 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Adapters for Altering LLM Vocabularies: What Languages Benefit the Most?
Oct 12, 2024



Vocabulary adaptation, which integrates new vocabulary into pre-trained language models (LMs), enables expansion to new languages and mitigates token over-fragmentation. However, existing approaches are limited by their reliance on heuristic or external embeddings. We propose VocADT, a novel method for vocabulary adaptation using adapter modules that are trained to learn the optimal linear combination of existing embeddings while keeping the model's weights fixed. VocADT offers a flexible and scalable solution without requiring external resources or language constraints. Across 11 languages-with various scripts, resource availability, and fragmentation-we demonstrate that VocADT outperforms the original Mistral model and other baselines across various multilingual tasks. We find that Latin-script languages and highly fragmented languages benefit the most from vocabulary adaptation. We further fine-tune the adapted model on the generative task of machine translation and find that vocabulary adaptation is still beneficial after fine-tuning and that VocADT is the most effective method.
X-ALMA: Plug & Play Modules and Adaptive Rejection for Quality Translation at Scale
Oct 04, 2024



Large language models (LLMs) have achieved remarkable success across various NLP tasks, yet their focus has predominantly been on English due to English-centric pre-training and limited multilingual data. While some multilingual LLMs claim to support for hundreds of languages, models often fail to provide high-quality response for mid- and low-resource languages, leading to imbalanced performance heavily skewed in favor of high-resource languages like English and Chinese. In this paper, we prioritize quality over scaling number of languages, with a focus on multilingual machine translation task, and introduce X-ALMA, a model designed with a commitment to ensuring top-tier performance across 50 diverse languages, regardless of their resource levels. X-ALMA surpasses state-of-the-art open-source multilingual LLMs, such as Aya-101 and Aya-23, in every single translation direction on the FLORES and WMT'23 test datasets according to COMET-22. This is achieved by plug-and-play language-specific module architecture to prevent language conflicts during training and a carefully designed training regimen with novel optimization methods to maximize the translation performance. At the final stage of training regimen, our proposed Adaptive Rejection Preference Optimization (ARPO) surpasses existing preference optimization methods in translation tasks.
On-the-Fly Fusion of Large Language Models and Machine Translation
Nov 14, 2023



We propose the on-the-fly ensembling of a machine translation model with an LLM, prompted on the same task and input. We perform experiments on 4 language pairs (both directions) with varying data amounts. We find that a slightly weaker-at-translation LLM can improve translations of a NMT model, and ensembling with an LLM can produce better translations than ensembling two stronger MT models. We combine our method with various techniques from LLM prompting, such as in context learning and translation context.
Meta-Learning of NAS for Few-shot Learning in Medical Image Applications
Mar 16, 2022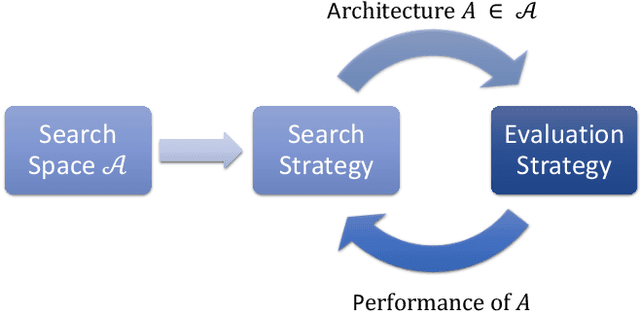
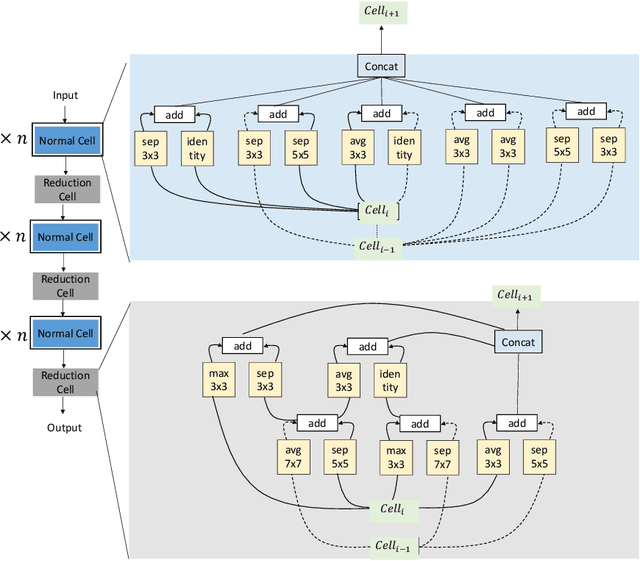
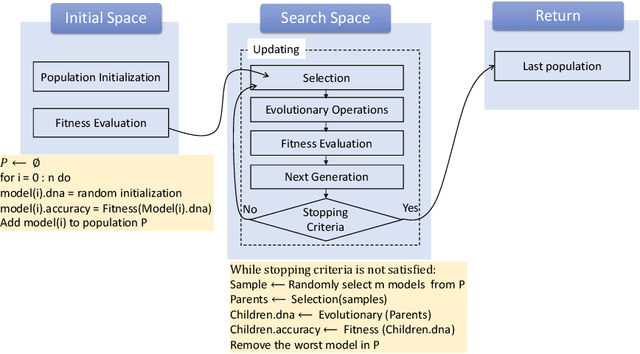
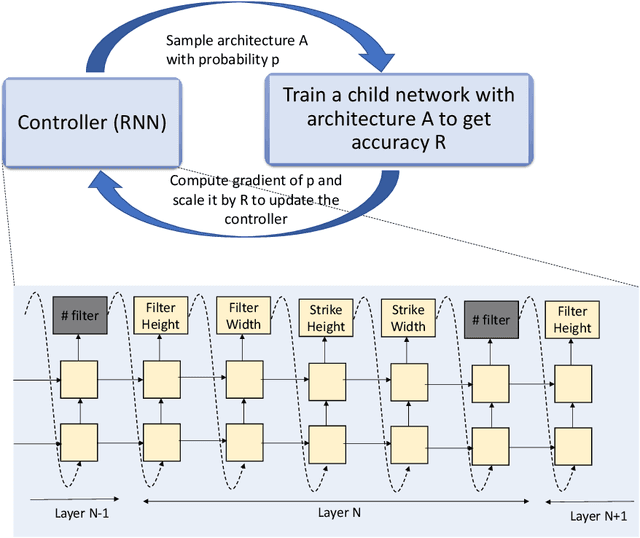
Deep learning methods have been successful in solving tasks in machine learning and have made breakthroughs in many sectors owing to their ability to automatically extract features from unstructured data. However, their performance relies on manual trial-and-error processes for selecting an appropriate network architecture, hyperparameters for training, and pre-/post-procedures. Even though it has been shown that network architecture plays a critical role in learning feature representation feature from data and the final performance, searching for the best network architecture is computationally intensive and heavily relies on researchers' experience. Automated machine learning (AutoML) and its advanced techniques i.e. Neural Architecture Search (NAS) have been promoted to address those limitations. Not only in general computer vision tasks, but NAS has also motivated various applications in multiple areas including medical imaging. In medical imaging, NAS has significant progress in improving the accuracy of image classification, segmentation, reconstruction, and more. However, NAS requires the availability of large annotated data, considerable computation resources, and pre-defined tasks. To address such limitations, meta-learning has been adopted in the scenarios of few-shot learning and multiple tasks. In this book chapter, we first present a brief review of NAS by discussing well-known approaches in search space, search strategy, and evaluation strategy. We then introduce various NAS approaches in medical imaging with different applications such as classification, segmentation, detection, reconstruction, etc. Meta-learning in NAS for few-shot learning and multiple tasks is then explained. Finally, we describe several open problems in NAS.
GDCA: GAN-based single image super resolution with Dual discriminators and Channel Attention
Nov 09, 2021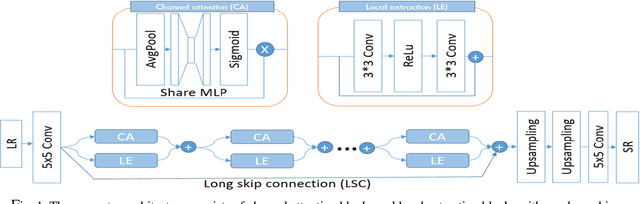
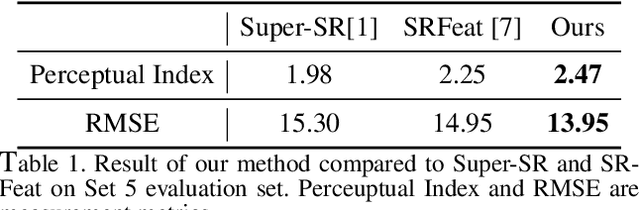


Single Image Super-Resolution (SISR) is a very active research field. This paper addresses SISR by using a GAN-based approach with dual discriminators and incorporating it with an attention mechanism. The experimental results show that GDCA can generate sharper and high pleasing images compare to other conventional methods.
Fast Neural Machine Translation Implementation
Jun 07, 2018
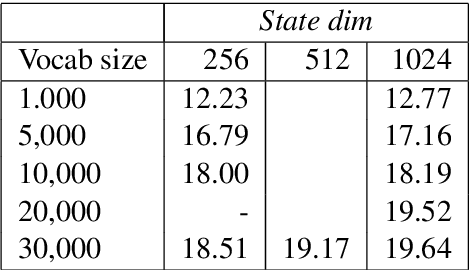
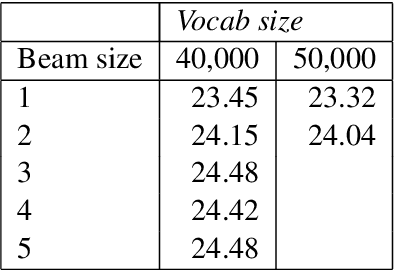
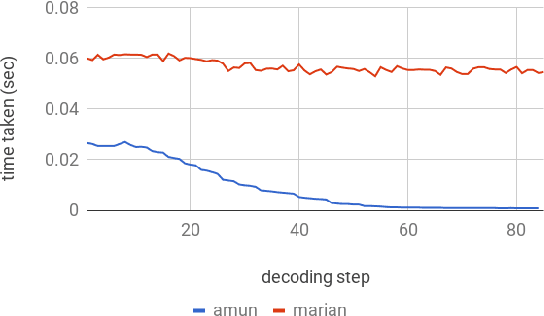
This paper describes the submissions to the efficiency track for GPUs at the Workshop for Neural Machine Translation and Generation by members of the University of Edinburgh, Adam Mickiewicz University, Tilde and University of Alicante. We focus on efficient implementation of the recurrent deep-learning model as implemented in Amun, the fast inference engine for neural machine translation. We improve the performance with an efficient mini-batching algorithm, and by fusing the softmax operation with the k-best extraction algorithm. Submissions using Amun were first, second and third fastest in the GPU efficiency track.
Marian: Cost-effective High-Quality Neural Machine Translation in C++
May 30, 2018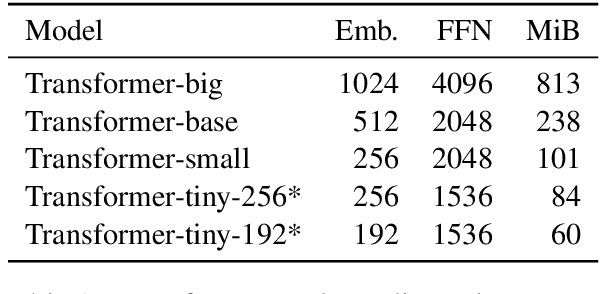
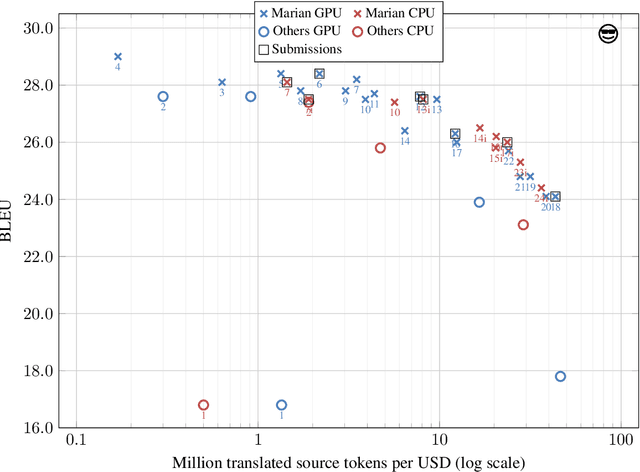
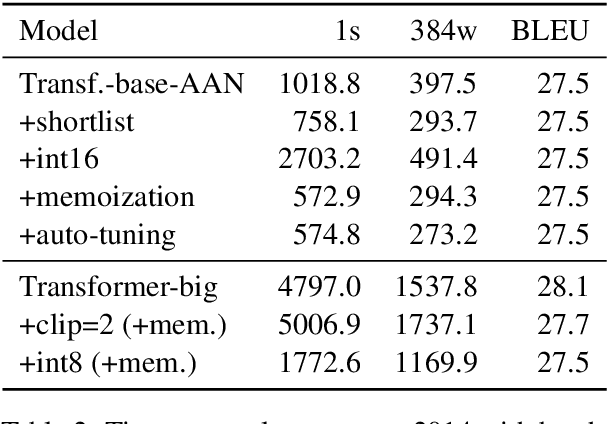
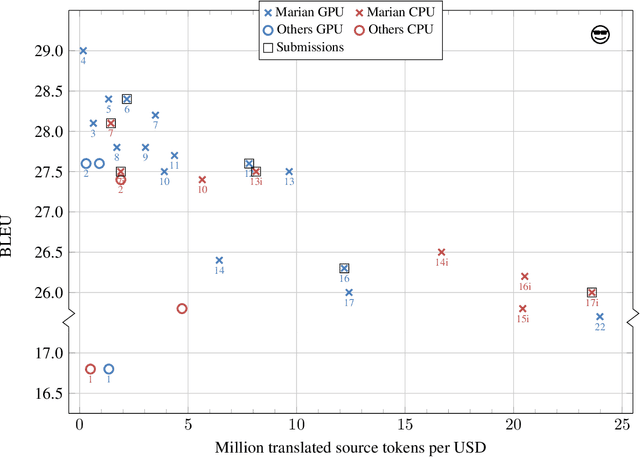
This paper describes the submissions of the "Marian" team to the WNMT 2018 shared task. We investigate combinations of teacher-student training, low-precision matrix products, auto-tuning and other methods to optimize the Transformer model on GPU and CPU. By further integrating these methods with the new averaging attention networks, a recently introduced faster Transformer variant, we create a number of high-quality, high-performance models on the GPU and CPU, dominating the Pareto frontier for this shared task.
Exploring Hyper-Parameter Optimization for Neural Machine Translation on GPU Architectures
May 05, 2018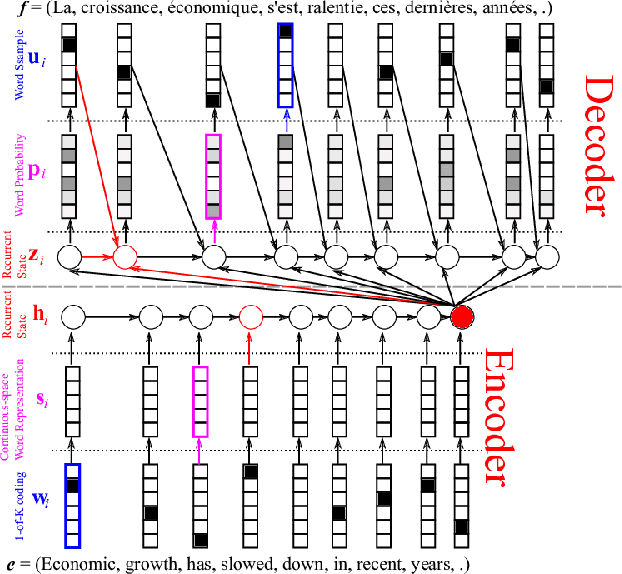
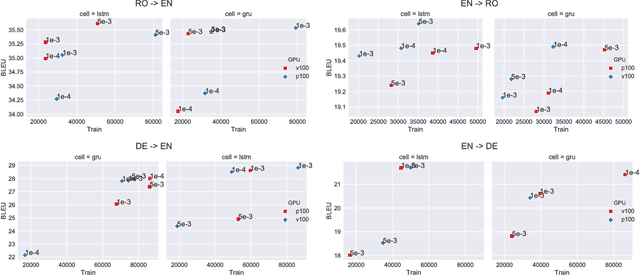
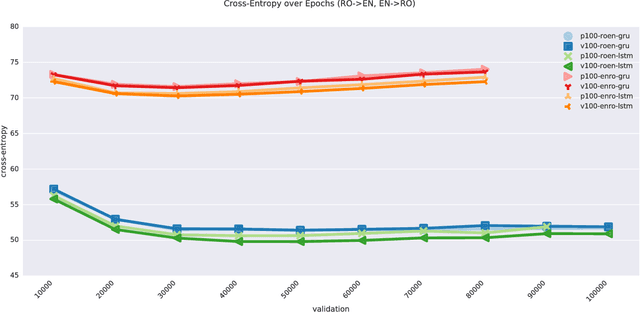
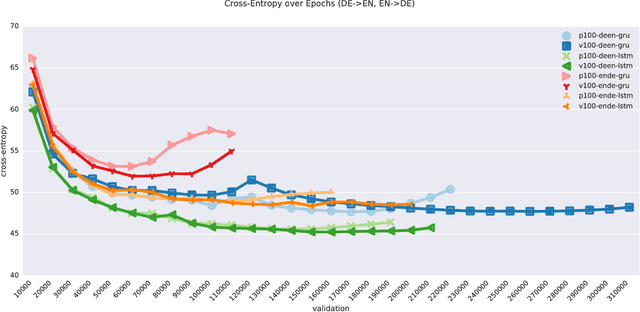
Neural machine translation (NMT) has been accelerated by deep learning neural networks over statistical-based approaches, due to the plethora and programmability of commodity heterogeneous computing architectures such as FPGAs and GPUs and the massive amount of training corpuses generated from news outlets, government agencies and social media. Training a learning classifier for neural networks entails tuning hyper-parameters that would yield the best performance. Unfortunately, the number of parameters for machine translation include discrete categories as well as continuous options, which makes for a combinatorial explosive problem. This research explores optimizing hyper-parameters when training deep learning neural networks for machine translation. Specifically, our work investigates training a language model with Marian NMT. Results compare NMT under various hyper-parameter settings across a variety of modern GPU architecture generations in single node and multi-node settings, revealing insights on which hyper-parameters matter most in terms of performance, such as words processed per second, convergence rates, and translation accuracy, and provides insights on how to best achieve high-performing NMT systems.
Marian: Fast Neural Machine Translation in C++
Apr 04, 2018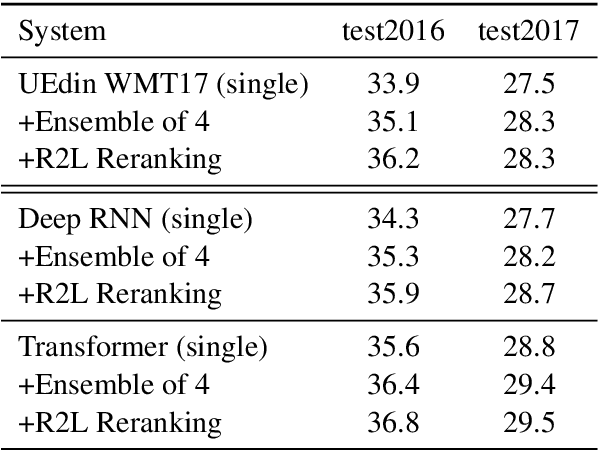
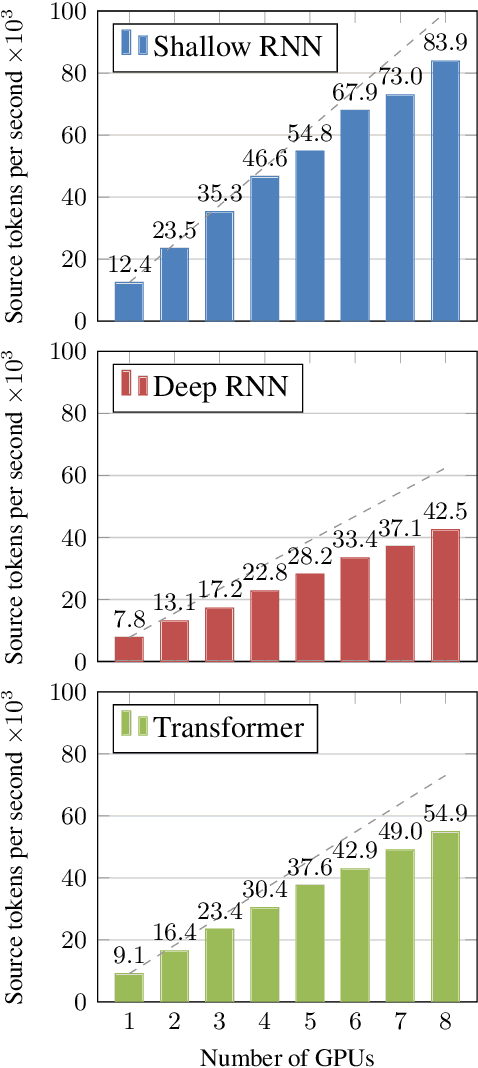
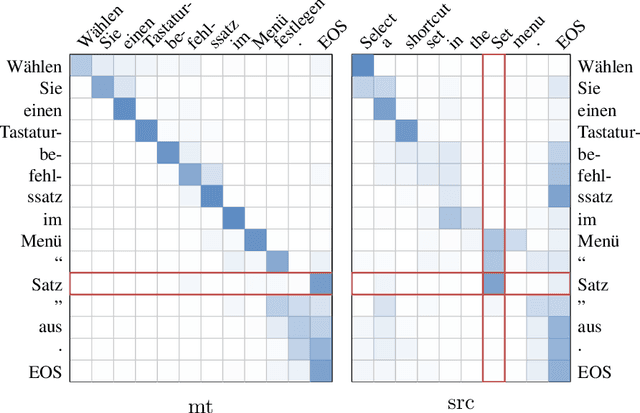
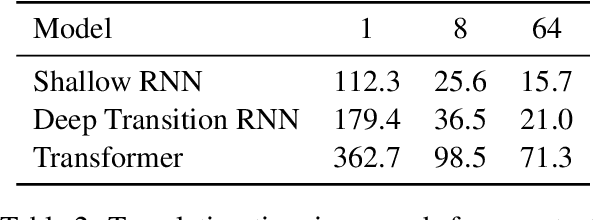
We present Marian, an efficient and self-contained Neural Machine Translation framework with an integrated automatic differentiation engine based on dynamic computation graphs. Marian is written entirely in C++. We describe the design of the encoder-decoder framework and demonstrate that a research-friendly toolkit can achieve high training and translation speed.