 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextSR: Diffusion Super-Resolution with Multilingual OCR Guidance
May 29, 2025While recent advancements in Image Super-Resolution (SR) using diffusion models have shown promise in improving overall image quality, their application to scene text images has revealed limitations. These models often struggle with accurate text region localization and fail to effectively model image and multilingual character-to-shape priors. This leads to inconsistencies, the generation of hallucinated textures, and a decrease in the perceived quality of the super-resolved text. To address these issues, we introduce TextSR, a multimodal diffusion model specifically designed for Multilingual Scene Text Image Super-Resolution. TextSR leverages a text detector to pinpoint text regions within an image and then employs Optical Character Recognition (OCR) to extract multilingual text from these areas. The extracted text characters are then transformed into visual shapes using a UTF-8 based text encoder and cross-attention. Recognizing that OCR may sometimes produce inaccurate results in real-world scenarios, we have developed two innovative methods to enhance the robustness of our model. By integrating text character priors with the low-resolution text images, our model effectively guides the super-resolution process, enhancing fine details within the text and improving overall legibility. The superior performance of our model on both the TextZoom and TextVQA datasets sets a new benchmark for STISR, underscoring the efficacy of our approach.
Better Compression with Deep Pre-Editing
Feb 01, 2020
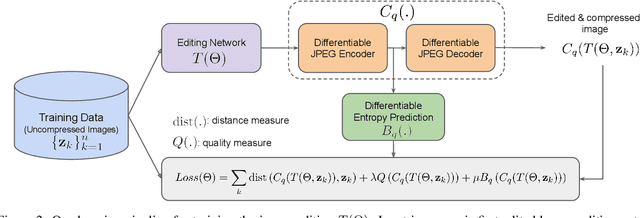
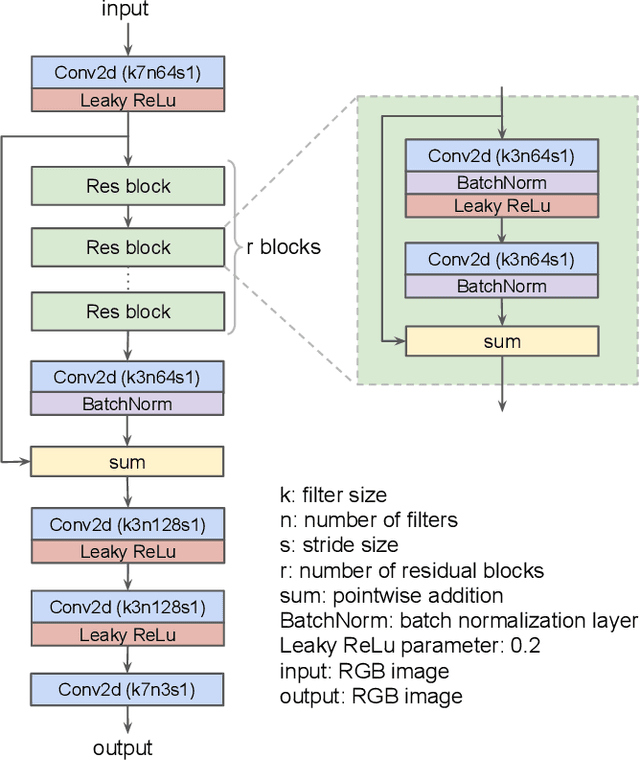
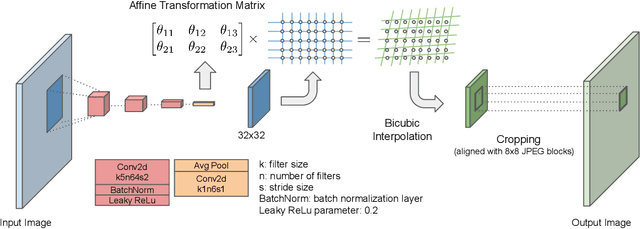
Could we compress images via standard codecs while avoiding artifacts? The answer is obvious -- this is doable as long as the bit budget is generous enough. What if the allocated bit-rate for compression is insufficient? Then unfortunately, artifacts are a fact of life. Many attempts were made over the years to fight this phenomenon, with various degrees of success. In this work we aim to break the unholy connection between bit-rate and image quality, and propose a way to circumvent compression artifacts by pre-editing the incoming image and modifying its content to fit the given bits. We design this editing operation as a learned convolutional neural network, and formulate an optimization problem for its training. Our loss takes into account a proximity between the original image and the edited one, a bit-budget penalty over the proposed image, and a no-reference image quality measure for forcing the outcome to be visually pleasing. The proposed approach is demonstrated on the popular JPEG compression, showing savings in bits and/or improvements in visual quality, obtained with intricate editing effects.