 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastMVAE2: On improving and accelerating the fast variational autoencoder-based source separation algorithm for determined mixtures
Sep 28, 2021
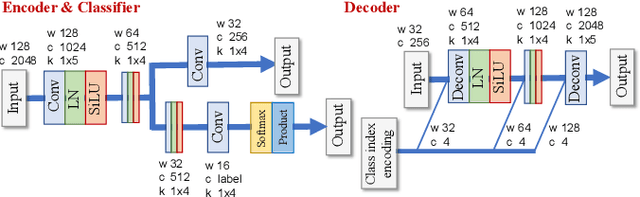
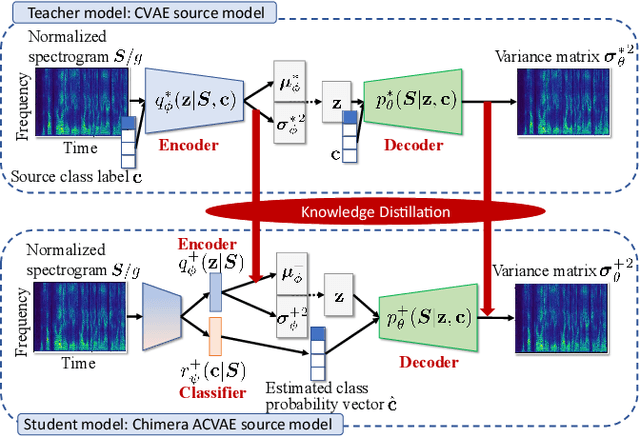
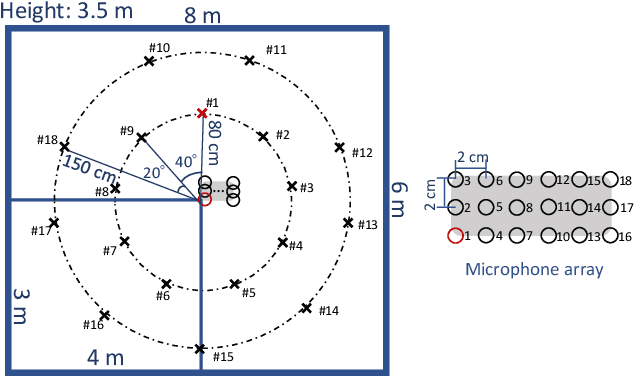
This paper proposes a new source model and training scheme to improve the accuracy and speed of the multichannel variational autoencoder (MVAE) method. The MVAE method is a recently proposed powerful multichannel source separation method. It consists of pretraining a source model represented by a conditional VAE (CVAE) and then estimating separation matrices along with other unknown parameters so that the log-likelihood is non-decreasing given an observed mixture signal. Although the MVAE method has been shown to provide high source separation performance, one drawback is the computational cost of the backpropagation steps in the separation-matrix estimation algorithm. To overcome this drawback, a method called "FastMVAE" was subsequently proposed, which uses an auxiliary classifier VAE (ACVAE) to train the source model. By using the classifier and encoder trained in this way, the optimal parameters of the source model can be inferred efficiently, albeit approximately, in each step of the algorithm. However, the generalization capability of the trained ACVAE source model was not satisfactory, which led to poor performance in situations with unseen data. To improve the generalization capability, this paper proposes a new model architecture (called the "ChimeraACVAE" model) and a training scheme based on knowledge distillation. The experimental results revealed that the proposed source model trained with the proposed loss function achieved better source separation performance with less computation time than FastMVAE. We also confirmed that our methods were able to separate 18 sources with a reasonably good accuracy.
StarGAN-VC+ASR: StarGAN-based Non-Parallel Voice Conversion Regularized by Automatic Speech Recognition
Aug 10, 2021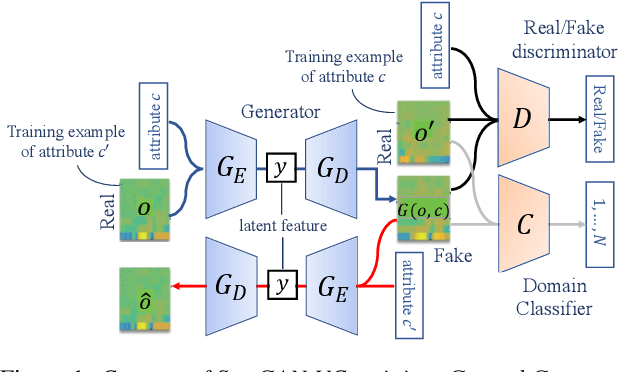
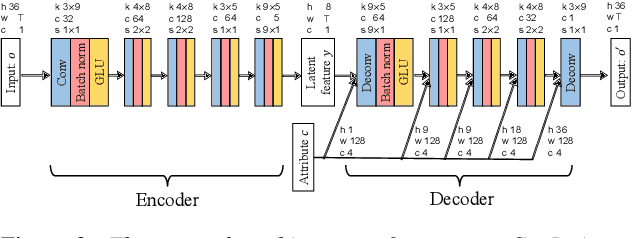
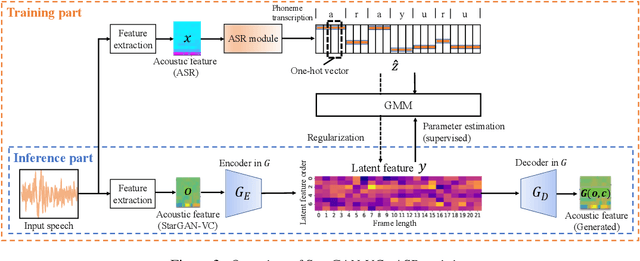
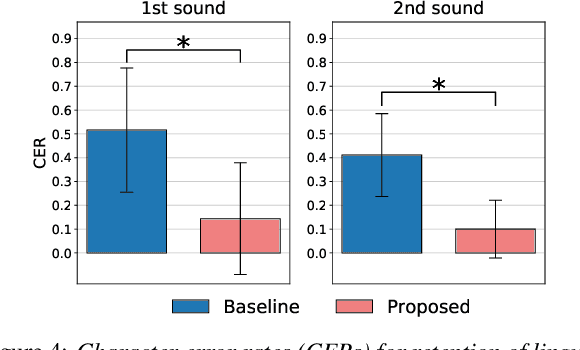
Preserving the linguistic content of input speech is essential during voice conversion (VC). The star generative adversarial network-based VC method (StarGAN-VC) is a recently developed method that allows non-parallel many-to-many VC. Although this method is powerful, it can fail to preserve the linguistic content of input speech when the number of available training samples is extremely small. To overcome this problem, we propose the use of automatic speech recognition to assist model training, to improve StarGAN-VC, especially in low-resource scenarios. Experimental results show that using our proposed method, StarGAN-VC can retain more linguistic information than vanilla StarGAN-VC.
FastS2S-VC: Streaming Non-Autoregressive Sequence-to-Sequence Voice Conversion
Apr 14, 2021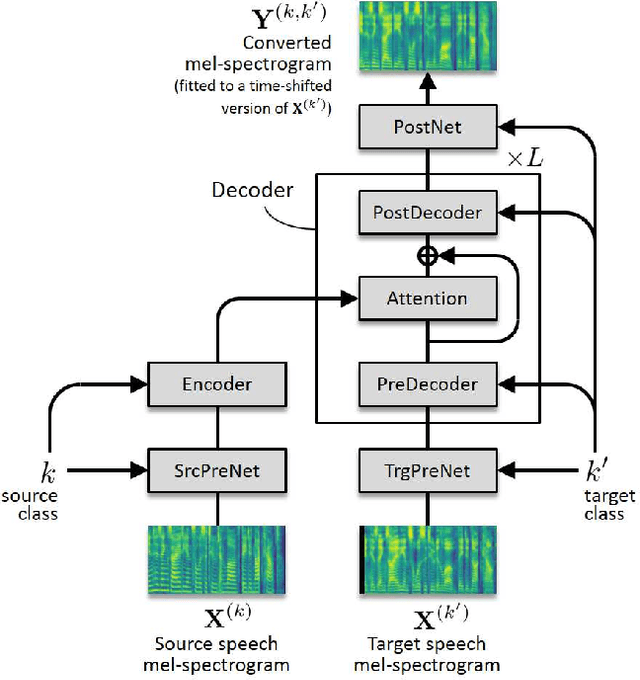
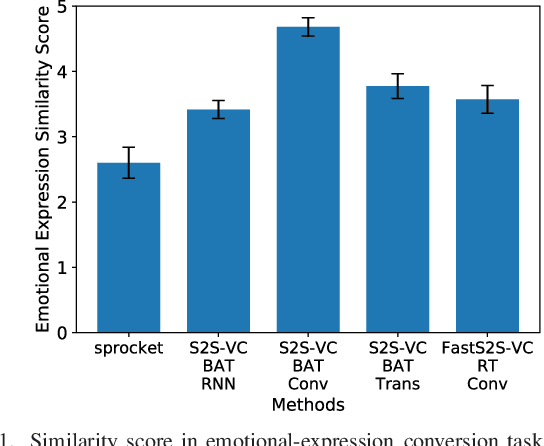
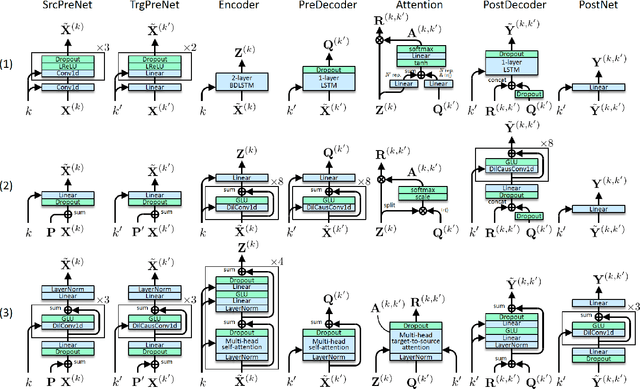
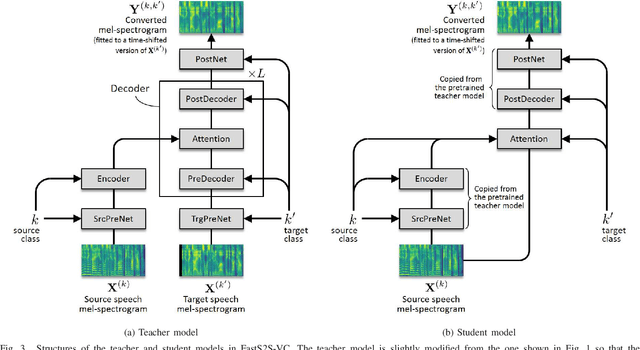
This paper proposes a non-autoregressive extension of our previously proposed sequence-to-sequence (S2S) model-based voice conversion (VC) methods. S2S model-based VC methods have attracted particular attention in recent years for their flexibility in converting not only the voice identity but also the pitch contour and local duration of input speech, thanks to the ability of the encoder-decoder architecture with the attention mechanism. However, one of the obstacles to making these methods work in real-time is the autoregressive (AR) structure. To overcome this obstacle, we develop a method to obtain a model that is free from an AR structure and behaves similarly to the original S2S models, based on a teacher-student learning framework. In our method, called "FastS2S-VC", the student model consists of encoder, decoder, and attention predictor. The attention predictor learns to predict attention distributions solely from source speech along with a target class index with the guidance of those predicted by the teacher model from both source and target speech. Thanks to this structure, the model is freed from an AR structure and allows for parallelization. Furthermore, we show that FastS2S-VC is suitable for real-time implementation based on a sliding-window approach, and describe how to make it run in real-time. Through speaker-identity and emotional-expression conversion experiments, we confirmed that FastS2S-VC was able to speed up the conversion process by 70 to 100 times compared to the original AR-type S2S-VC methods, without significantly degrading the audio quality and similarity to target speech. We also confirmed that the real-time version of FastS2S-VC can be run with a latency of 32 ms when run on a GPU.
StarGAN-based Emotional Voice Conversion for Japanese Phrases
Apr 05, 2021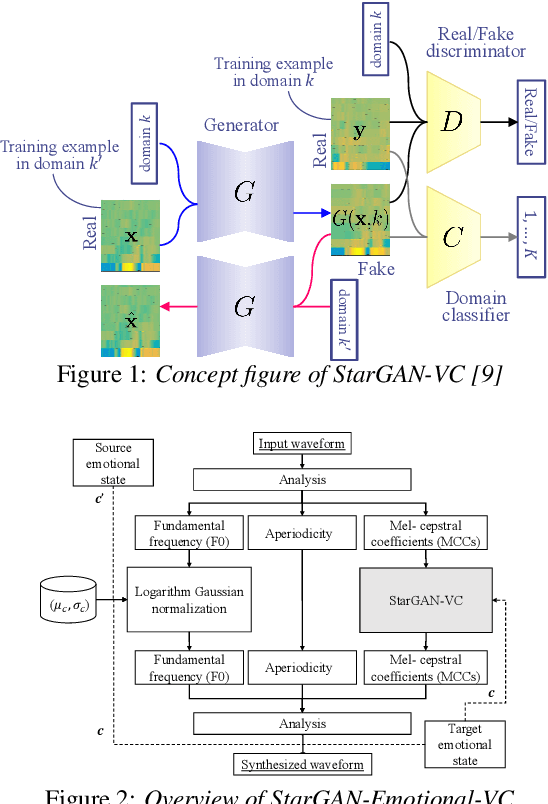
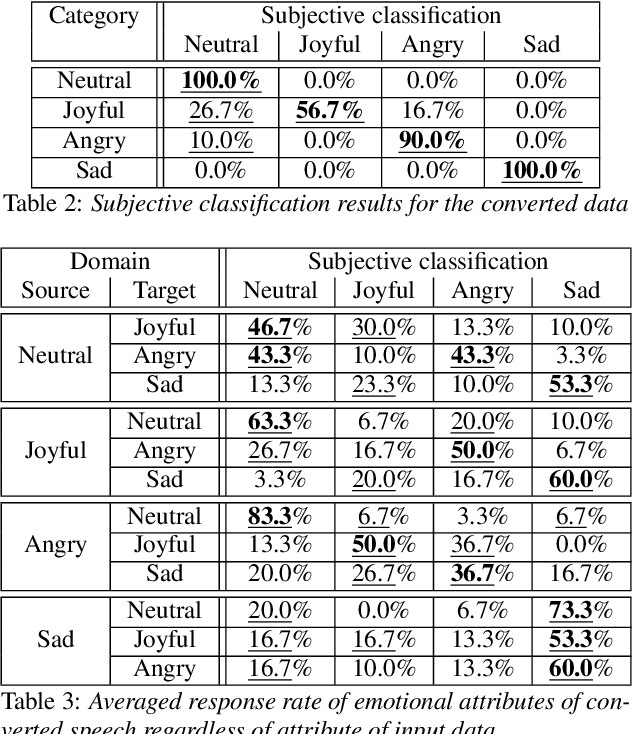
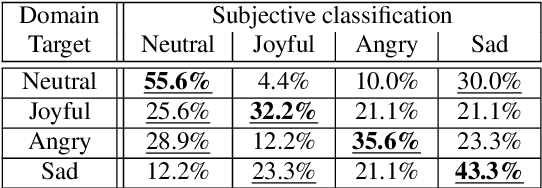
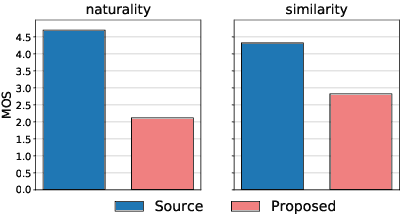
This paper shows that StarGAN-VC, a spectral envelope transformation method for non-parallel many-to-many voice conversion (VC), is capable of emotional VC (EVC). Although StarGAN-VC has been shown to enable speaker identity conversion, its capability for EVC for Japanese phrases has not been clarified. In this paper, we describe the direct application of StarGAN-VC to an EVC task with minimal fundamental frequency and aperiodicity processing. Through subjective evaluation experiments, we evaluated the performance of our StarGAN-EVC system in terms of its ability to achieve EVC for Japanese phrases. The subjective evaluation is conducted in terms of subjective classification and mean opinion score of neutrality and similarity. In addition, the interdependence between the source and target emotional domains was investigated from the perspective of the quality of EVC.
MaskCycleGAN-VC: Learning Non-parallel Voice Conversion with Filling in Frames
Feb 25, 2021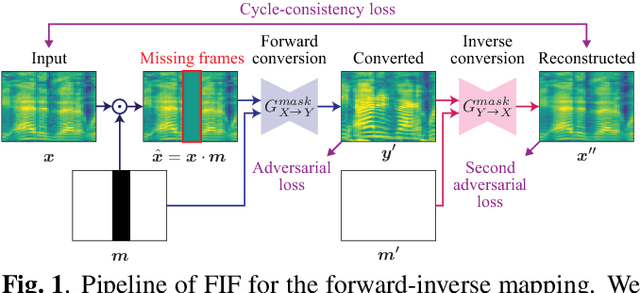
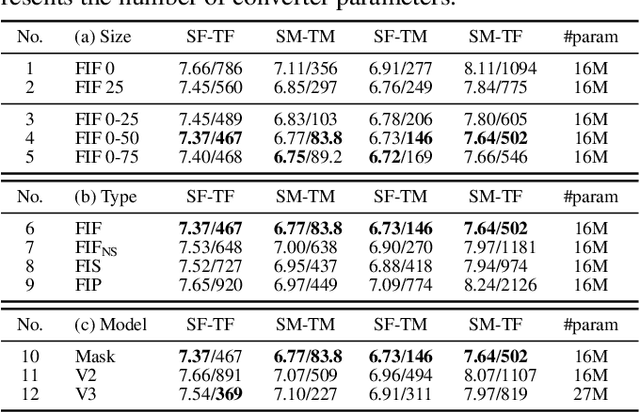
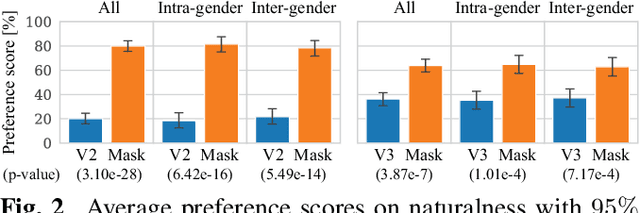
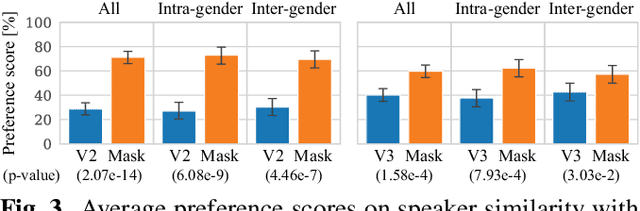
Non-parallel voice conversion (VC) is a technique for training voice converters without a parallel corpus. Cycle-consistent adversarial network-based VCs (CycleGAN-VC and CycleGAN-VC2) are widely accepted as benchmark methods. However, owing to their insufficient ability to grasp time-frequency structures, their application is limited to mel-cepstrum conversion and not mel-spectrogram conversion despite recent advances in mel-spectrogram vocoders. To overcome this, CycleGAN-VC3, an improved variant of CycleGAN-VC2 that incorporates an additional module called time-frequency adaptive normalization (TFAN), has been proposed. However, an increase in the number of learned parameters is imposed. As an alternative, we propose MaskCycleGAN-VC, which is another extension of CycleGAN-VC2 and is trained using a novel auxiliary task called filling in frames (FIF). With FIF, we apply a temporal mask to the input mel-spectrogram and encourage the converter to fill in missing frames based on surrounding frames. This task allows the converter to learn time-frequency structures in a self-supervised manner and eliminates the need for an additional module such as TFAN. A subjective evaluation of the naturalness and speaker similarity showed that MaskCycleGAN-VC outperformed both CycleGAN-VC2 and CycleGAN-VC3 with a model size similar to that of CycleGAN-VC2. Audio samples are available at http://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/maskcyclegan-vc/index.html.
CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-spectrogram Conversion
Oct 22, 2020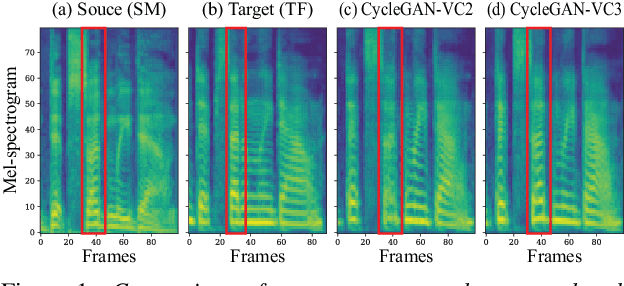
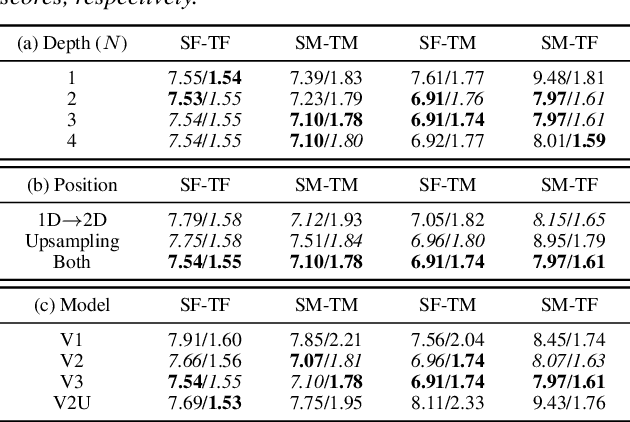
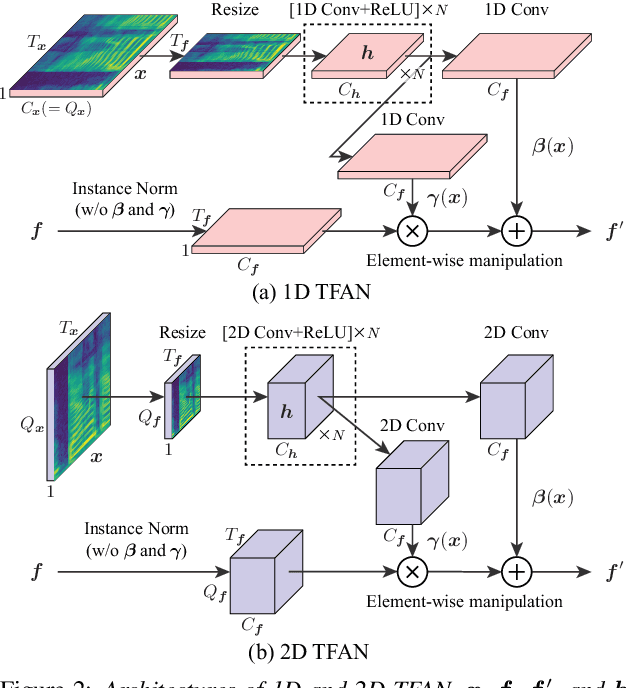
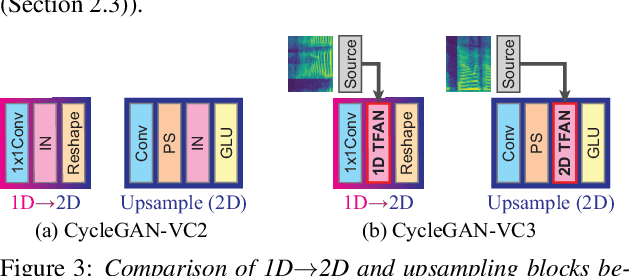
Non-parallel voice conversion (VC) is a technique for learning mappings between source and target speeches without using a parallel corpus. Recently, cycle-consistent adversarial network (CycleGAN)-VC and CycleGAN-VC2 have shown promising results regarding this problem and have been widely used as benchmark methods. However, owing to the ambiguity of the effectiveness of CycleGAN-VC/VC2 for mel-spectrogram conversion, they are typically used for mel-cepstrum conversion even when comparative methods employ mel-spectrogram as a conversion target. To address this, we examined the applicability of CycleGAN-VC/VC2 to mel-spectrogram conversion. Through initial experiments, we discovered that their direct applications compromised the time-frequency structure that should be preserved during conversion. To remedy this, we propose CycleGAN-VC3, an improvement of CycleGAN-VC2 that incorporates time-frequency adaptive normalization (TFAN). Using TFAN, we can adjust the scale and bias of the converted features while reflecting the time-frequency structure of the source mel-spectrogram. We evaluated CycleGAN-VC3 on inter-gender and intra-gender non-parallel VC. A subjective evaluation of naturalness and similarity showed that for every VC pair, CycleGAN-VC3 outperforms or is competitive with the two types of CycleGAN-VC2, one of which was applied to mel-cepstrum and the other to mel-spectrogram. Audio samples are available at http://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/cyclegan-vc3/index.html.
X-DC: Explainable Deep Clustering based on Learnable Spectrogram Templates
Sep 18, 2020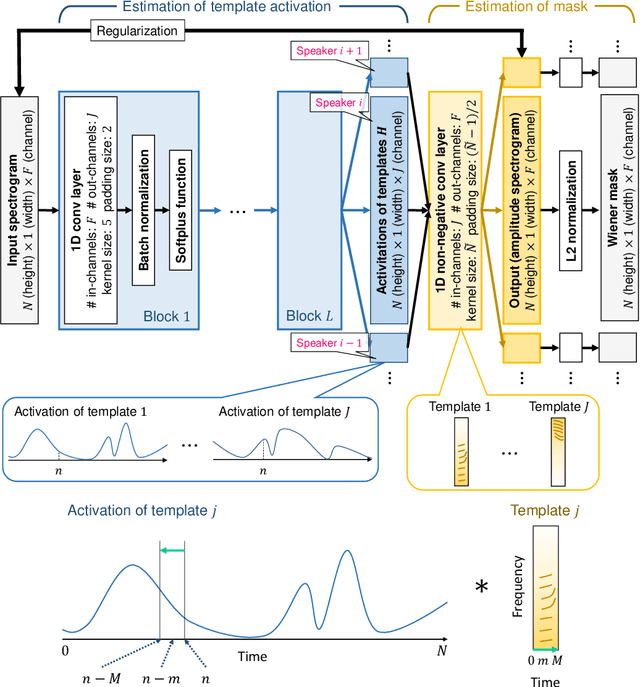
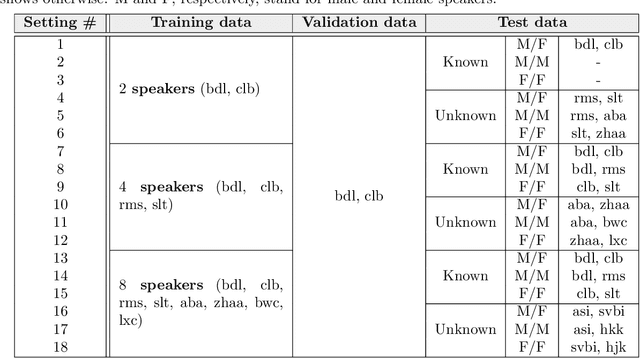
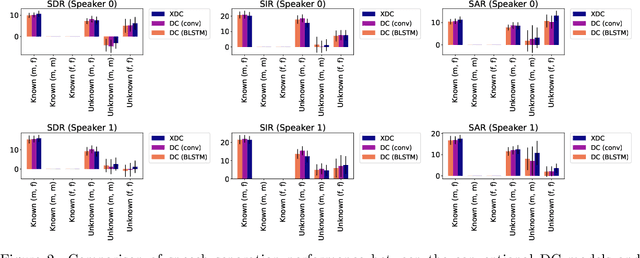
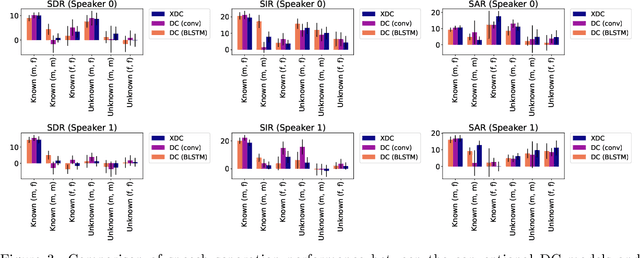
Deep neural networks (DNNs) have achieved substantial predictive performance in various speech processing tasks. Particularly, it has been shown that a monaural speech separation task can be successfully solved with a DNN-based method called deep clustering (DC), which uses a DNN to describe the process of assigning a continuous vector to each time-frequency (TF) bin and measure how likely each pair of TF bins is to be dominated by the same speaker. In DC, the DNN is trained so that the embedding vectors for the TF bins dominated by the same speaker are forced to get close to each other. One concern regarding DC is that the embedding process described by a DNN has a black-box structure, which is usually very hard to interpret. The potential weakness owing to the non-interpretable black-box structure is that it lacks the flexibility of addressing the mismatch between training and test conditions (caused by reverberation, for instance). To overcome this limitation, in this paper, we propose the concept of explainable deep clustering (X-DC), whose network architecture can be interpreted as a process of fitting learnable spectrogram templates to an input spectrogram followed by Wiener filtering. During training, the elements of the spectrogram templates and their activations are constrained to be non-negative, which facilitates the sparsity of their values and thus improves interpretability. The main advantage of this framework is that it naturally allows us to incorporate a model adaptation mechanism into the network thanks to its physically interpretable structure. We experimentally show that the proposed X-DC enables us to visualize and understand the clues for the model to determine the embedding vectors while achieving speech separation performance comparable to that of the original DC models.
Non-Parallel Voice Conversion with Augmented Classifier Star Generative Adversarial Networks
Sep 11, 2020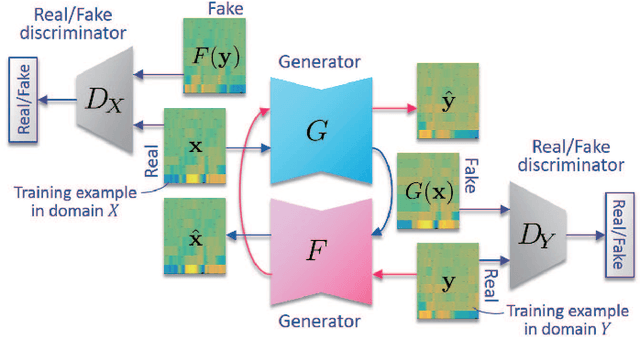
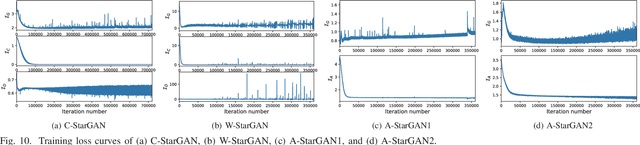
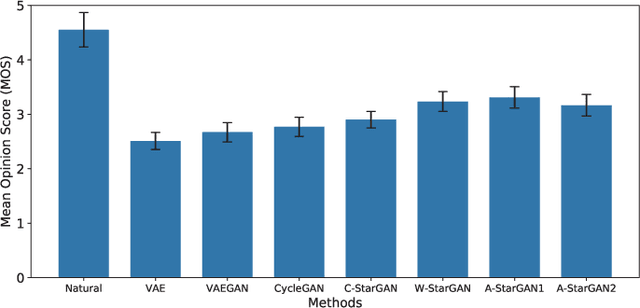
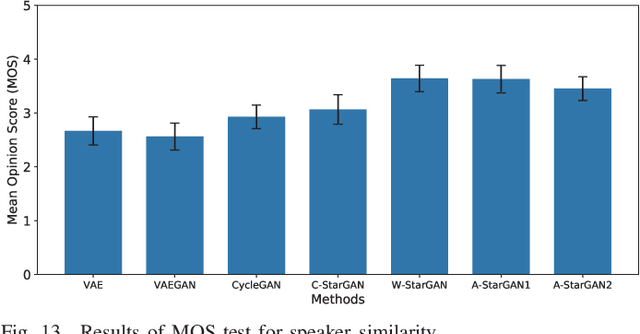
We previously proposed a method that allows for non-parallel voice conversion (VC) by using a variant of generative adversarial networks (GANs) called StarGAN. The main features of our method, called StarGAN-VC, are as follows: First, it requires no parallel utterances, transcriptions, or time alignment procedures for speech generator training. Second, it can simultaneously learn mappings across multiple domains using a single generator network so that it can fully exploit available training data collected from multiple domains to capture latent features that are common to all the domains. Third, it is able to generate converted speech signals quickly enough to allow real-time implementations and requires only several minutes of training examples to generate reasonably realistic-sounding speech. In this paper, we describe three formulations of StarGAN, including a newly introduced novel StarGAN variant called "Augmented classifier StarGAN (A-StarGAN)", and compare them in a non-parallel VC task. We also compare them with several baseline methods.
Pretraining Techniques for Sequence-to-Sequence Voice Conversion
Aug 07, 2020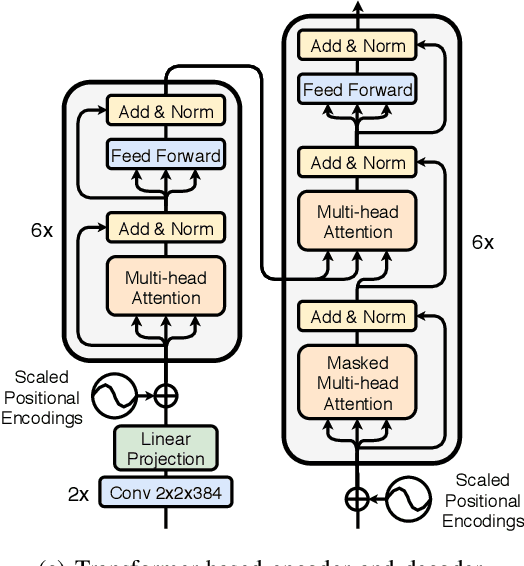
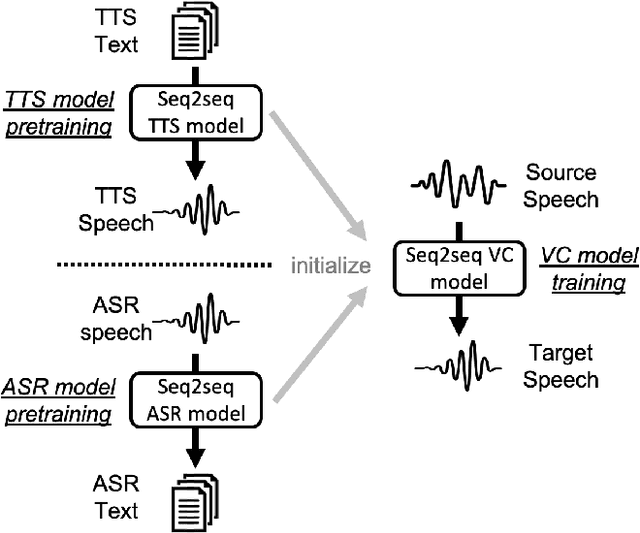
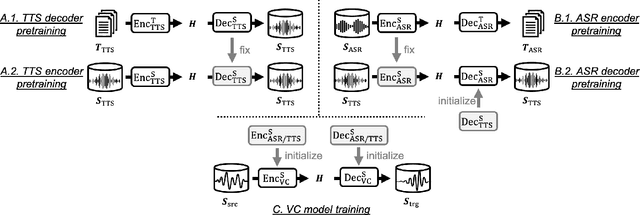
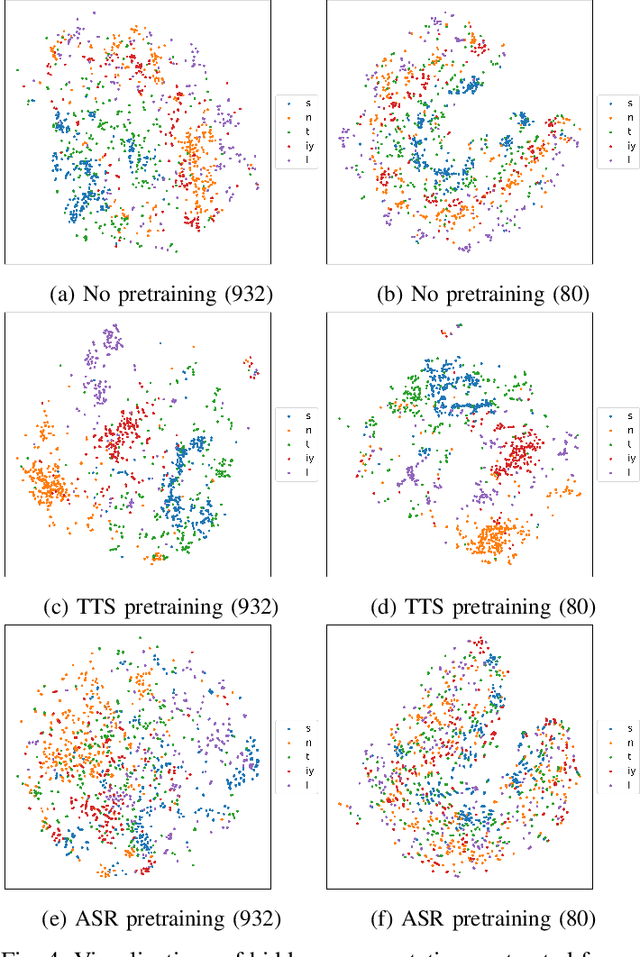
Sequence-to-sequence (seq2seq) voice conversion (VC) models are attractive owing to their ability to convert prosody. Nonetheless, without sufficient data, seq2seq VC models can suffer from unstable training and mispronunciation problems in the converted speech, thus far from practical. To tackle these shortcomings, we propose to transfer knowledge from other speech processing tasks where large-scale corpora are easily available, typically text-to-speech (TTS) and automatic speech recognition (ASR). We argue that VC models initialized with such pretrained ASR or TTS model parameters can generate effective hidden representations for high-fidelity, highly intelligible converted speech. We apply such techniques to recurrent neural network (RNN)-based and Transformer based models, and through systematical experiments, we demonstrate the effectiveness of the pretraining scheme and the superiority of Transformer based models over RNN-based models in terms of intelligibility, naturalness, and similarity.
Many-to-Many Voice Transformer Network
Jun 07, 2020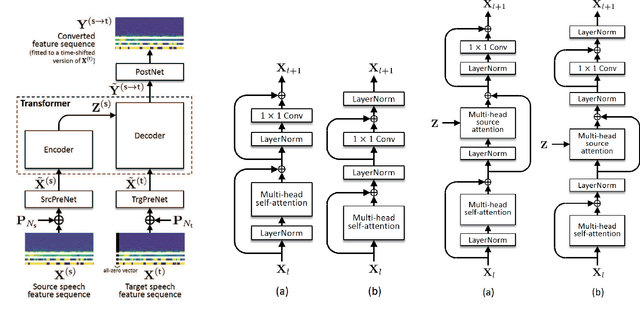
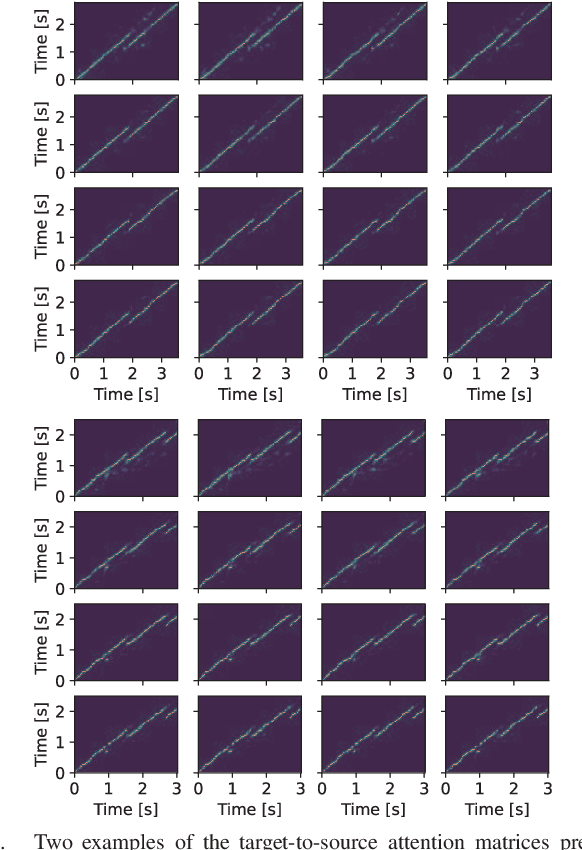
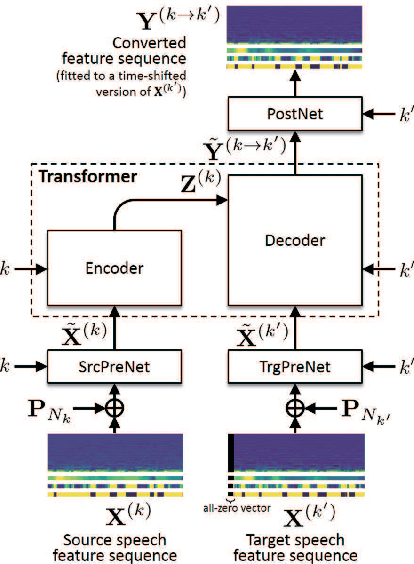
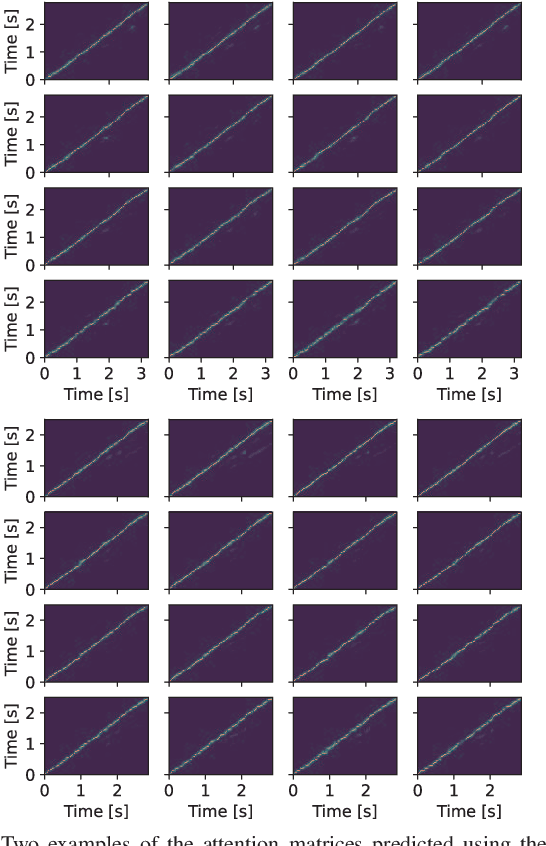
This paper proposes a voice conversion (VC) method based on a sequence-to-sequence (S2S) learning framework, which enables simultaneous conversion of the voice characteristics, pitch contour, and duration of input speech. We previously proposed an S2S-based VC method using a transformer network architecture called the voice transformer network (VTN). The original VTN was designed to learn only a mapping of speech feature sequences from one domain into another. The main idea we propose is an extension of the original VTN that can simultaneously learn mappings among multiple domains. This extension called the many-to-many VTN makes it able to fully use available training data collected from multiple domains by capturing common latent features that can be shared across different domains. It also allows us to introduce a training loss called the identity mapping loss to ensure that the input feature sequence will remain unchanged when it already belongs to the target domain. Using this particular loss for model training has been found to be extremely effective in improving the performance of the model at test time. We conducted speaker identity conversion experiments and found that our model obtained higher sound quality and speaker similarity than baseline methods. We also found that our model, with a slight modification to its architecture, could handle any-to-many conversion tasks reasonably well.