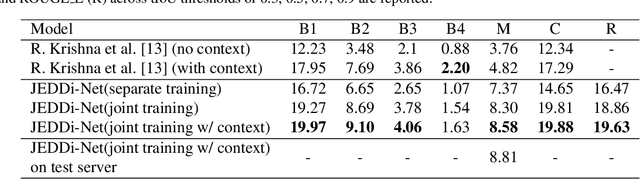
Dense video captioning is a fine-grained video understanding task that involves two sub-problems: localizing distinct events in a long video stream, and generating captions for the localized events. We propose the Joint Event Detection and Description Network (JEDDi-Net), which solves the dense video captioning task in an end-to-end fashion. Our model continuously encodes the input video stream with three-dimensional convolutional layers, proposes variable-length temporal events based on pooled features, and generates their captions. Unlike existing approaches, our event proposal generation and language captioning networks are trained jointly and end-to-end, allowing for improved temporal segmentation. In order to explicitly model temporal relationships between visual events and their captions in a single video, we also propose a two-level hierarchical captioning module that keeps track of context. On the large-scale ActivityNet Captions dataset, JEDDi-Net demonstrates improved results as measured by standard metrics. We also present the first dense captioning results on the TACoS-MultiLevel dataset.
Contextual Multi-Scale Region Convolutional 3D Network for Activity Detection
Jan 28, 2018

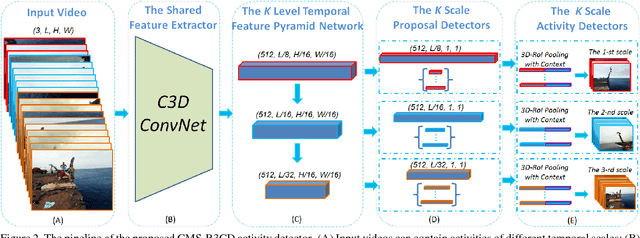
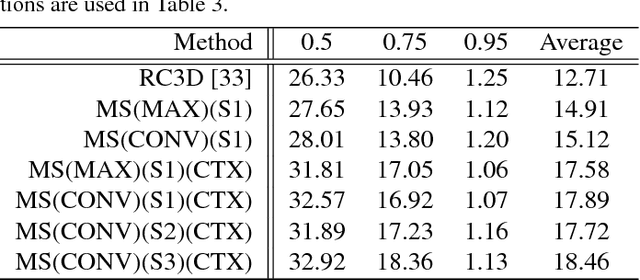
Activity detection is a fundamental problem in computer vision. Detecting activities of different temporal scales is particularly challenging. In this paper, we propose the contextual multi-scale region convolutional 3D network (CMS-RC3D) for activity detection. To deal with the inherent temporal scale variability of activity instances, the temporal feature pyramid is used to represent activities of different temporal scales. On each level of the temporal feature pyramid, an activity proposal detector and an activity classifier are learned to detect activities of specific temporal scales. Temporal contextual information is fused into activity classifiers for better recognition. More importantly, the entire model at all levels can be trained end-to-end. Our CMS-RC3D detector can deal with activities at all temporal scale ranges with only a single pass through the backbone network. We test our detector on two public activity detection benchmarks, THUMOS14 and ActivityNet. Extensive experiments show that the proposed CMS-RC3D detector outperforms state-of-the-art methods on THUMOS14 by a substantial margin and achieves comparable results on ActivityNet despite using a shallow feature extractor.
R-C3D: Region Convolutional 3D Network for Temporal Activity Detection
Aug 04, 2017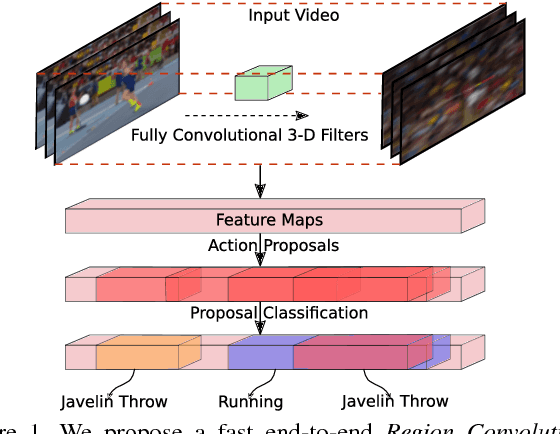
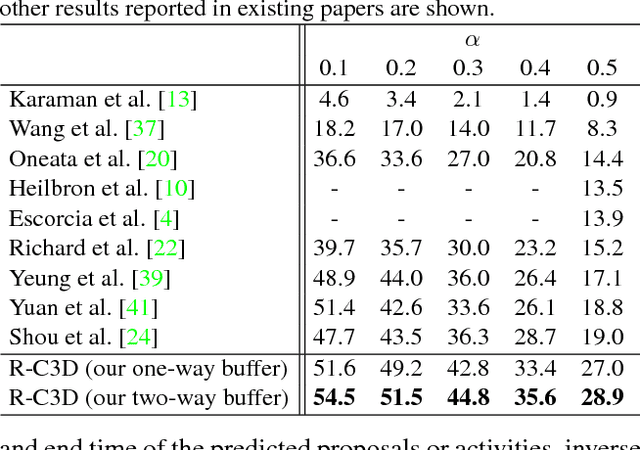

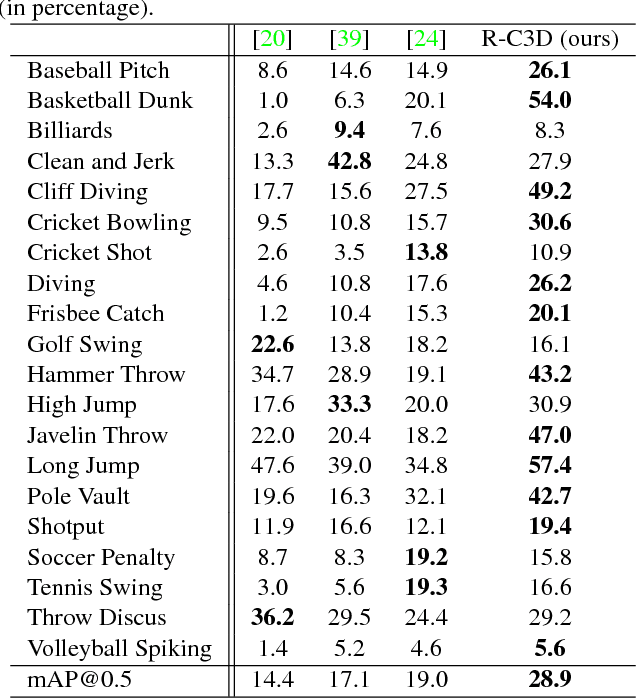
We address the problem of activity detection in continuous, untrimmed video streams. This is a difficult task that requires extracting meaningful spatio-temporal features to capture activities, accurately localizing the start and end times of each activity. We introduce a new model, Region Convolutional 3D Network (R-C3D), which encodes the video streams using a three-dimensional fully convolutional network, then generates candidate temporal regions containing activities, and finally classifies selected regions into specific activities. Computation is saved due to the sharing of convolutional features between the proposal and the classification pipelines. The entire model is trained end-to-end with jointly optimized localization and classification losses. R-C3D is faster than existing methods (569 frames per second on a single Titan X Maxwell GPU) and achieves state-of-the-art results on THUMOS'14. We further demonstrate that our model is a general activity detection framework that does not rely on assumptions about particular dataset properties by evaluating our approach on ActivityNet and Charades. Our code is available at http://ai.bu.edu/r-c3d/.
* ICCV 2017 Camera Ready Version
Ask, Attend and Answer: Exploring Question-Guided Spatial Attention for Visual Question Answering
Mar 19, 2016
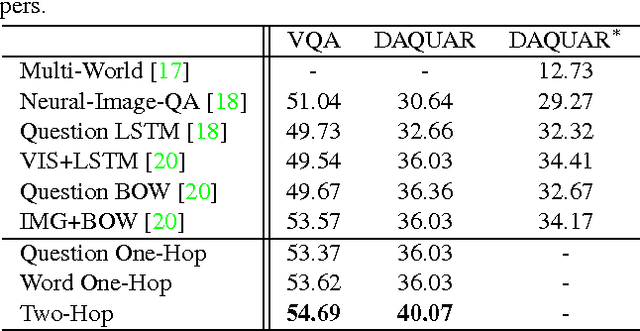
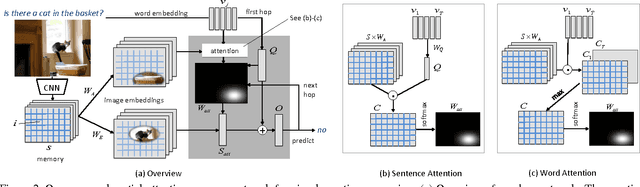
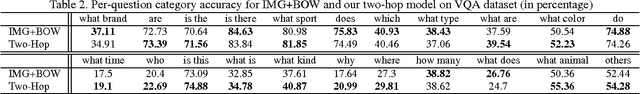
We address the problem of Visual Question Answering (VQA), which requires joint image and language understanding to answer a question about a given photograph. Recent approaches have applied deep image captioning methods based on convolutional-recurrent networks to this problem, but have failed to model spatial inference. To remedy this, we propose a model we call the Spatial Memory Network and apply it to the VQA task. Memory networks are recurrent neural networks with an explicit attention mechanism that selects certain parts of the information stored in memory. Our Spatial Memory Network stores neuron activations from different spatial regions of the image in its memory, and uses the question to choose relevant regions for computing the answer, a process of which constitutes a single "hop" in the network. We propose a novel spatial attention architecture that aligns words with image patches in the first hop, and obtain improved results by adding a second attention hop which considers the whole question to choose visual evidence based on the results of the first hop. To better understand the inference process learned by the network, we design synthetic questions that specifically require spatial inference and visualize the attention weights. We evaluate our model on two published visual question answering datasets, DAQUAR [1] and VQA [2], and obtain improved results compared to a strong deep baseline model (iBOWIMG) which concatenates image and question features to predict the answer [3].
A Multi-scale Multiple Instance Video Description Network
Mar 19, 2016
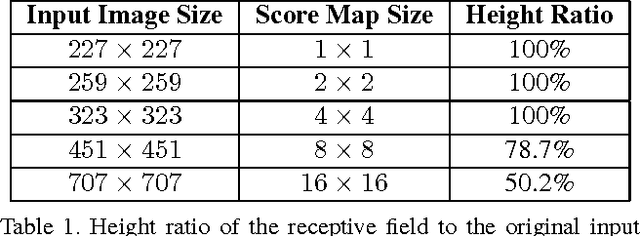
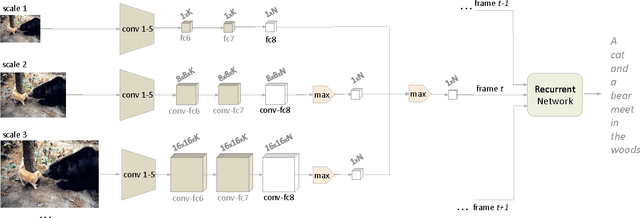
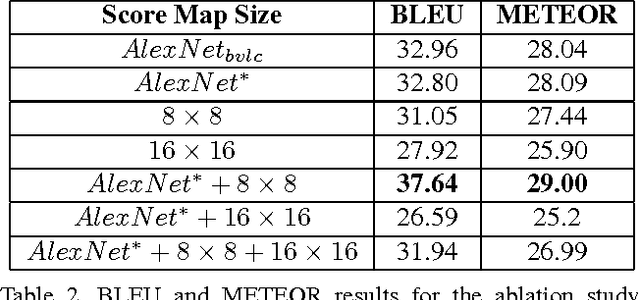
Generating natural language descriptions for in-the-wild videos is a challenging task. Most state-of-the-art methods for solving this problem borrow existing deep convolutional neural network (CNN) architectures (AlexNet, GoogLeNet) to extract a visual representation of the input video. However, these deep CNN architectures are designed for single-label centered-positioned object classification. While they generate strong semantic features, they have no inherent structure allowing them to detect multiple objects of different sizes and locations in the frame. Our paper tries to solve this problem by integrating the base CNN into several fully convolutional neural networks (FCNs) to form a multi-scale network that handles multiple receptive field sizes in the original image. FCNs, previously applied to image segmentation, can generate class heat-maps efficiently compared to sliding window mechanisms, and can easily handle multiple scales. To further handle the ambiguity over multiple objects and locations, we incorporate the Multiple Instance Learning mechanism (MIL) to consider objects in different positions and at different scales simultaneously. We integrate our multi-scale multi-instance architecture with a sequence-to-sequence recurrent neural network to generate sentence descriptions based on the visual representation. Ours is the first end-to-end trainable architecture that is capable of multi-scale region processing. Evaluation on a Youtube video dataset shows the advantage of our approach compared to the original single-scale whole frame CNN model. Our flexible and efficient architecture can potentially be extended to support other video processing tasks.
Translating Videos to Natural Language Using Deep Recurrent Neural Networks
Apr 30, 2015
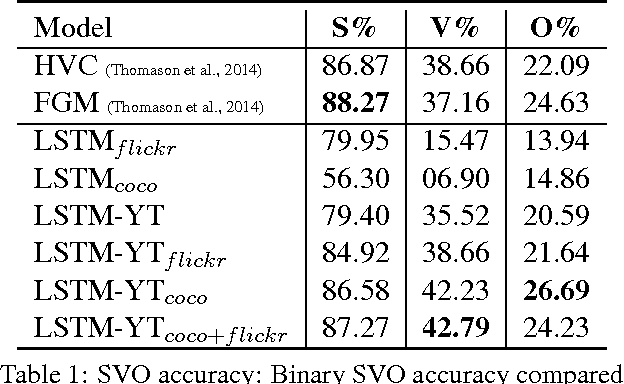
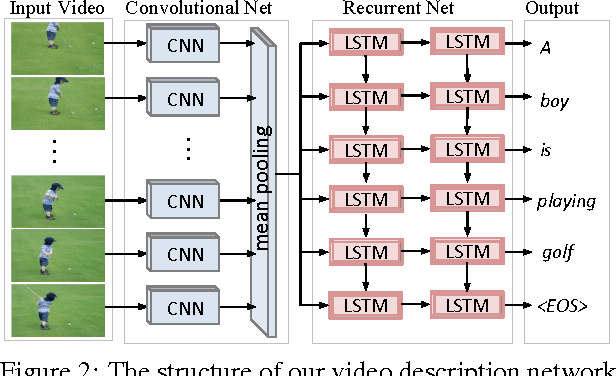
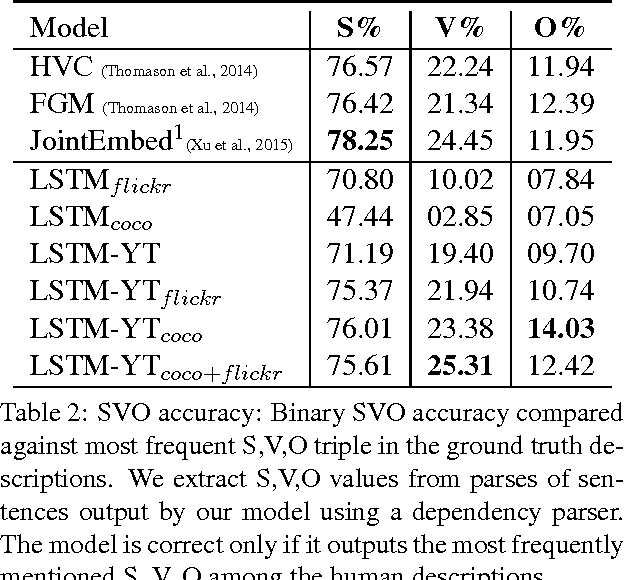
Solving the visual symbol grounding problem has long been a goal of artificial intelligence. The field appears to be advancing closer to this goal with recent breakthroughs in deep learning for natural language grounding in static images. In this paper, we propose to translate videos directly to sentences using a unified deep neural network with both convolutional and recurrent structure. Described video datasets are scarce, and most existing methods have been applied to toy domains with a small vocabulary of possible words. By transferring knowledge from 1.2M+ images with category labels and 100,000+ images with captions, our method is able to create sentence descriptions of open-domain videos with large vocabularies. We compare our approach with recent work using language generation metrics, subject, verb, and object prediction accuracy, and a human evaluation.