 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Benchmarking Pool-Based Active Learning for Binary Classification
Jun 15, 2023



Active learning is a paradigm that significantly enhances the performance of machine learning models when acquiring labeled data is expensive. While several benchmarks exist for evaluating active learning strategies, their findings exhibit some misalignment. This discrepancy motivates us to develop a transparent and reproducible benchmark for the community. Our efforts result in an open-sourced implementation (https://github.com/ariapoy/active-learning-benchmark) that is reliable and extensible for future research. By conducting thorough re-benchmarking experiments, we have not only rectified misconfigurations in existing benchmark but also shed light on the under-explored issue of model compatibility, which directly causes the observed discrepancy. Resolving the discrepancy reassures that the uncertainty sampling strategy of active learning remains an effective and preferred choice for most datasets. Our experience highlights the importance of dedicating research efforts towards re-benchmarking existing benchmarks to produce more credible results and gain deeper insights.
Understanding and Mitigating Spurious Correlations in Text Classification
May 23, 2023



Recent work has shown that deep learning models are prone to exploit spurious correlations that are present in the training set, yet may not hold true in general. A sentiment classifier may erroneously learn that the token spielberg is always tied to positive movie reviews. Relying on spurious correlations may lead to significant degradation in generalizability and should be avoided. In this paper, we propose a neighborhood analysis framework to explain how exactly language models exploit spurious correlations. Driven by the analysis, we propose a family of regularization methods, NFL (do Not Forget your Language) to prevent the situation. Experiments on two text classification tasks show that NFL brings a significant improvement over standard fine-tuning in terms of robustness without sacrificing in-distribution accuracy.
Enhancing Label Sharing Efficiency in Complementary-Label Learning with Label Augmentation
May 15, 2023Complementary-label Learning (CLL) is a form of weakly supervised learning that trains an ordinary classifier using only complementary labels, which are the classes that certain instances do not belong to. While existing CLL studies typically use novel loss functions or training techniques to solve this problem, few studies focus on how complementary labels collectively provide information to train the ordinary classifier. In this paper, we fill the gap by analyzing the implicit sharing of complementary labels on nearby instances during training. Our analysis reveals that the efficiency of implicit label sharing is closely related to the performance of existing CLL models. Based on this analysis, we propose a novel technique that enhances the sharing efficiency via complementary-label augmentation, which explicitly propagates additional complementary labels to each instance. We carefully design the augmentation process to enrich the data with new and accurate complementary labels, which provide CLL models with fresh and valuable information to enhance the sharing efficiency. We then verify our proposed technique by conducting thorough experiments on both synthetic and real-world datasets. Our results confirm that complementary-label augmentation can systematically improve empirical performance over state-of-the-art CLL models.
CLCIFAR: CIFAR-Derived Benchmark Datasets with Human Annotated Complementary Labels
May 15, 2023



As a weakly-supervised learning paradigm, complementary label learning (CLL) aims to learn a multi-class classifier from only complementary labels, classes to which an instance does not belong. Despite various studies have addressed how to learn from CLL, those methods typically rely on some distributional assumptions on the complementary labels, and are benchmarked only on some synthetic datasets. It remains unclear how the noise or bias arising from the human annotation process would affect those CLL algorithms. To fill the gap, we design a protocol to collect complementary labels annotated by human. Two datasets, CLCIFAR10 and CLCIFAR20, based on CIFAR10 and CIFAR100, respectively, are collected. We analyzed the empirical transition matrices of the collected datasets, and observed that they are noisy and biased. We then performed extensive benchmark experiments on the collected datasets with various CLL algorithms to validate whether the existing algorithms can learn from the real-world complementary datasets. The dataset can be accessed with the following link: https://github.com/ntucllab/complementary_cifar.
SUNY: A Visual Interpretation Framework for Convolutional Neural Networks from a Necessary and Sufficient Perspective
Mar 01, 2023



Researchers have proposed various methods for visually interpreting the Convolutional Neural Network (CNN) via saliency maps, which include Class-Activation-Map (CAM) based approaches as a leading family. However, in terms of the internal design logic, existing CAM-based approaches often overlook the causal perspective that answers the core "why" question to help humans understand the explanation. Additionally, current CNN explanations lack the consideration of both necessity and sufficiency, two complementary sides of a desirable explanation. This paper presents a causality-driven framework, SUNY, designed to rationalize the explanations toward better human understanding. Using the CNN model's input features or internal filters as hypothetical causes, SUNY generates explanations by bi-directional quantifications on both the necessary and sufficient perspectives. Extensive evaluations justify that SUNY not only produces more informative and convincing explanations from the angles of necessity and sufficiency, but also achieves performances competitive to other approaches across different CNN architectures over large-scale datasets, including ILSVRC2012 and CUB-200-2011.
Semi-Supervised Domain Adaptation with Source Label Adaptation
Feb 05, 2023Semi-Supervised Domain Adaptation (SSDA) involves learning to classify unseen target data with a few labeled and lots of unlabeled target data, along with many labeled source data from a related domain. Current SSDA approaches usually aim at aligning the target data to the labeled source data with feature space mapping and pseudo-label assignments. Nevertheless, such a source-oriented model can sometimes align the target data to source data of the wrong classes, degrading the classification performance. This paper presents a novel source-adaptive paradigm that adapts the source data to match the target data. Our key idea is to view the source data as a noisily-labeled version of the ideal target data. Then, we propose an SSDA model that cleans up the label noise dynamically with the help of a robust cleaner component designed from the target perspective. Since the paradigm is very different from the core ideas behind existing SSDA approaches, our proposed model can be easily coupled with them to improve their performance. Empirical results on two state-of-the-art SSDA approaches demonstrate that the proposed model effectively cleans up the noise within the source labels and exhibits superior performance over those approaches across benchmark datasets.
Reduction from Complementary-Label Learning to Probability Estimates
Sep 20, 2022
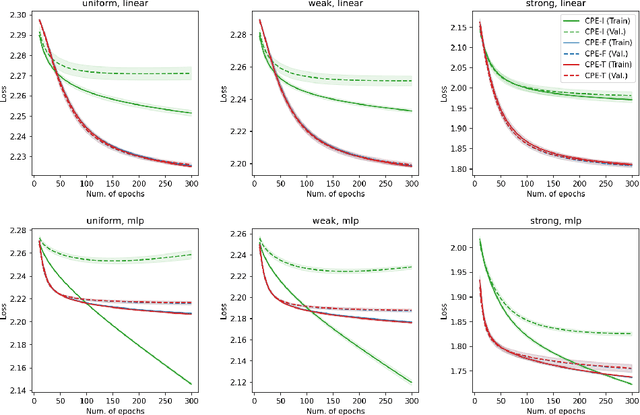

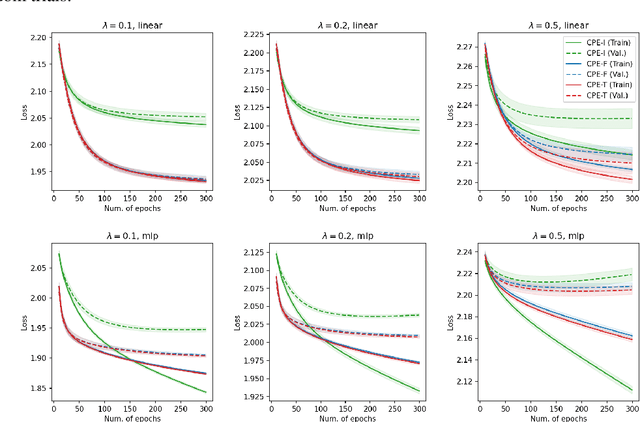
Complementary-Label Learning (CLL) is a weakly-supervised learning problem that aims to learn a multi-class classifier from only complementary labels, which indicate a class to which an instance does not belong. Existing approaches mainly adopt the paradigm of reduction to ordinary classification, which applies specific transformations and surrogate losses to connect CLL back to ordinary classification. Those approaches, however, face several limitations, such as the tendency to overfit or be hooked on deep models. In this paper, we sidestep those limitations with a novel perspective--reduction to probability estimates of complementary classes. We prove that accurate probability estimates of complementary labels lead to good classifiers through a simple decoding step. The proof establishes a reduction framework from CLL to probability estimates. The framework offers explanations of several key CLL approaches as its special cases and allows us to design an improved algorithm that is more robust in noisy environments. The framework also suggests a validation procedure based on the quality of probability estimates, leading to an alternative way to validate models with only complementary labels. The flexible framework opens a wide range of unexplored opportunities in using deep and non-deep models for probability estimates to solve the CLL problem. Empirical experiments further verified the framework's efficacy and robustness in various settings.
Improving Model Compatibility of Generative Adversarial Networks by Boundary Calibration
Nov 03, 2021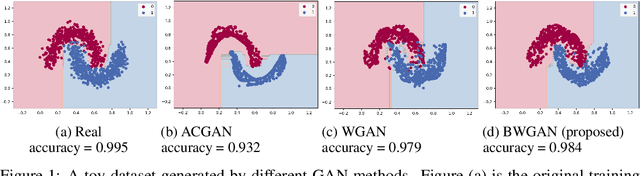
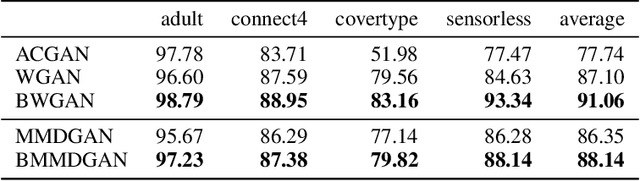
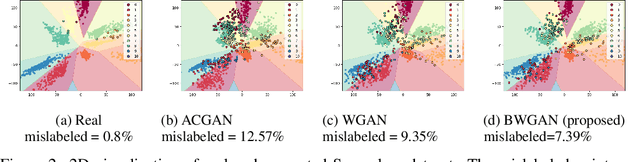
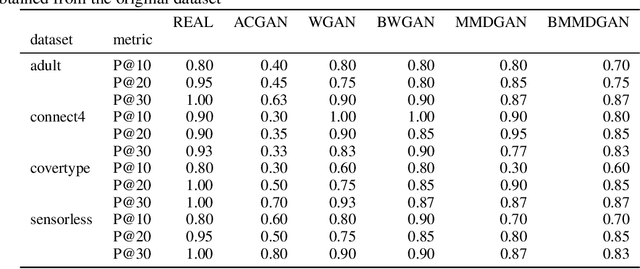
Generative Adversarial Networks (GANs) is a powerful family of models that learn an underlying distribution to generate synthetic data. Many existing studies of GANs focus on improving the realness of the generated image data for visual applications, and few of them concern about improving the quality of the generated data for training other classifiers -- a task known as the model compatibility problem. As a consequence, existing GANs often prefer generating `easier' synthetic data that are far from the boundaries of the classifiers, and refrain from generating near-boundary data, which are known to play an important roles in training the classifiers. To improve GAN in terms of model compatibility, we propose Boundary-Calibration GANs (BCGANs), which leverage the boundary information from a set of pre-trained classifiers using the original data. In particular, we introduce an auxiliary Boundary-Calibration loss (BC-loss) into the generator of GAN to match the statistics between the posterior distributions of original data and generated data with respect to the boundaries of the pre-trained classifiers. The BC-loss is provably unbiased and can be easily coupled with different GAN variants to improve their model compatibility. Experimental results demonstrate that BCGANs not only generate realistic images like original GANs but also achieves superior model compatibility than the original GANs.
A Unified View of cGANs with and without Classifiers
Nov 01, 2021


Conditional Generative Adversarial Networks (cGANs) are implicit generative models which allow to sample from class-conditional distributions. Existing cGANs are based on a wide range of different discriminator designs and training objectives. One popular design in earlier works is to include a classifier during training with the assumption that good classifiers can help eliminate samples generated with wrong classes. Nevertheless, including classifiers in cGANs often comes with a side effect of only generating easy-to-classify samples. Recently, some representative cGANs avoid the shortcoming and reach state-of-the-art performance without having classifiers. Somehow it remains unanswered whether the classifiers can be resurrected to design better cGANs. In this work, we demonstrate that classifiers can be properly leveraged to improve cGANs. We start by using the decomposition of the joint probability distribution to connect the goals of cGANs and classification as a unified framework. The framework, along with a classic energy model to parameterize distributions, justifies the use of classifiers for cGANs in a principled manner. It explains several popular cGAN variants, such as ACGAN, ProjGAN, and ContraGAN, as special cases with different levels of approximations, which provides a unified view and brings new insights to understanding cGANs. Experimental results demonstrate that the design inspired by the proposed framework outperforms state-of-the-art cGANs on multiple benchmark datasets, especially on the most challenging ImageNet. The code is available at https://github.com/sian-chen/PyTorch-ECGAN.
Active Refinement for Multi-Label Learning: A Pseudo-Label Approach
Sep 29, 2021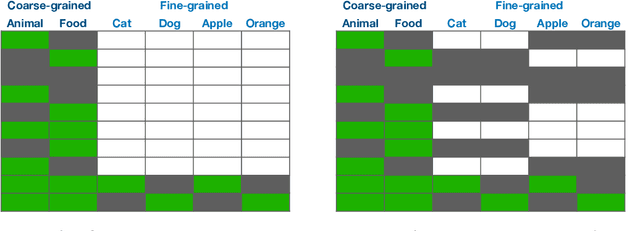
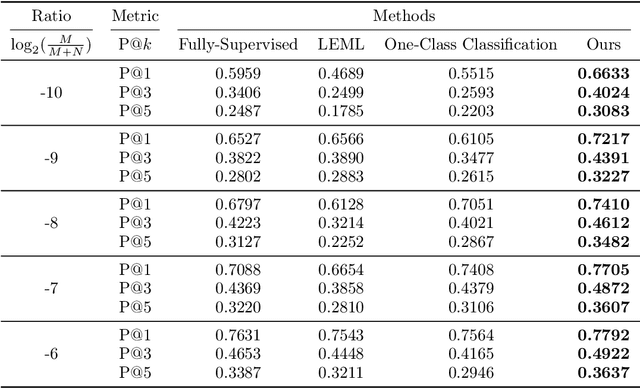
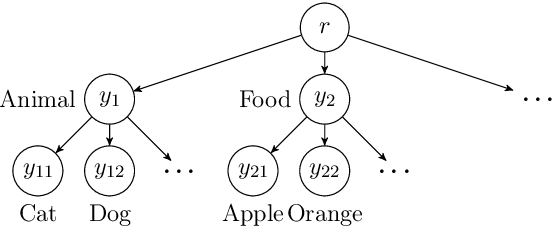
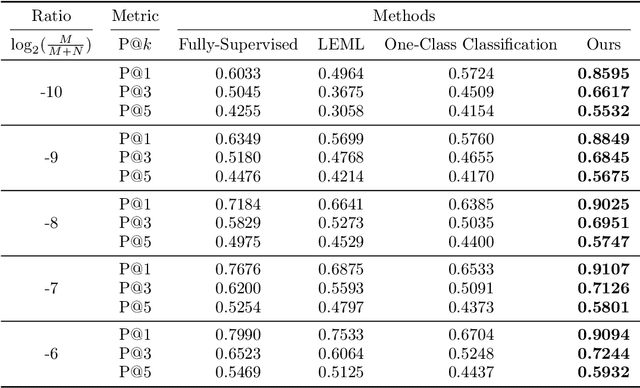
The goal of multi-label learning (MLL) is to associate a given instance with its relevant labels from a set of concepts. Previous works of MLL mainly focused on the setting where the concept set is assumed to be fixed, while many real-world applications require introducing new concepts into the set to meet new demands. One common need is to refine the original coarse concepts and split them into finer-grained ones, where the refinement process typically begins with limited labeled data for the finer-grained concepts. To address the need, we formalize the problem into a special weakly supervised MLL problem to not only learn the fine-grained concepts efficiently but also allow interactive queries to strategically collect more informative annotations to further improve the classifier. The key idea within our approach is to learn to assign pseudo-labels to the unlabeled entries, and in turn leverage the pseudo-labels to train the underlying classifier and to inform a better query strategy. Experimental results demonstrate that our pseudo-label approach is able to accurately recover the missing ground truth, boosting the prediction performance significantly over the baseline methods and facilitating a competitive active learning strategy.