 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn quantum backpropagation, information reuse, and cheating measurement collapse
May 22, 2023

The success of modern deep learning hinges on the ability to train neural networks at scale. Through clever reuse of intermediate information, backpropagation facilitates training through gradient computation at a total cost roughly proportional to running the function, rather than incurring an additional factor proportional to the number of parameters - which can now be in the trillions. Naively, one expects that quantum measurement collapse entirely rules out the reuse of quantum information as in backpropagation. But recent developments in shadow tomography, which assumes access to multiple copies of a quantum state, have challenged that notion. Here, we investigate whether parameterized quantum models can train as efficiently as classical neural networks. We show that achieving backpropagation scaling is impossible without access to multiple copies of a state. With this added ability, we introduce an algorithm with foundations in shadow tomography that matches backpropagation scaling in quantum resources while reducing classical auxiliary computational costs to open problems in shadow tomography. These results highlight the nuance of reusing quantum information for practical purposes and clarify the unique difficulties in training large quantum models, which could alter the course of quantum machine learning.
The power and limitations of learning quantum dynamics incoherently
Mar 22, 2023



Quantum process learning is emerging as an important tool to study quantum systems. While studied extensively in coherent frameworks, where the target and model system can share quantum information, less attention has been paid to whether the dynamics of quantum systems can be learned without the system and target directly interacting. Such incoherent frameworks are practically appealing since they open up methods of transpiling quantum processes between the different physical platforms without the need for technically challenging hybrid entanglement schemes. Here we provide bounds on the sample complexity of learning unitary processes incoherently by analyzing the number of measurements that are required to emulate well-established coherent learning strategies. We prove that if arbitrary measurements are allowed, then any efficiently representable unitary can be efficiently learned within the incoherent framework; however, when restricted to shallow-depth measurements only low-entangling unitaries can be learned. We demonstrate our incoherent learning algorithm for low entangling unitaries by successfully learning a 16-qubit unitary on \texttt{ibmq\_kolkata}, and further demonstrate the scalabilty of our proposed algorithm through extensive numerical experiments.
Challenges and Opportunities in Quantum Machine Learning
Mar 16, 2023At the intersection of machine learning and quantum computing, Quantum Machine Learning (QML) has the potential of accelerating data analysis, especially for quantum data, with applications for quantum materials, biochemistry, and high-energy physics. Nevertheless, challenges remain regarding the trainability of QML models. Here we review current methods and applications for QML. We highlight differences between quantum and classical machine learning, with a focus on quantum neural networks and quantum deep learning. Finally, we discuss opportunities for quantum advantage with QML.
* 14 pages, 5 figures
Improved machine learning algorithm for predicting ground state properties
Jan 30, 2023Finding the ground state of a quantum many-body system is a fundamental problem in quantum physics. In this work, we give a classical machine learning (ML) algorithm for predicting ground state properties with an inductive bias encoding geometric locality. The proposed ML model can efficiently predict ground state properties of an $n$-qubit gapped local Hamiltonian after learning from only $\mathcal{O}(\log(n))$ data about other Hamiltonians in the same quantum phase of matter. This improves substantially upon previous results that require $\mathcal{O}(n^c)$ data for a large constant $c$. Furthermore, the training and prediction time of the proposed ML model scale as $\mathcal{O}(n \log n)$ in the number of qubits $n$. Numerical experiments on physical systems with up to 45 qubits confirm the favorable scaling in predicting ground state properties using a small training dataset.
Hardware-efficient learning of quantum many-body states
Dec 12, 2022Efficient characterization of highly entangled multi-particle systems is an outstanding challenge in quantum science. Recent developments have shown that a modest number of randomized measurements suffices to learn many properties of a quantum many-body system. However, implementing such measurements requires complete control over individual particles, which is unavailable in many experimental platforms. In this work, we present rigorous and efficient algorithms for learning quantum many-body states in systems with any degree of control over individual particles, including when every particle is subject to the same global field and no additional ancilla particles are available. We numerically demonstrate the effectiveness of our algorithms for estimating energy densities in a U(1) lattice gauge theory and classifying topological order using very limited measurement capabilities.
Learning to predict arbitrary quantum processes
Oct 27, 2022We present an efficient machine learning (ML) algorithm for predicting any unknown quantum process $\mathcal{E}$ over $n$ qubits. For a wide range of distributions $\mathcal{D}$ on arbitrary $n$-qubit states, we show that this ML algorithm can learn to predict any local property of the output from the unknown process $\mathcal{E}$, with a small average error over input states drawn from $\mathcal{D}$. The ML algorithm is computationally efficient even when the unknown process is a quantum circuit with exponentially many gates. Our algorithm combines efficient procedures for learning properties of an unknown state and for learning a low-degree approximation to an unknown observable. The analysis hinges on proving new norm inequalities, including a quantum analogue of the classical Bohnenblust-Hille inequality, which we derive by giving an improved algorithm for optimizing local Hamiltonians. Overall, our results highlight the potential for ML models to predict the output of complex quantum dynamics much faster than the time needed to run the process itself.
The Complexity of NISQ
Oct 13, 2022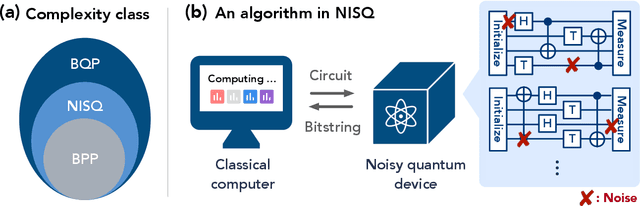
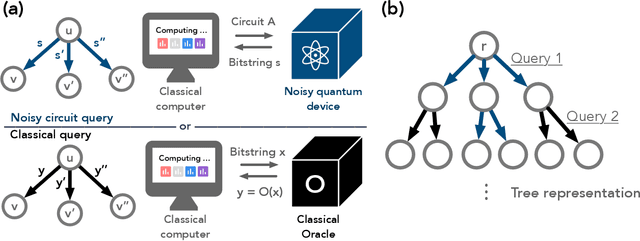
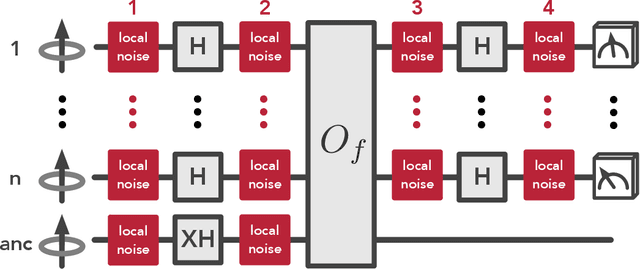
The recent proliferation of NISQ devices has made it imperative to understand their computational power. In this work, we define and study the complexity class $\textsf{NISQ} $, which is intended to encapsulate problems that can be efficiently solved by a classical computer with access to a NISQ device. To model existing devices, we assume the device can (1) noisily initialize all qubits, (2) apply many noisy quantum gates, and (3) perform a noisy measurement on all qubits. We first give evidence that $\textsf{BPP}\subsetneq \textsf{NISQ}\subsetneq \textsf{BQP}$, by demonstrating super-polynomial oracle separations among the three classes, based on modifications of Simon's problem. We then consider the power of $\textsf{NISQ}$ for three well-studied problems. For unstructured search, we prove that $\textsf{NISQ}$ cannot achieve a Grover-like quadratic speedup over $\textsf{BPP}$. For the Bernstein-Vazirani problem, we show that $\textsf{NISQ}$ only needs a number of queries logarithmic in what is required for $\textsf{BPP}$. Finally, for a quantum state learning problem, we prove that $\textsf{NISQ}$ is exponentially weaker than classical computation with access to noiseless constant-depth quantum circuits.
Learning many-body Hamiltonians with Heisenberg-limited scaling
Oct 06, 2022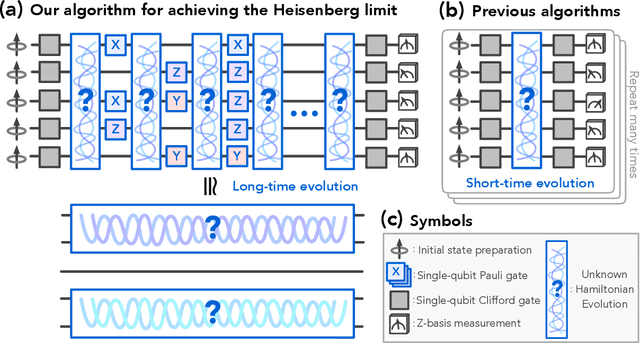
Learning a many-body Hamiltonian from its dynamics is a fundamental problem in physics. In this work, we propose the first algorithm to achieve the Heisenberg limit for learning an interacting $N$-qubit local Hamiltonian. After a total evolution time of $\mathcal{O}(\epsilon^{-1})$, the proposed algorithm can efficiently estimate any parameter in the $N$-qubit Hamiltonian to $\epsilon$-error with high probability. The proposed algorithm is robust against state preparation and measurement error, does not require eigenstates or thermal states, and only uses $\mathrm{polylog}(\epsilon^{-1})$ experiments. In contrast, the best previous algorithms, such as recent works using gradient-based optimization or polynomial interpolation, require a total evolution time of $\mathcal{O}(\epsilon^{-2})$ and $\mathcal{O}(\epsilon^{-2})$ experiments. Our algorithm uses ideas from quantum simulation to decouple the unknown $N$-qubit Hamiltonian $H$ into noninteracting patches, and learns $H$ using a quantum-enhanced divide-and-conquer approach. We prove a matching lower bound to establish the asymptotic optimality of our algorithm.
Foundations for learning from noisy quantum experiments
Apr 28, 2022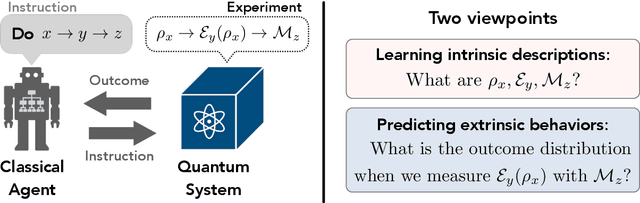
Understanding what can be learned from experiments is central to scientific progress. In this work, we use a learning-theoretic perspective to study the task of learning physical operations in a quantum machine when all operations (state preparation, dynamics, and measurement) are a priori unknown. We prove that, without any prior knowledge, if one can explore the full quantum state space by composing the operations, then every operation can be learned. When one cannot explore the full state space but all operations are approximately known and noise in Clifford gates is gate-independent, we find an efficient algorithm for learning all operations up to a single unlearnable parameter characterizing the fidelity of the initial state. For learning a noise channel on Clifford gates to a fixed accuracy, our algorithm uses quadratically fewer experiments than previously known protocols. Under more general conditions, the true description of the noise can be unlearnable; for example, we prove that no benchmarking protocol can learn gate-dependent Pauli noise on Clifford+T gates even under perfect state preparation and measurement. Despite not being able to learn the noise, we show that a noisy quantum computer that performs entangled measurements on multiple copies of an unknown state can yield a large advantage in learning properties of the state compared to a noiseless device that measures individual copies and then processes the measurement data using a classical computer. Concretely, we prove that noisy quantum computers with two-qubit gate error rate $\epsilon$ can achieve a learning task using $N$ copies of the state, while $N^{\Omega(1/\epsilon)}$ copies are required classically.
Dynamical simulation via quantum machine learning with provable generalization
Apr 21, 2022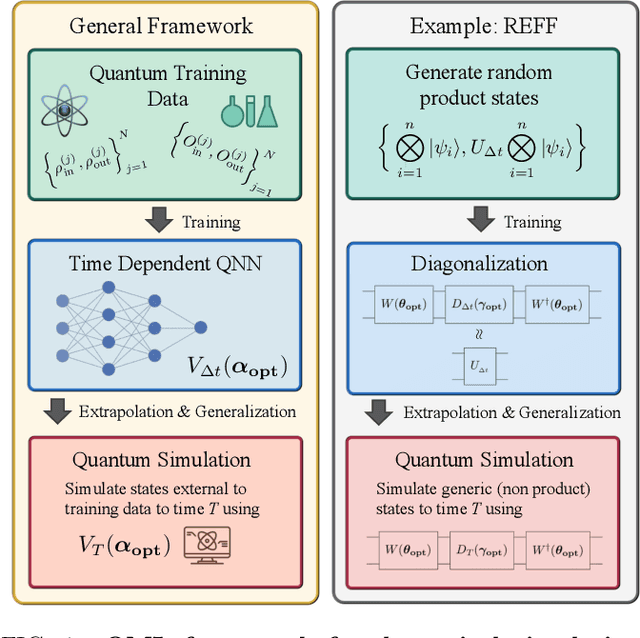
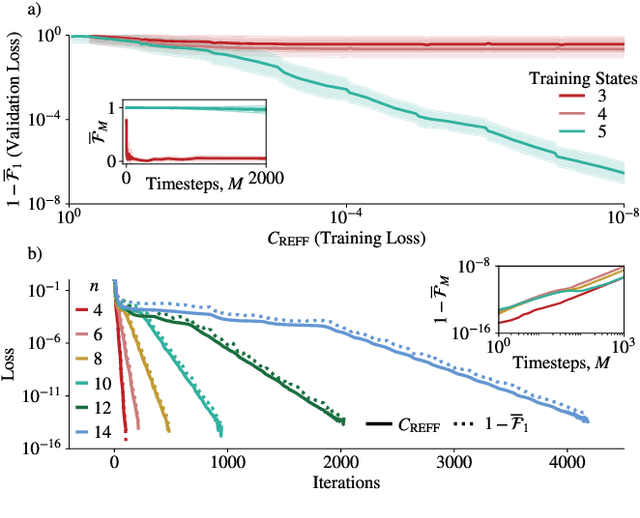
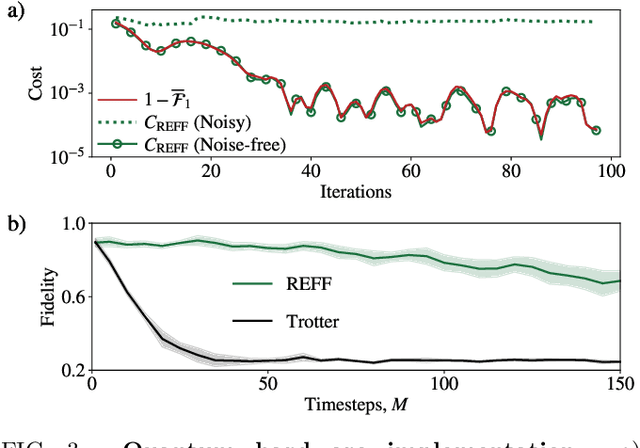
Much attention has been paid to dynamical simulation and quantum machine learning (QML) independently as applications for quantum advantage, while the possibility of using QML to enhance dynamical simulations has not been thoroughly investigated. Here we develop a framework for using QML methods to simulate quantum dynamics on near-term quantum hardware. We use generalization bounds, which bound the error a machine learning model makes on unseen data, to rigorously analyze the training data requirements of an algorithm within this framework. This provides a guarantee that our algorithm is resource-efficient, both in terms of qubit and data requirements. Our numerics exhibit efficient scaling with problem size, and we simulate 20 times longer than Trotterization on IBMQ-Bogota.