 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Visual Quality of Image Synthesis by A Token-based Generator with Transformers
Nov 05, 2021



We present a new perspective of achieving image synthesis by viewing this task as a visual token generation problem. Different from existing paradigms that directly synthesize a full image from a single input (e.g., a latent code), the new formulation enables a flexible local manipulation for different image regions, which makes it possible to learn content-aware and fine-grained style control for image synthesis. Specifically, it takes as input a sequence of latent tokens to predict the visual tokens for synthesizing an image. Under this perspective, we propose a token-based generator (i.e.,TokenGAN). Particularly, the TokenGAN inputs two semantically different visual tokens, i.e., the learned constant content tokens and the style tokens from the latent space. Given a sequence of style tokens, the TokenGAN is able to control the image synthesis by assigning the styles to the content tokens by attention mechanism with a Transformer. We conduct extensive experiments and show that the proposed TokenGAN has achieved state-of-the-art results on several widely-used image synthesis benchmarks, including FFHQ and LSUN CHURCH with different resolutions. In particular, the generator is able to synthesize high-fidelity images with 1024x1024 size, dispensing with convolutions entirely.
Reference-based Defect Detection Network
Aug 10, 2021
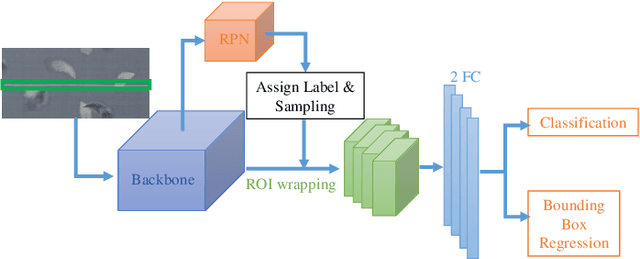

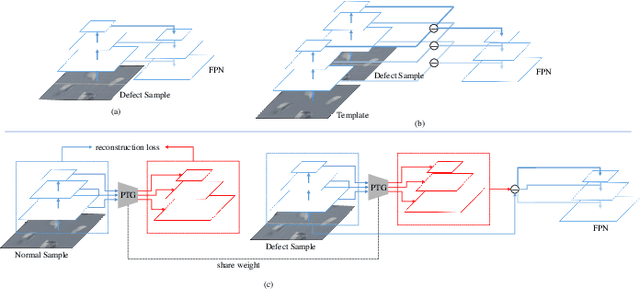
The defect detection task can be regarded as a realistic scenario of object detection in the computer vision field and it is widely used in the industrial field. Directly applying vanilla object detector to defect detection task can achieve promising results, while there still exists challenging issues that have not been solved. The first issue is the texture shift which means a trained defect detector model will be easily affected by unseen texture, and the second issue is partial visual confusion which indicates that a partial defect box is visually similar with a complete box. To tackle these two problems, we propose a Reference-based Defect Detection Network (RDDN). Specifically, we introduce template reference and context reference to against those two problems, respectively. Template reference can reduce the texture shift from image, feature or region levels, and encourage the detectors to focus more on the defective area as a result. We can use either well-aligned template images or the outputs of a pseudo template generator as template references in this work, and they are jointly trained with detectors by the supervision of normal samples. To solve the partial visual confusion issue, we propose to leverage the carried context information of context reference, which is the concentric bigger box of each region proposal, to perform more accurate region classification and regression. Experiments on two defect detection datasets demonstrate the effectiveness of our proposed approach.
A Low Rank Promoting Prior for Unsupervised Contrastive Learning
Aug 05, 2021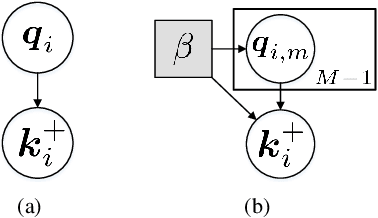
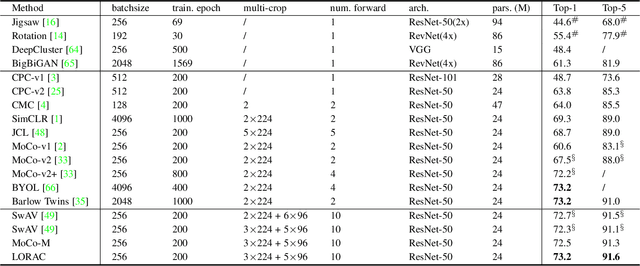
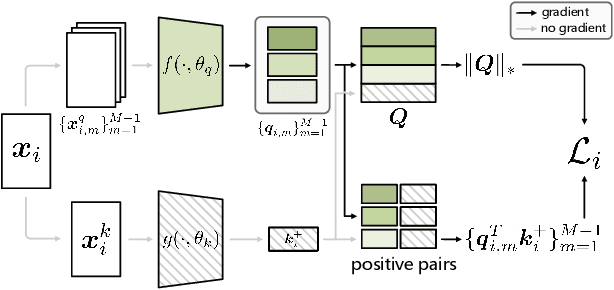

Unsupervised learning is just at a tipping point where it could really take off. Among these approaches, contrastive learning has seen tremendous progress and led to state-of-the-art performance. In this paper, we construct a novel probabilistic graphical model that effectively incorporates the low rank promoting prior into the framework of contrastive learning, referred to as LORAC. In contrast to the existing conventional self-supervised approaches that only considers independent learning, our hypothesis explicitly requires that all the samples belonging to the same instance class lie on the same subspace with small dimension. This heuristic poses particular joint learning constraints to reduce the degree of freedom of the problem during the search of the optimal network parameterization. Most importantly, we argue that the low rank prior employed here is not unique, and many different priors can be invoked in a similar probabilistic way, corresponding to different hypotheses about underlying truth behind the contrastive features. Empirical evidences show that the proposed algorithm clearly surpasses the state-of-the-art approaches on multiple benchmarks, including image classification, object detection, instance segmentation and keypoint detection.
Rethinking and Improving Relative Position Encoding for Vision Transformer
Jul 29, 2021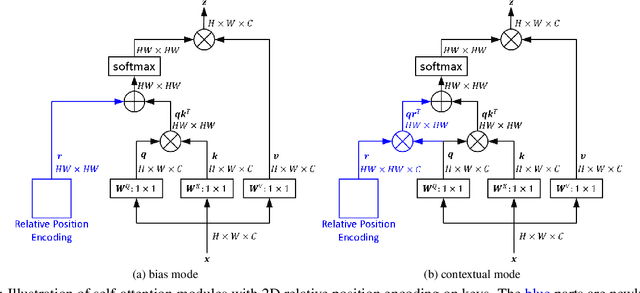
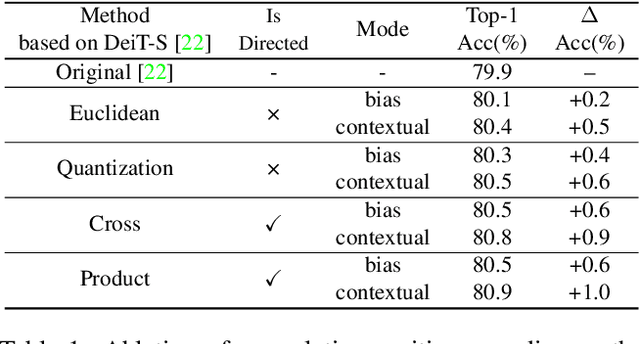
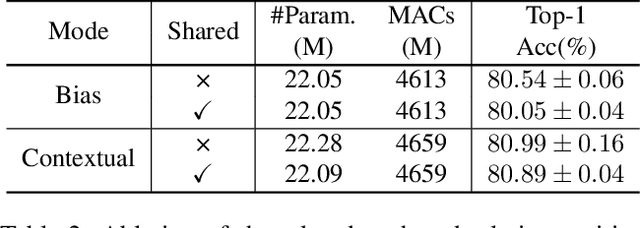
Relative position encoding (RPE) is important for transformer to capture sequence ordering of input tokens. General efficacy has been proven in natural language processing. However, in computer vision, its efficacy is not well studied and even remains controversial, e.g., whether relative position encoding can work equally well as absolute position? In order to clarify this, we first review existing relative position encoding methods and analyze their pros and cons when applied in vision transformers. We then propose new relative position encoding methods dedicated to 2D images, called image RPE (iRPE). Our methods consider directional relative distance modeling as well as the interactions between queries and relative position embeddings in self-attention mechanism. The proposed iRPE methods are simple and lightweight. They can be easily plugged into transformer blocks. Experiments demonstrate that solely due to the proposed encoding methods, DeiT and DETR obtain up to 1.5% (top-1 Acc) and 1.3% (mAP) stable improvements over their original versions on ImageNet and COCO respectively, without tuning any extra hyperparameters such as learning rate and weight decay. Our ablation and analysis also yield interesting findings, some of which run counter to previous understanding. Code and models are open-sourced at https://github.com/microsoft/Cream/tree/main/iRPE.
3D Human Body Reshaping with Anthropometric Modeling
Apr 05, 2021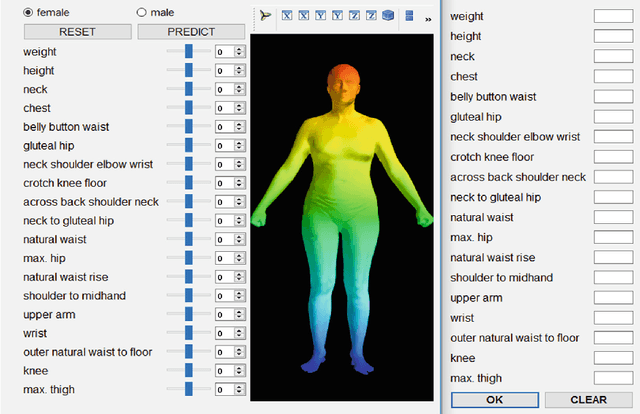
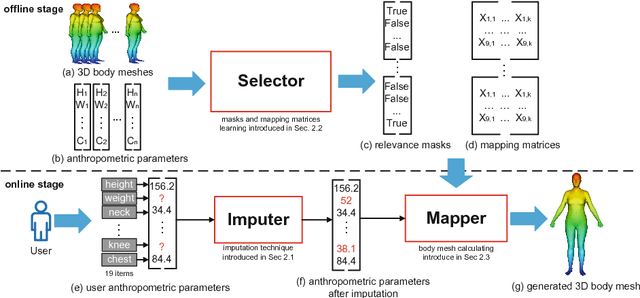
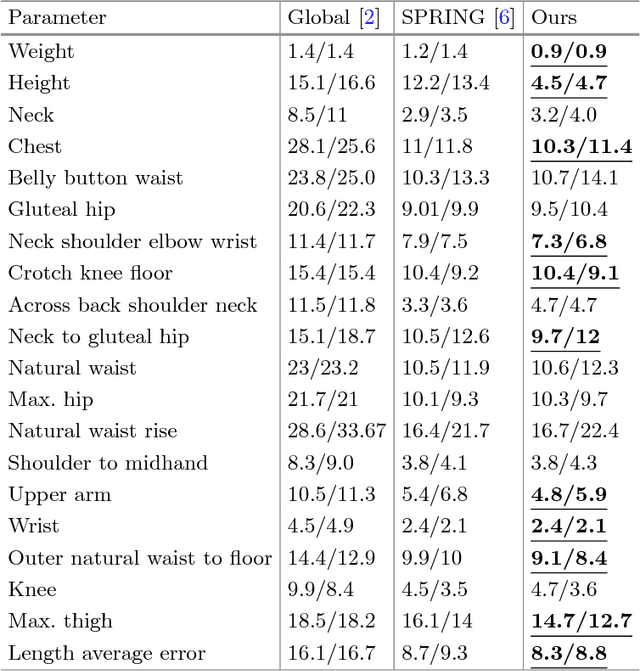
Reshaping accurate and realistic 3D human bodies from anthropometric parameters (e.g., height, chest size, etc.) poses a fundamental challenge for person identification, online shopping and virtual reality. Existing approaches for creating such 3D shapes often suffer from complex measurement by range cameras or high-end scanners, which either involve heavy expense cost or result in low quality. However, these high-quality equipments limit existing approaches in real applications, because the equipments are not easily accessible for common users. In this paper, we have designed a 3D human body reshaping system by proposing a novel feature-selection-based local mapping technique, which enables automatic anthropometric parameter modeling for each body facet. Note that the proposed approach can leverage limited anthropometric parameters (i.e., 3-5 measurements) as input, which avoids complex measurement, and thus better user-friendly experience can be achieved in real scenarios. Specifically, the proposed reshaping model consists of three steps. First, we calculate full-body anthropometric parameters from limited user inputs by imputation technique, and thus essential anthropometric parameters for 3D body reshaping can be obtained. Second, we select the most relevant anthropometric parameters for each facet by adopting relevance masks, which are learned offline by the proposed local mapping technique. Third, we generate the 3D body meshes by mapping matrices, which are learned by linear regression from the selected parameters to mesh-based body representation. We conduct experiments by anthropomorphic evaluation and a user study from 68 volunteers. Experiments show the superior results of the proposed system in terms of mean reconstruction error against the state-of-the-art approaches.
* ICIMCS 2017(oral). The final publication is available at Springer via https://doi.org/10.1007/978-981-10-8530-7_10
Aggregated Contextual Transformations for High-Resolution Image Inpainting
Apr 03, 2021
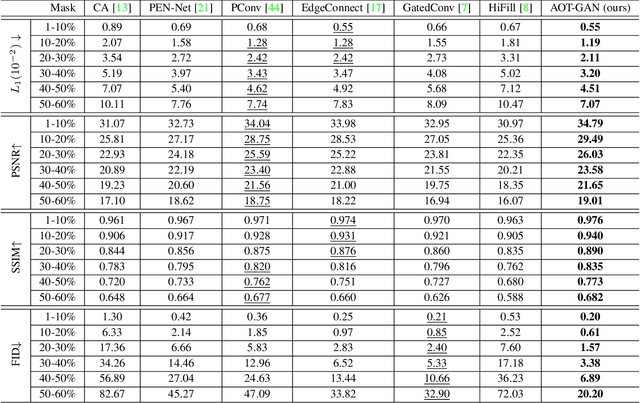
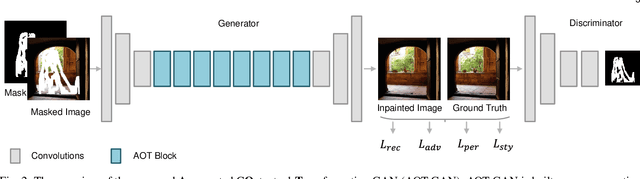

State-of-the-art image inpainting approaches can suffer from generating distorted structures and blurry textures in high-resolution images (e.g., 512x512). The challenges mainly drive from (1) image content reasoning from distant contexts, and (2) fine-grained texture synthesis for a large missing region. To overcome these two challenges, we propose an enhanced GAN-based model, named Aggregated COntextual-Transformation GAN (AOT-GAN), for high-resolution image inpainting. Specifically, to enhance context reasoning, we construct the generator of AOT-GAN by stacking multiple layers of a proposed AOT block. The AOT blocks aggregate contextual transformations from various receptive fields, allowing to capture both informative distant image contexts and rich patterns of interest for context reasoning. For improving texture synthesis, we enhance the discriminator of AOT-GAN by training it with a tailored mask-prediction task. Such a training objective forces the discriminator to distinguish the detailed appearances of real and synthesized patches, and in turn, facilitates the generator to synthesize clear textures. Extensive comparisons on Places2, the most challenging benchmark with 1.8 million high-resolution images of 365 complex scenes, show that our model outperforms the state-of-the-art by a significant margin in terms of FID with 38.60% relative improvement. A user study including more than 30 subjects further validates the superiority of AOT-GAN. We further evaluate the proposed AOT-GAN in practical applications, e.g., logo removal, face editing, and object removal. Results show that our model achieves promising completions in the real world. We release code and models in https://github.com/researchmm/AOT-GAN-for-Inpainting.
Learning Joint Spatial-Temporal Transformations for Video Inpainting
Jul 20, 2020
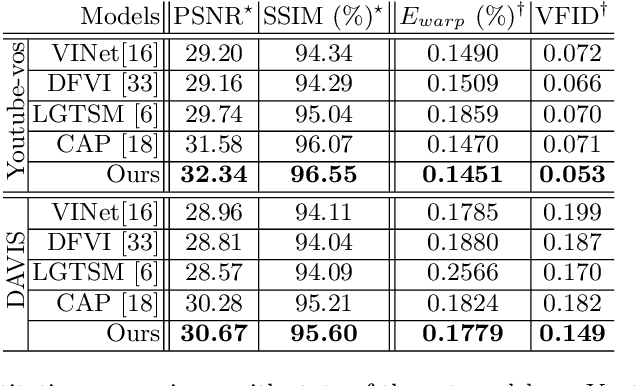
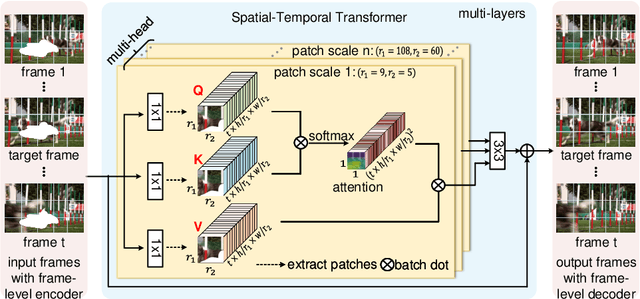
High-quality video inpainting that completes missing regions in video frames is a promising yet challenging task. State-of-the-art approaches adopt attention models to complete a frame by searching missing contents from reference frames, and further complete whole videos frame by frame. However, these approaches can suffer from inconsistent attention results along spatial and temporal dimensions, which often leads to blurriness and temporal artifacts in videos. In this paper, we propose to learn a joint Spatial-Temporal Transformer Network (STTN) for video inpainting. Specifically, we simultaneously fill missing regions in all input frames by self-attention, and propose to optimize STTN by a spatial-temporal adversarial loss. To show the superiority of the proposed model, we conduct both quantitative and qualitative evaluations by using standard stationary masks and more realistic moving object masks. Demo videos are available at https://github.com/researchmm/STTN.
Mining Domain Knowledge: Improved Framework towards Automatically Standardizing Anatomical Structure Nomenclature in Radiotherapy
Dec 04, 2019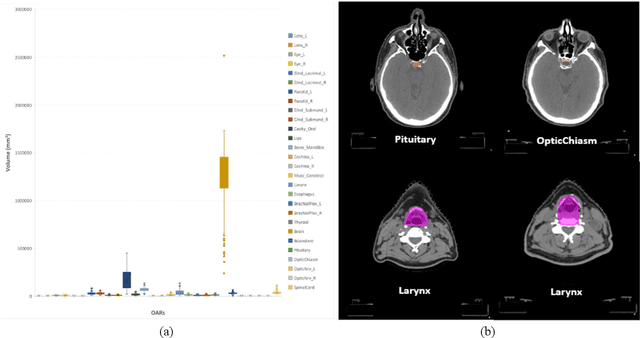
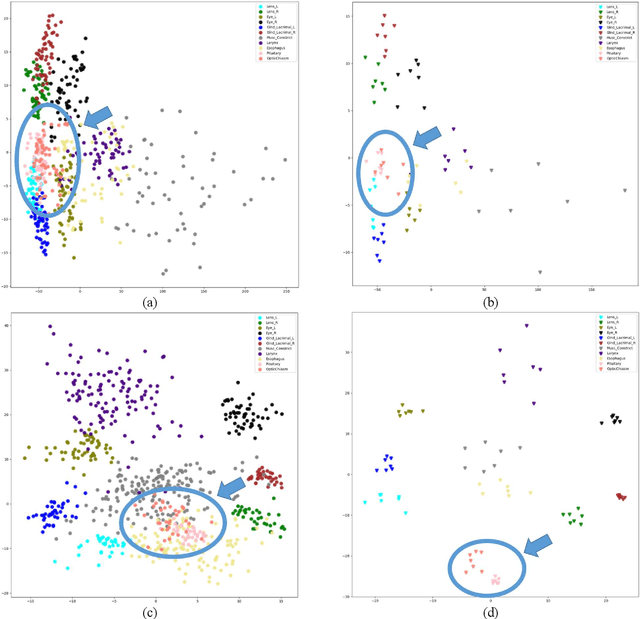
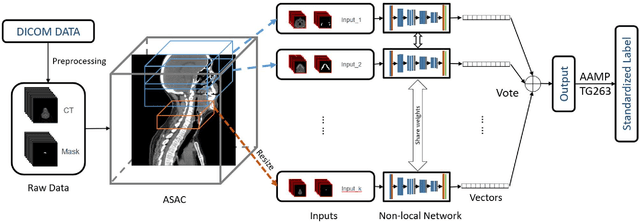
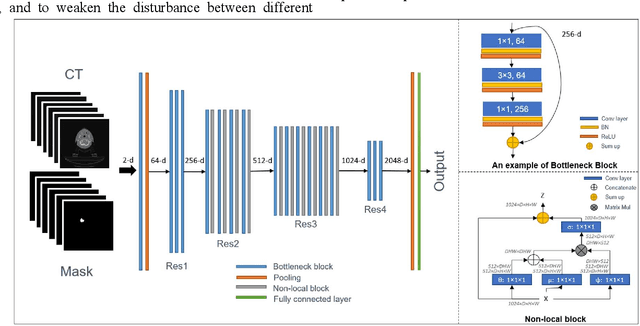
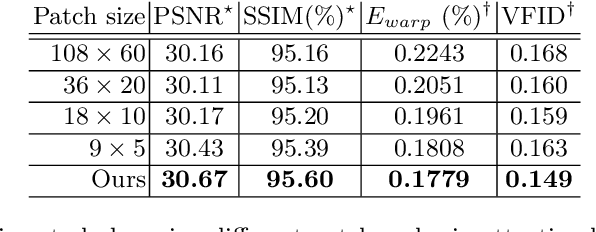
Automatically standardizing nomenclature for anatomical structures in radiotherapy (RT) clinical data is an unmet urgent need in the era of big data and artificial intelligence. Existing methods either can hardly handle cross-institutional datasets or suffer from heavy imbalance and poor-quality delineation in clinical RT datasets. To solve these problems, we propose an automated structure nomenclature standardization framework, 3DNNV, which consists of an improved data processing strategy (ASAC/Voting) and an optimized feature extraction module to simulate clinicians' domain knowledge and recognition mechanisms to identify heavily imbalanced small-volume organs at risk (OARs) better than other methods. We used partial data from an open-source head-and-neck cancer dataset (HN_PETCT) to train the model, then tested the model on three cross-institutional datasets to demonstrate its generalizability. 3DNNV outperformed the baseline model (ResNet50), achieving a significantly higher average true positive rate (TPR) on the three test datasets (+8.27%, +2.39%, +5.53%). More importantly, the 3DNNV outperformed the baseline, 28.63% to 91.17%, on the F1 score of a small-volume OAR with only 9 training samples, when tested on the HN_UTSW dataset. The developed framework can be used to help standardizing structure nomenclature to facilitate data-driven clinical research in cancer radiotherapy.
Endowing Deep 3D Models with Rotation Invariance Based on Principal Component Analysis
Oct 20, 2019
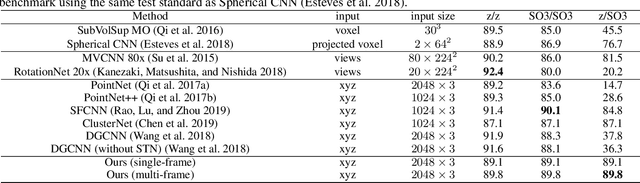

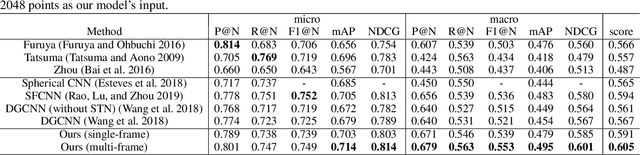
In this paper, we propose a simple yet effective method to endow deep 3D models with rotation invariance by expressing the coordinates in an intrinsic frame determined by the object shape itself. Key to our approach is to find such an intrinsic frame which should be unique to the identical object shape and consistent across different instances of the same category, e.g. the frame axes of desks should be all roughly along the edges. Interestingly, the principal component analysis exactly provides an effective way to define such a frame, i.e. setting the principal components as the frame axes. As the principal components have direction ambiguity caused by the sign-ambiguity of eigenvector computation, there exist several intrinsic frames for each object. In order to achieve absolute rotation invariance for a deep model, we adopt the coordinates expressed in all intrinsic frames as inputs to obtain multiple output features, which will be further aggregated as a final feature via a self-attention module. Our method is theoretically rotation-invariant and can be flexibly embedded into the current network architectures. Comprehensive experiments demonstrate that our approach can achieve near state-of-the-art performance on rotation-augmented dataset for ModelNet40 classification and outperform other models on SHREC'17 perturbed retrieval task.
WSOD^2: Learning Bottom-up and Top-down Objectness Distillation for Weakly-supervised Object Detection
Sep 11, 2019

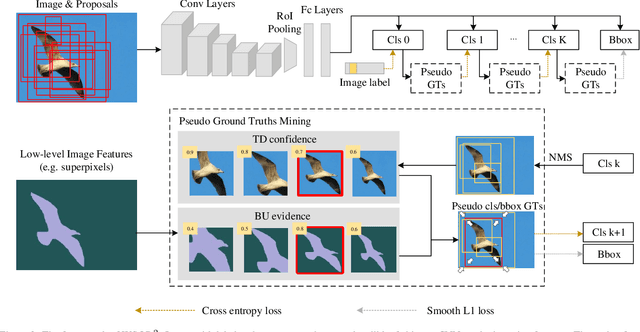
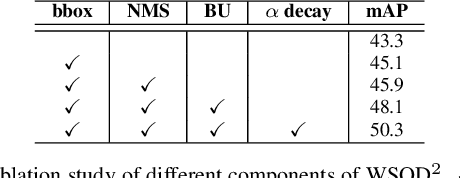
We study on weakly-supervised object detection (WSOD) which plays a vital role in relieving human involvement from object-level annotations. Predominant works integrate region proposal mechanisms with convolutional neural networks (CNN). Although CNN is proficient in extracting discriminative local features, grand challenges still exist to measure the likelihood of a bounding box containing a complete object (i.e., "objectness"). In this paper, we propose a novel WSOD framework with Objectness Distillation (i.e., WSOD^2) by designing a tailored training mechanism for weakly-supervised object detection. Multiple regression targets are specifically determined by jointly considering bottom-up (BU) and top-down (TD) objectness from low-level measurement and CNN confidences with an adaptive linear combination. As bounding box regression can facilitate a region proposal learning to approach its regression target with high objectness during training, deep objectness representation learned from bottom-up evidences can be gradually distilled into CNN by optimization. We explore different adaptive training curves for BU/TD objectness, and show that the proposed WSOD^2 can achieve state-of-the-art results.