 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADE: Masked Autoencoder for Distribution Estimation
Jun 05, 2015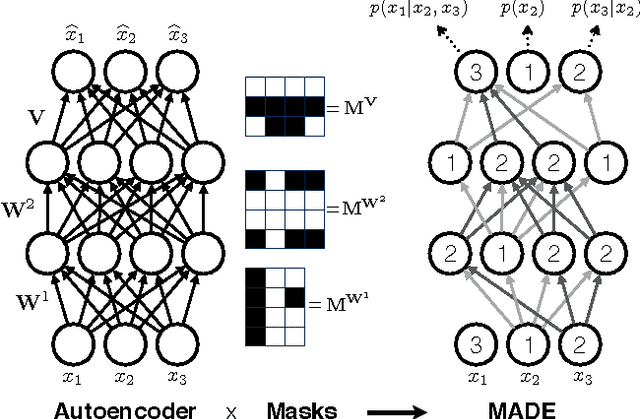
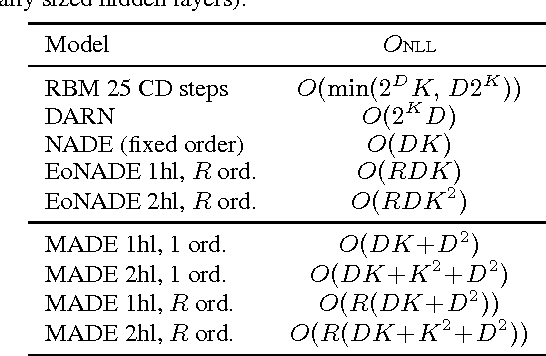
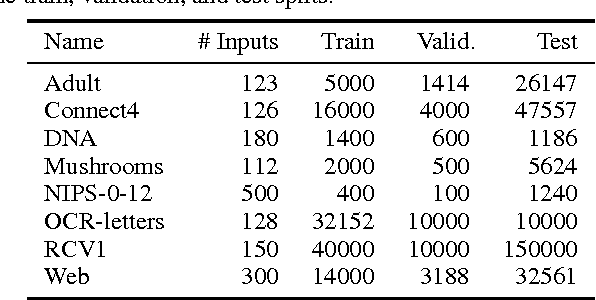
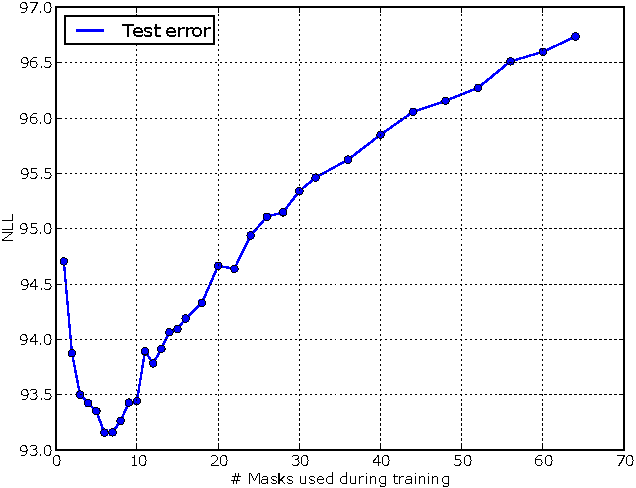
There has been a lot of recent interest in designing neural network models to estimate a distribution from a set of examples. We introduce a simple modification for autoencoder neural networks that yields powerful generative models. Our method masks the autoencoder's parameters to respect autoregressive constraints: each input is reconstructed only from previous inputs in a given ordering. Constrained this way, the autoencoder outputs can be interpreted as a set of conditional probabilities, and their product, the full joint probability. We can also train a single network that can decompose the joint probability in multiple different orderings. Our simple framework can be applied to multiple architectures, including deep ones. Vectorized implementations, such as on GPUs, are simple and fast. Experiments demonstrate that this approach is competitive with state-of-the-art tractable distribution estimators. At test time, the method is significantly faster and scales better than other autoregressive estimators.
* 9 pages and 1 page of supplementary material. Updated to match published version
Using Descriptive Video Services to Create a Large Data Source for Video Annotation Research
Mar 03, 2015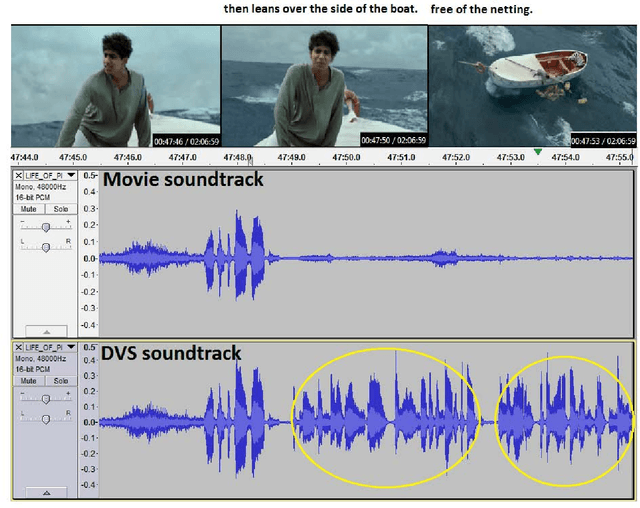

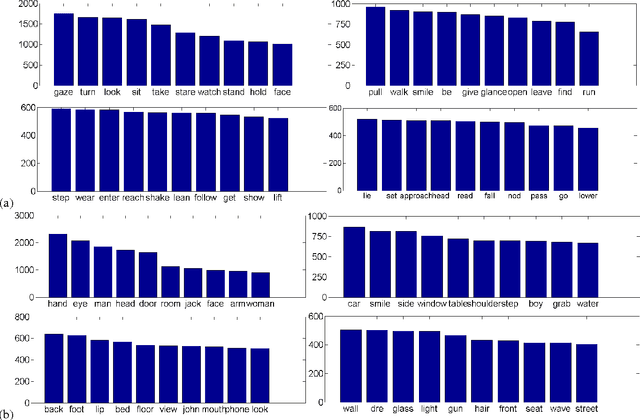
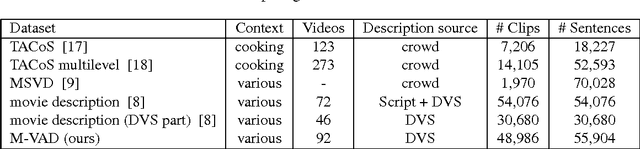
In this work, we introduce a dataset of video annotated with high quality natural language phrases describing the visual content in a given segment of time. Our dataset is based on the Descriptive Video Service (DVS) that is now encoded on many digital media products such as DVDs. DVS is an audio narration describing the visual elements and actions in a movie for the visually impaired. It is temporally aligned with the movie and mixed with the original movie soundtrack. We describe an automatic DVS segmentation and alignment method for movies, that enables us to scale up the collection of a DVS-derived dataset with minimal human intervention. Using this method, we have collected the largest DVS-derived dataset for video description of which we are aware. Our dataset currently includes over 84.6 hours of paired video/sentences from 92 DVDs and is growing.
Domain-Adversarial Neural Networks
Feb 09, 2015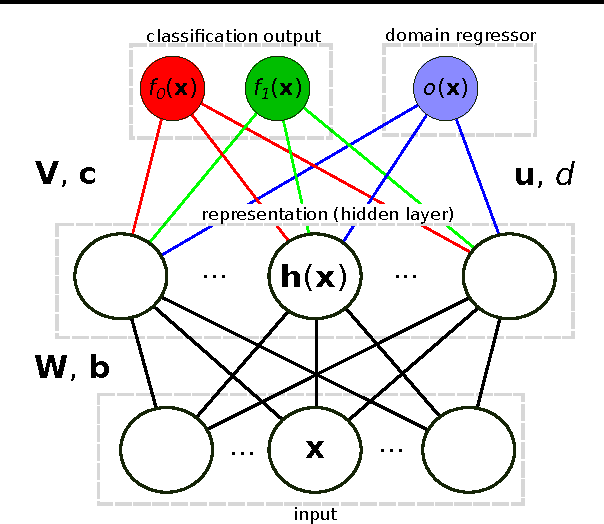
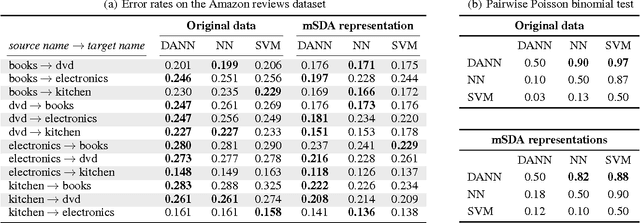
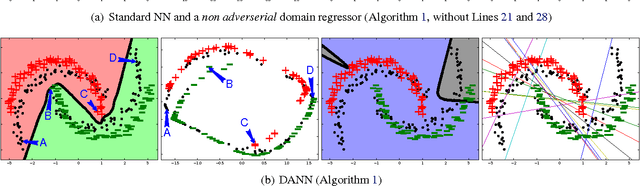
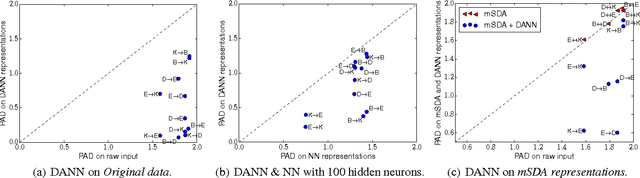
We introduce a new representation learning algorithm suited to the context of domain adaptation, in which data at training and test time come from similar but different distributions. Our algorithm is directly inspired by theory on domain adaptation suggesting that, for effective domain transfer to be achieved, predictions must be made based on a data representation that cannot discriminate between the training (source) and test (target) domains. We propose a training objective that implements this idea in the context of a neural network, whose hidden layer is trained to be predictive of the classification task, but uninformative as to the domain of the input. Our experiments on a sentiment analysis classification benchmark, where the target domain data available at training time is unlabeled, show that our neural network for domain adaption algorithm has better performance than either a standard neural network or an SVM, even if trained on input features extracted with the state-of-the-art marginalized stacked denoising autoencoders of Chen et al. (2012).
An Autoencoder Approach to Learning Bilingual Word Representations
Feb 06, 2014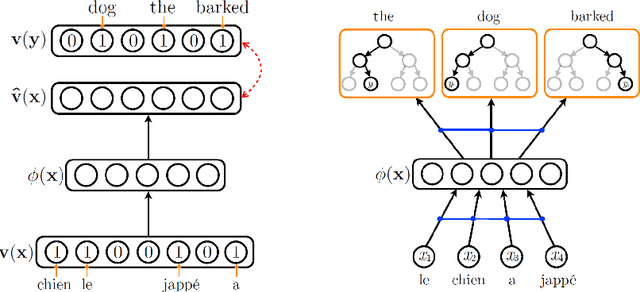
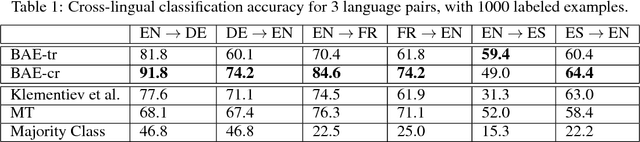

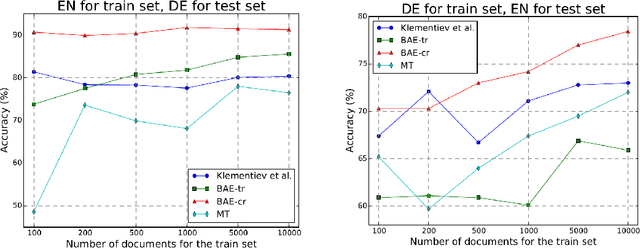
Cross-language learning allows us to use training data from one language to build models for a different language. Many approaches to bilingual learning require that we have word-level alignment of sentences from parallel corpora. In this work we explore the use of autoencoder-based methods for cross-language learning of vectorial word representations that are aligned between two languages, while not relying on word-level alignments. We show that by simply learning to reconstruct the bag-of-words representations of aligned sentences, within and between languages, we can in fact learn high-quality representations and do without word alignments. Since training autoencoders on word observations presents certain computational issues, we propose and compare different variations adapted to this setting. We also propose an explicit correlation maximizing regularizer that leads to significant improvement in the performance. We empirically investigate the success of our approach on the problem of cross-language test classification, where a classifier trained on a given language (e.g., English) must learn to generalize to a different language (e.g., German). These experiments demonstrate that our approaches are competitive with the state-of-the-art, achieving up to 10-14 percentage point improvements over the best reported results on this task.
Sequential Model-Based Ensemble Optimization
Feb 04, 2014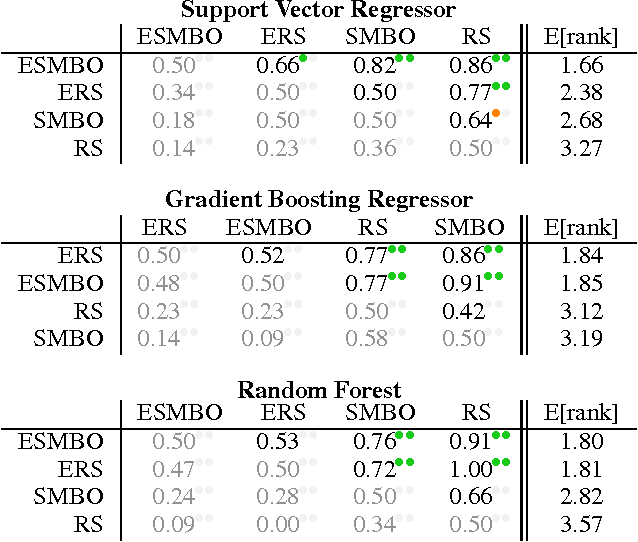
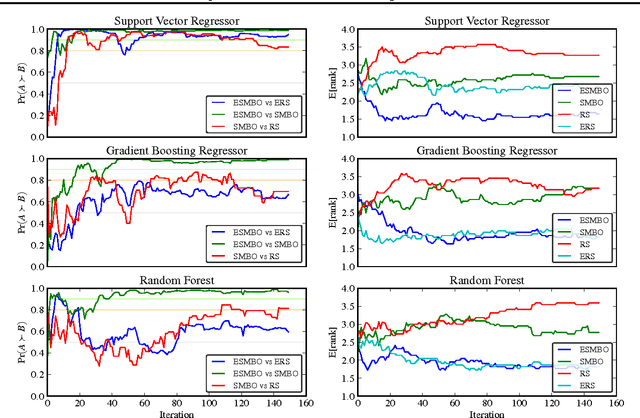
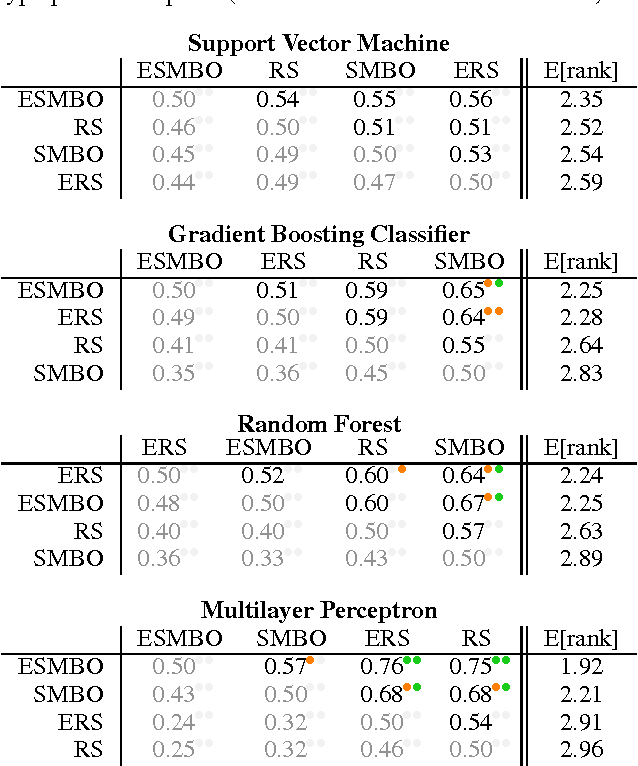
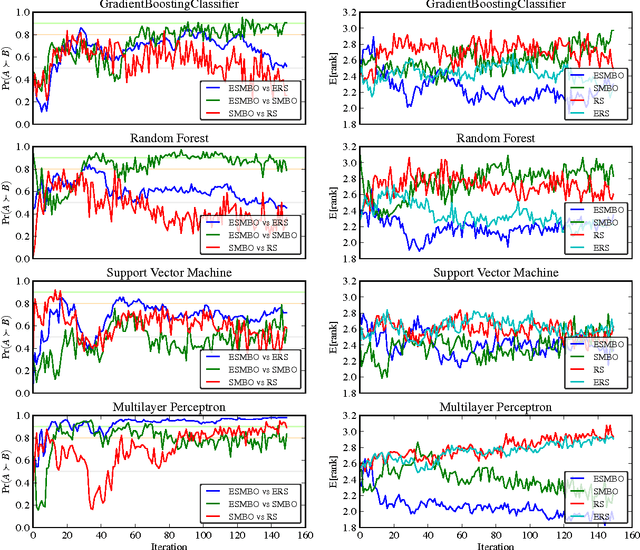
One of the most tedious tasks in the application of machine learning is model selection, i.e. hyperparameter selection. Fortunately, recent progress has been made in the automation of this process, through the use of sequential model-based optimization (SMBO) methods. This can be used to optimize a cross-validation performance of a learning algorithm over the value of its hyperparameters. However, it is well known that ensembles of learned models almost consistently outperform a single model, even if properly selected. In this paper, we thus propose an extension of SMBO methods that automatically constructs such ensembles. This method builds on a recently proposed ensemble construction paradigm known as agnostic Bayesian learning. In experiments on 22 regression and 39 classification data sets, we confirm the success of this proposed approach, which is able to outperform model selection with SMBO.
A Deep and Tractable Density Estimator
Jan 11, 2014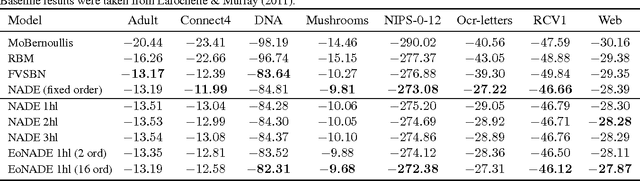
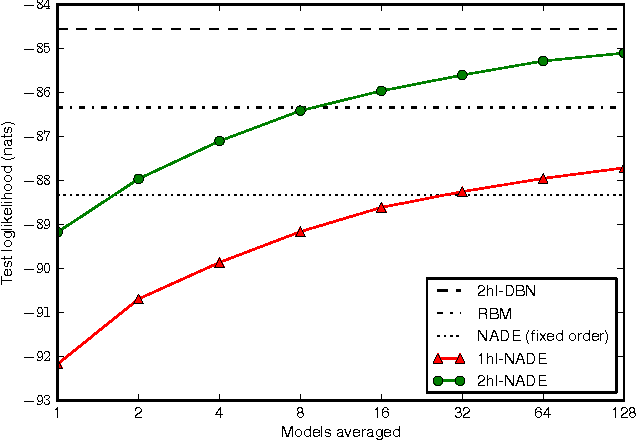

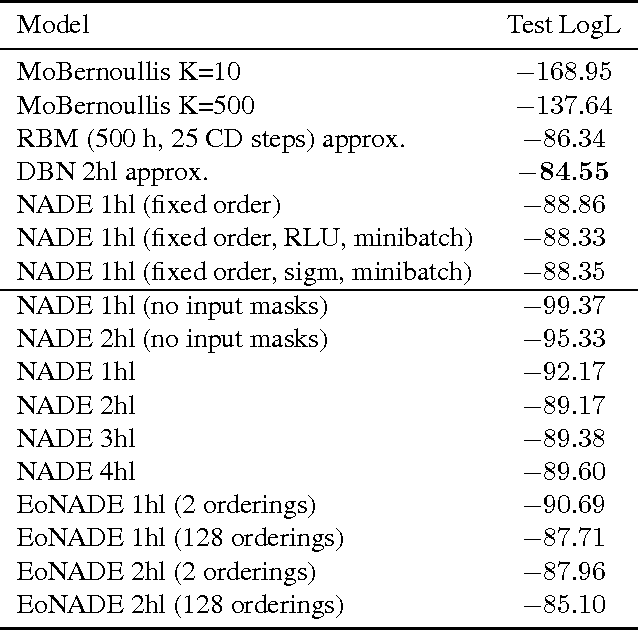
The Neural Autoregressive Distribution Estimator (NADE) and its real-valued version RNADE are competitive density models of multidimensional data across a variety of domains. These models use a fixed, arbitrary ordering of the data dimensions. One can easily condition on variables at the beginning of the ordering, and marginalize out variables at the end of the ordering, however other inference tasks require approximate inference. In this work we introduce an efficient procedure to simultaneously train a NADE model for each possible ordering of the variables, by sharing parameters across all these models. We can thus use the most convenient model for each inference task at hand, and ensembles of such models with different orderings are immediately available. Moreover, unlike the original NADE, our training procedure scales to deep models. Empirically, ensembles of Deep NADE models obtain state of the art density estimation performance.
RNADE: The real-valued neural autoregressive density-estimator
Jan 09, 2014

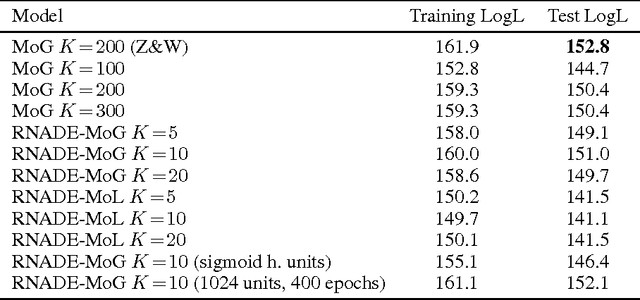

We introduce RNADE, a new model for joint density estimation of real-valued vectors. Our model calculates the density of a datapoint as the product of one-dimensional conditionals modeled using mixture density networks with shared parameters. RNADE learns a distributed representation of the data, while having a tractable expression for the calculation of densities. A tractable likelihood allows direct comparison with other methods and training by standard gradient-based optimizers. We compare the performance of RNADE on several datasets of heterogeneous and perceptual data, finding it outperforms mixture models in all but one case.
* 12 pages, 3 figures, 3 tables, 2 algorithms. Merges the published paper and supplementary material into one document
Learning Multilingual Word Representations using a Bag-of-Words Autoencoder
Jan 08, 2014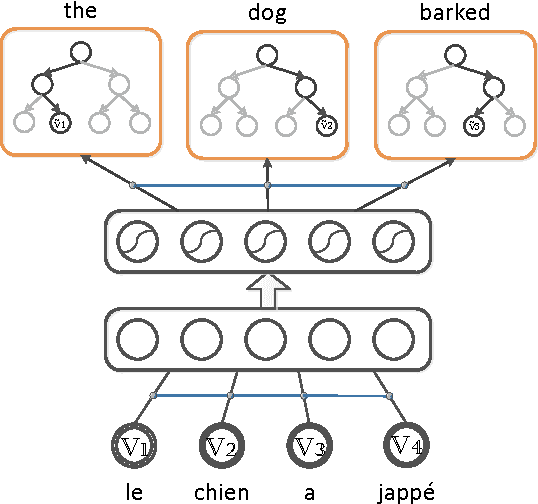
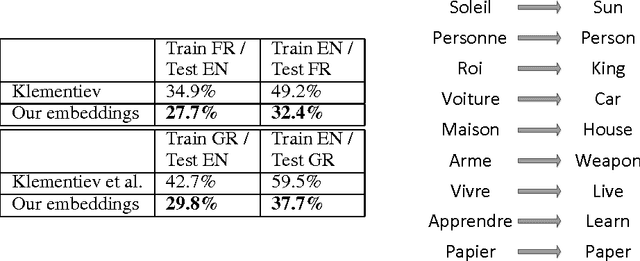

Recent work on learning multilingual word representations usually relies on the use of word-level alignements (e.g. infered with the help of GIZA++) between translated sentences, in order to align the word embeddings in different languages. In this workshop paper, we investigate an autoencoder model for learning multilingual word representations that does without such word-level alignements. The autoencoder is trained to reconstruct the bag-of-word representation of given sentence from an encoded representation extracted from its translation. We evaluate our approach on a multilingual document classification task, where labeled data is available only for one language (e.g. English) while classification must be performed in a different language (e.g. French). In our experiments, we observe that our method compares favorably with a previously proposed method that exploits word-level alignments to learn word representations.
A Supervised Neural Autoregressive Topic Model for Simultaneous Image Classification and Annotation
May 23, 2013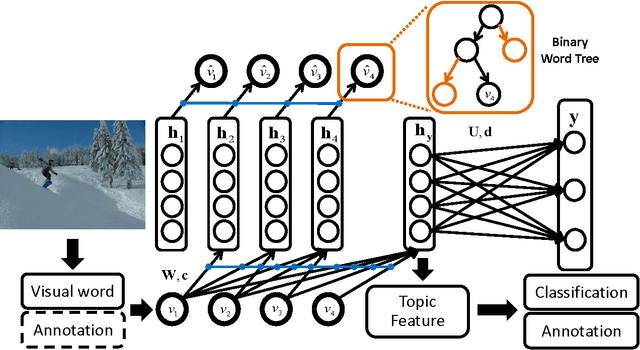
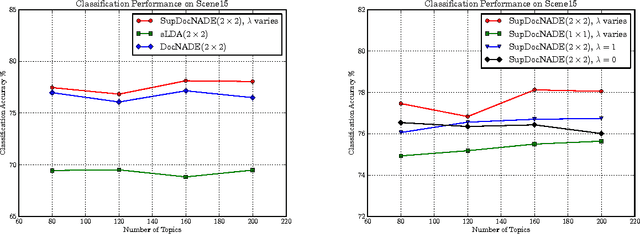
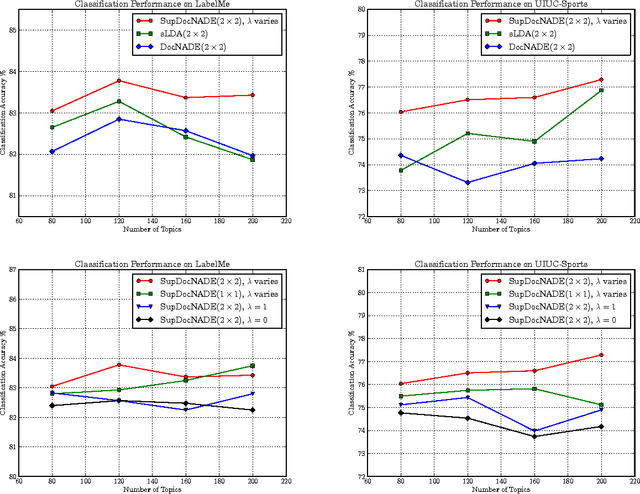

Topic modeling based on latent Dirichlet allocation (LDA) has been a framework of choice to perform scene recognition and annotation. Recently, a new type of topic model called the Document Neural Autoregressive Distribution Estimator (DocNADE) was proposed and demonstrated state-of-the-art performance for document modeling. In this work, we show how to successfully apply and extend this model to the context of visual scene modeling. Specifically, we propose SupDocNADE, a supervised extension of DocNADE, that increases the discriminative power of the hidden topic features by incorporating label information into the training objective of the model. We also describe how to leverage information about the spatial position of the visual words and how to embed additional image annotations, so as to simultaneously perform image classification and annotation. We test our model on the Scene15, LabelMe and UIUC-Sports datasets and show that it compares favorably to other topic models such as the supervised variant of LDA.
Practical Bayesian Optimization of Machine Learning Algorithms
Aug 29, 2012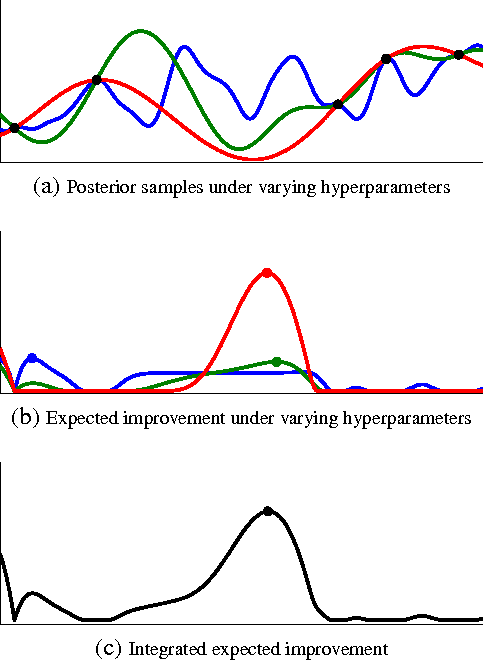
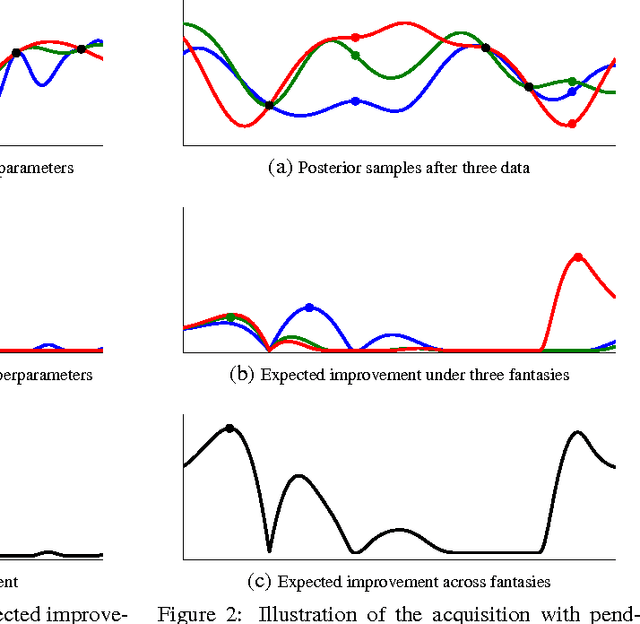
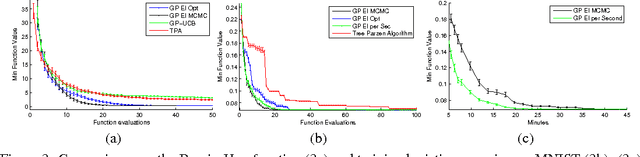
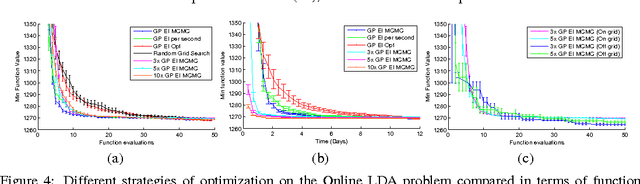
Machine learning algorithms frequently require careful tuning of model hyperparameters, regularization terms, and optimization parameters. Unfortunately, this tuning is often a "black art" that requires expert experience, unwritten rules of thumb, or sometimes brute-force search. Much more appealing is the idea of developing automatic approaches which can optimize the performance of a given learning algorithm to the task at hand. In this work, we consider the automatic tuning problem within the framework of Bayesian optimization, in which a learning algorithm's generalization performance is modeled as a sample from a Gaussian process (GP). The tractable posterior distribution induced by the GP leads to efficient use of the information gathered by previous experiments, enabling optimal choices about what parameters to try next. Here we show how the effects of the Gaussian process prior and the associated inference procedure can have a large impact on the success or failure of Bayesian optimization. We show that thoughtful choices can lead to results that exceed expert-level performance in tuning machine learning algorithms. We also describe new algorithms that take into account the variable cost (duration) of learning experiments and that can leverage the presence of multiple cores for parallel experimentation. We show that these proposed algorithms improve on previous automatic procedures and can reach or surpass human expert-level optimization on a diverse set of contemporary algorithms including latent Dirichlet allocation, structured SVMs and convolutional neural networks.