 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotionLines: An Emotion Corpus of Multi-Party Conversations
May 30, 2018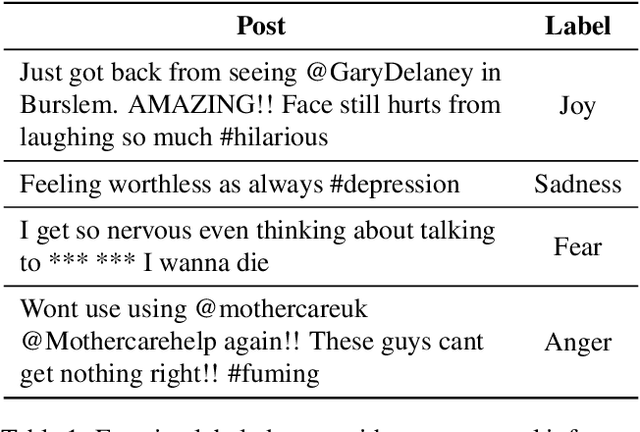


Feeling emotion is a critical characteristic to distinguish people from machines. Among all the multi-modal resources for emotion detection, textual datasets are those containing the least additional information in addition to semantics, and hence are adopted widely for testing the developed systems. However, most of the textual emotional datasets consist of emotion labels of only individual words, sentences or documents, which makes it challenging to discuss the contextual flow of emotions. In this paper, we introduce EmotionLines, the first dataset with emotions labeling on all utterances in each dialogue only based on their textual content. Dialogues in EmotionLines are collected from Friends TV scripts and private Facebook messenger dialogues. Then one of seven emotions, six Ekman's basic emotions plus the neutral emotion, is labeled on each utterance by 5 Amazon MTurkers. A total of 29,245 utterances from 2,000 dialogues are labeled in EmotionLines. We also provide several strong baselines for emotion detection models on EmotionLines in this paper.
Challenges in Providing Automatic Affective Feedback in Instant Messaging Applications
Feb 09, 2017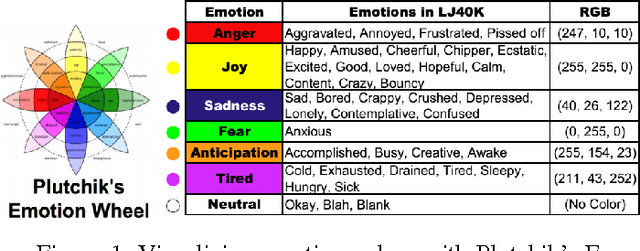
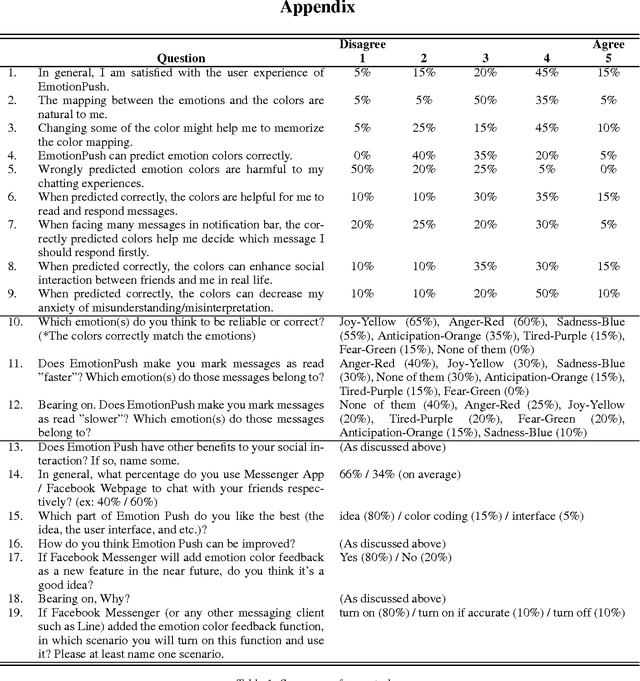
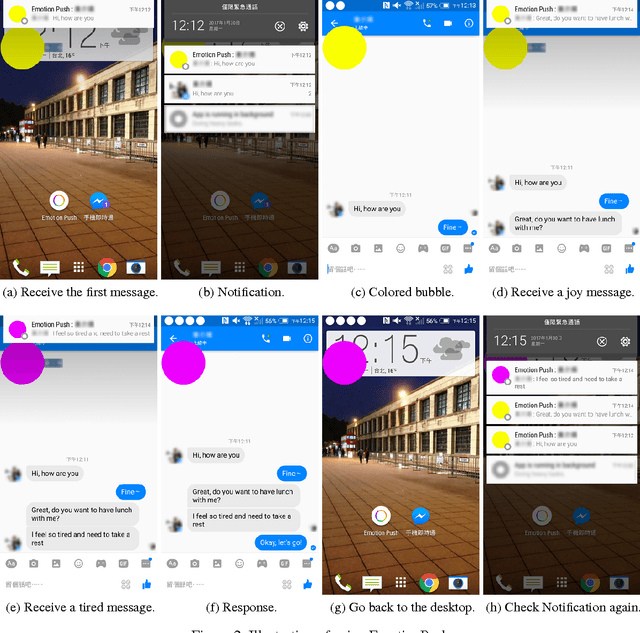
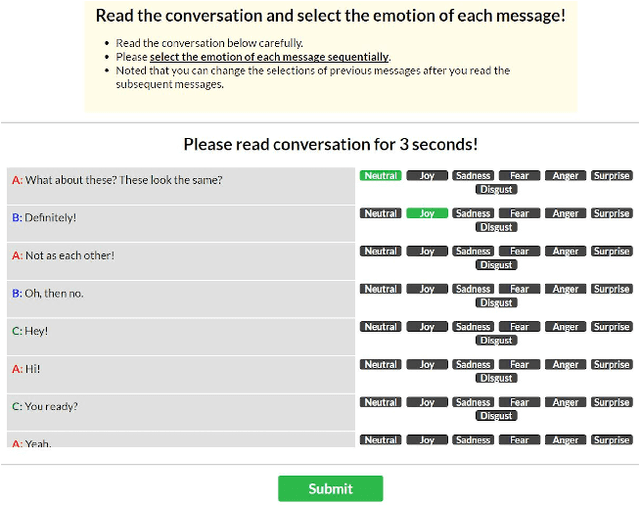
Instant messaging is one of the major channels of computer mediated communication. However, humans are known to be very limited in understanding others' emotions via text-based communication. Aiming on introducing emotion sensing technologies to instant messaging, we developed EmotionPush, a system that automatically detects the emotions of the messages end-users received on Facebook Messenger and provides colored cues on their smartphones accordingly. We conducted a deployment study with 20 participants during a time span of two weeks. In this paper, we revealed five challenges, along with examples, that we observed in our study based on both user's feedback and chat logs, including (i)the continuum of emotions, (ii)multi-user conversations, (iii)different dynamics between different users, (iv)misclassification of emotions and (v)unconventional content. We believe this discussion will benefit the future exploration of affective computing for instant messaging, and also shed light on research of conversational emotion sensing.
Visual Storytelling
Apr 13, 2016

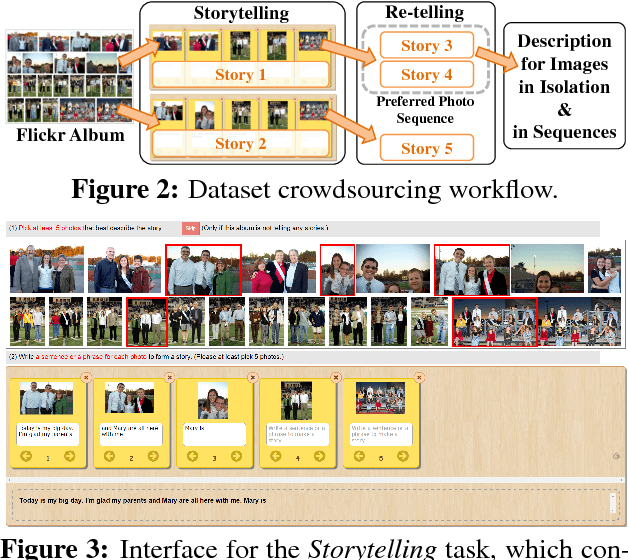
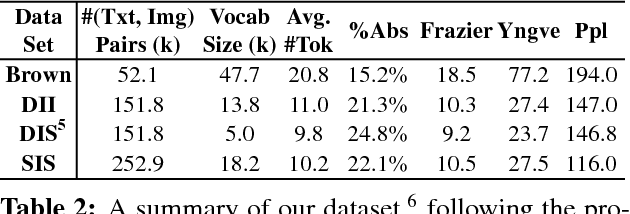
We introduce the first dataset for sequential vision-to-language, and explore how this data may be used for the task of visual storytelling. The first release of this dataset, SIND v.1, includes 81,743 unique photos in 20,211 sequences, aligned to both descriptive (caption) and story language. We establish several strong baselines for the storytelling task, and motivate an automatic metric to benchmark progress. Modelling concrete description as well as figurative and social language, as provided in this dataset and the storytelling task, has the potential to move artificial intelligence from basic understandings of typical visual scenes towards more and more human-like understanding of grounded event structure and subjective expression.
Approximate Message Passing with Nearest Neighbor Sparsity Pattern Learning
Jan 04, 2016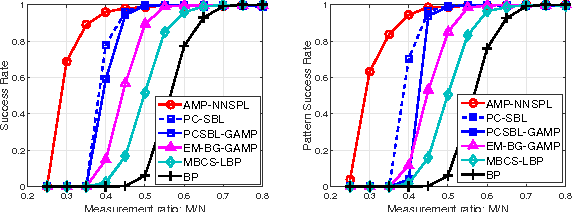
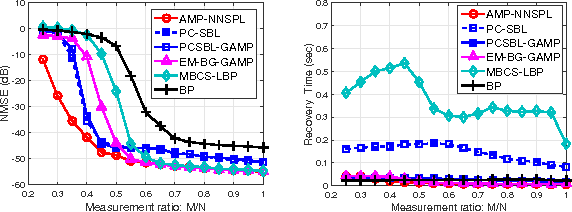
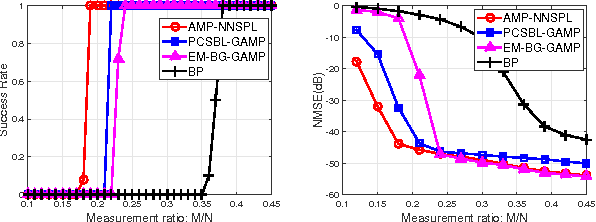

We consider the problem of recovering clustered sparse signals with no prior knowledge of the sparsity pattern. Beyond simple sparsity, signals of interest often exhibits an underlying sparsity pattern which, if leveraged, can improve the reconstruction performance. However, the sparsity pattern is usually unknown a priori. Inspired by the idea of k-nearest neighbor (k-NN) algorithm, we propose an efficient algorithm termed approximate message passing with nearest neighbor sparsity pattern learning (AMP-NNSPL), which learns the sparsity pattern adaptively. AMP-NNSPL specifies a flexible spike and slab prior on the unknown signal and, after each AMP iteration, sets the sparse ratios as the average of the nearest neighbor estimates via expectation maximization (EM). Experimental results on both synthetic and real data demonstrate the superiority of our proposed algorithm both in terms of reconstruction performance and computational complexity.
A Survey of Current Datasets for Vision and Language Research
Aug 19, 2015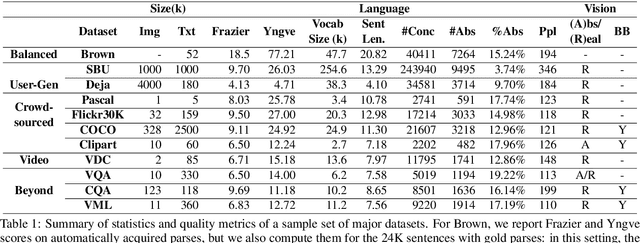
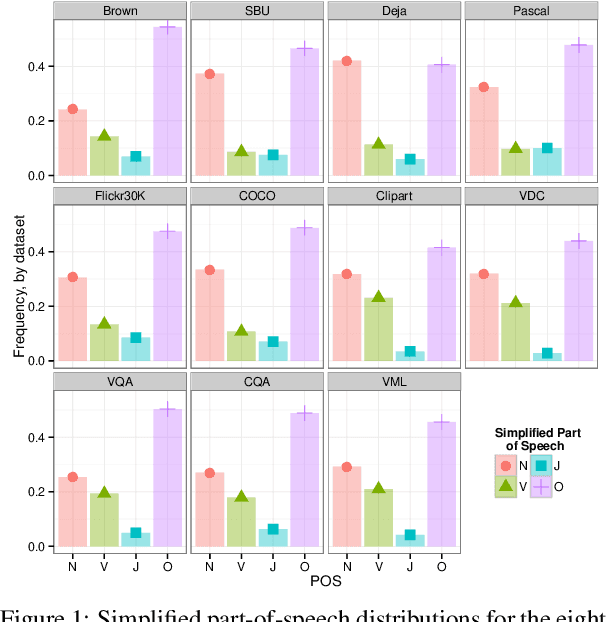
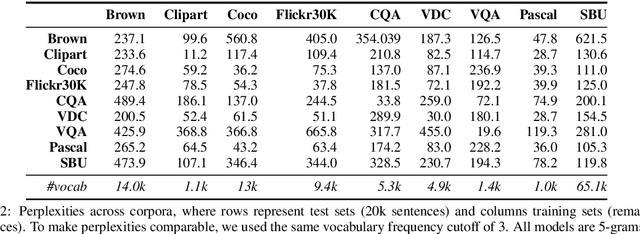
Integrating vision and language has long been a dream in work on artificial intelligence (AI). In the past two years, we have witnessed an explosion of work that brings together vision and language from images to videos and beyond. The available corpora have played a crucial role in advancing this area of research. In this paper, we propose a set of quality metrics for evaluating and analyzing the vision & language datasets and categorize them accordingly. Our analyses show that the most recent datasets have been using more complex language and more abstract concepts, however, there are different strengths and weaknesses in each.