 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuropean Language Grid: An Overview
Mar 30, 2020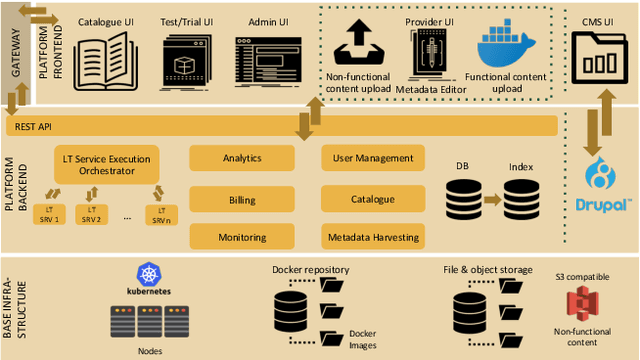

With 24 official EU and many additional languages, multilingualism in Europe and an inclusive Digital Single Market can only be enabled through Language Technologies (LTs). European LT business is dominated by hundreds of SMEs and a few large players. Many are world-class, with technologies that outperform the global players. However, European LT business is also fragmented, by nation states, languages, verticals and sectors, significantly holding back its impact. The European Language Grid (ELG) project addresses this fragmentation by establishing the ELG as the primary platform for LT in Europe. The ELG is a scalable cloud platform, providing, in an easy-to-integrate way, access to hundreds of commercial and non-commercial LTs for all European languages, including running tools and services as well as data sets and resources. Once fully operational, it will enable the commercial and non-commercial European LT community to deposit and upload their technologies and data sets into the ELG, to deploy them through the grid, and to connect with other resources. The ELG will boost the Multilingual Digital Single Market towards a thriving European LT community, creating new jobs and opportunities. Furthermore, the ELG project organises two open calls for up to 20 pilot projects. It also sets up 32 National Competence Centres (NCCs) and the European LT Council (LTC) for outreach and coordination purposes.
The University of Edinburgh's Submissions to the WMT19 News Translation Task
Jul 12, 2019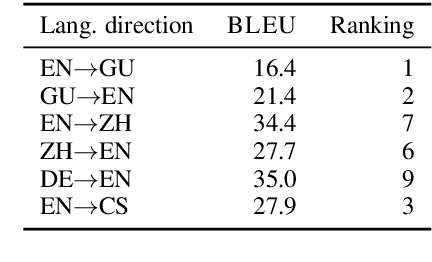
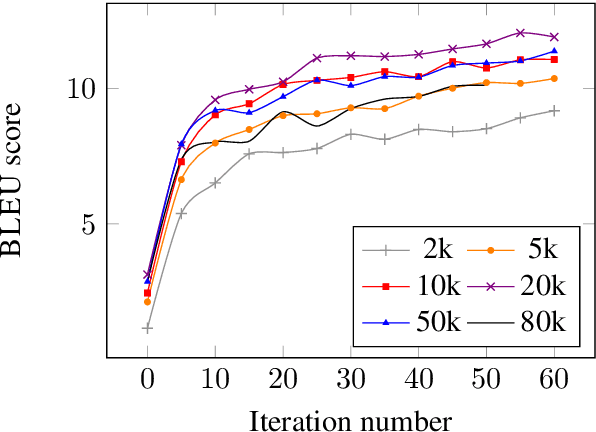
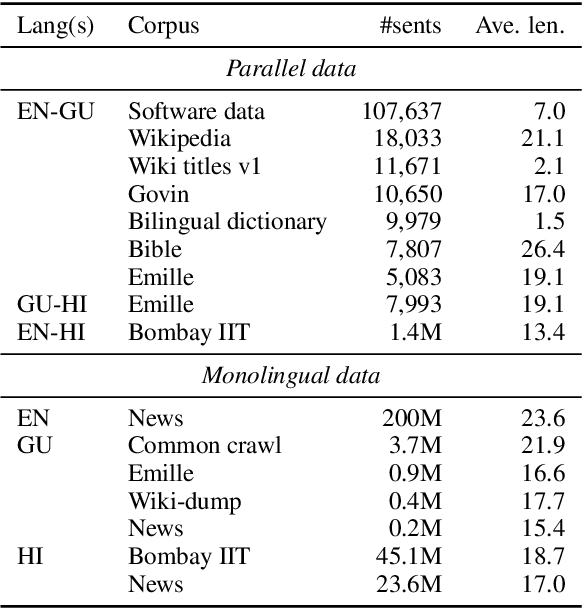

The University of Edinburgh participated in the WMT19 Shared Task on News Translation in six language directions: English-to-Gujarati, Gujarati-to-English, English-to-Chinese, Chinese-to-English, German-to-English, and English-to-Czech. For all translation directions, we created or used back-translations of monolingual data in the target language as additional synthetic training data. For English-Gujarati, we also explored semi-supervised MT with cross-lingual language model pre-training, and translation pivoting through Hindi. For translation to and from Chinese, we investigated character-based tokenisation vs. sub-word segmentation of Chinese text. For German-to-English, we studied the impact of vast amounts of back-translated training data on translation quality, gaining a few additional insights over Edunov et al. (2018). For English-to-Czech, we compared different pre-processing and tokenisation regimes.
Marian: Fast Neural Machine Translation in C++
Apr 04, 2018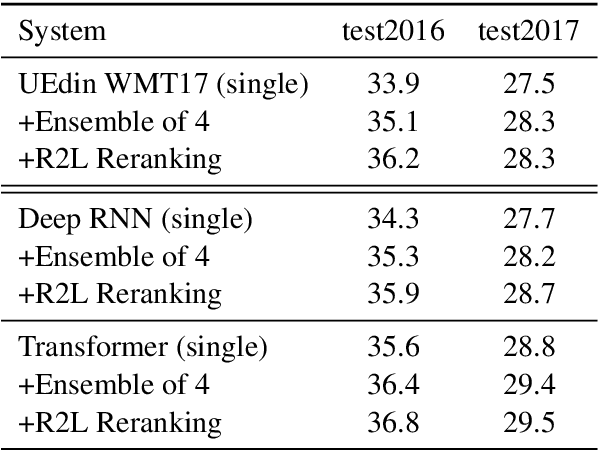
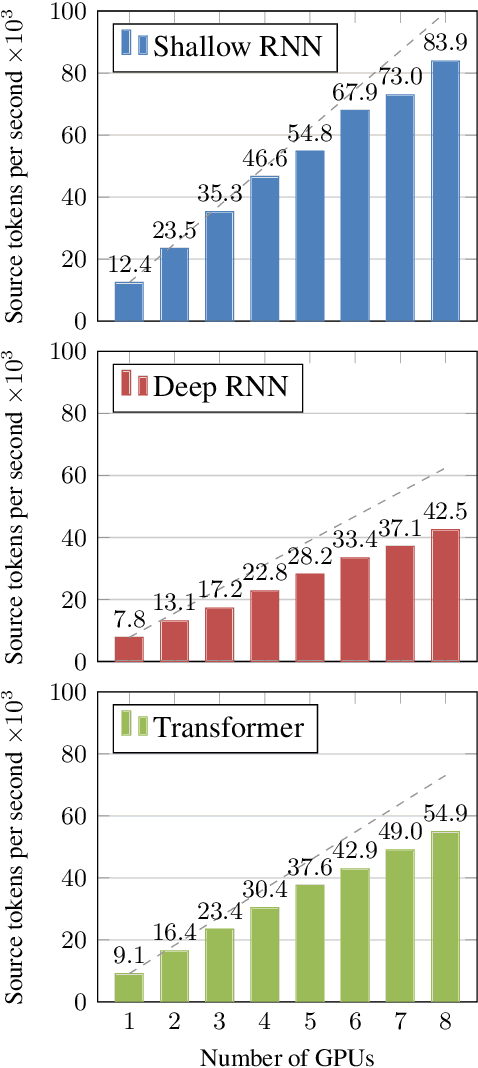
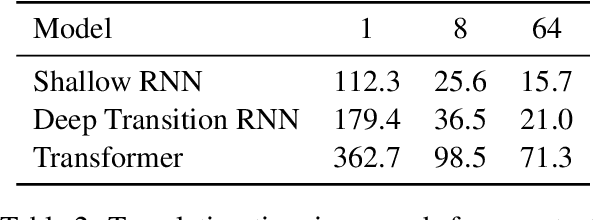
We present Marian, an efficient and self-contained Neural Machine Translation framework with an integrated automatic differentiation engine based on dynamic computation graphs. Marian is written entirely in C++. We describe the design of the encoder-decoder framework and demonstrate that a research-friendly toolkit can achieve high training and translation speed.
The University of Edinburgh's Neural MT Systems for WMT17
Aug 02, 2017
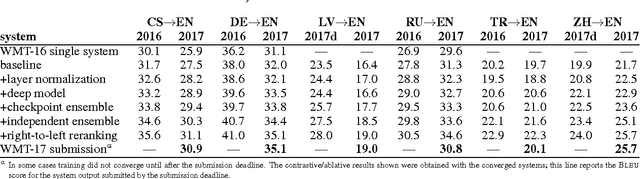
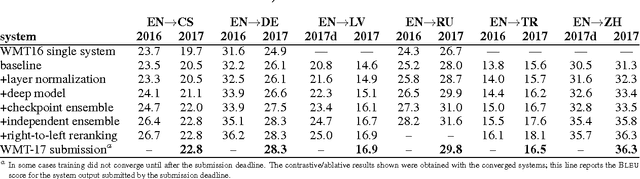

This paper describes the University of Edinburgh's submissions to the WMT17 shared news translation and biomedical translation tasks. We participated in 12 translation directions for news, translating between English and Czech, German, Latvian, Russian, Turkish and Chinese. For the biomedical task we submitted systems for English to Czech, German, Polish and Romanian. Our systems are neural machine translation systems trained with Nematus, an attentional encoder-decoder. We follow our setup from last year and build BPE-based models with parallel and back-translated monolingual training data. Novelties this year include the use of deep architectures, layer normalization, and more compact models due to weight tying and improvements in BPE segmentations. We perform extensive ablative experiments, reporting on the effectivenes of layer normalization, deep architectures, and different ensembling techniques.
Regularization techniques for fine-tuning in neural machine translation
Jul 31, 2017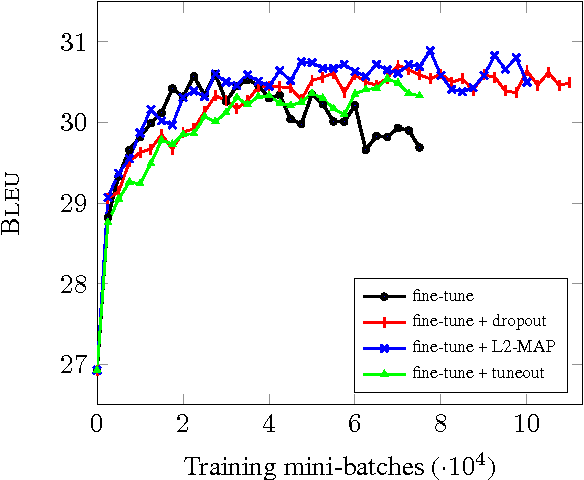
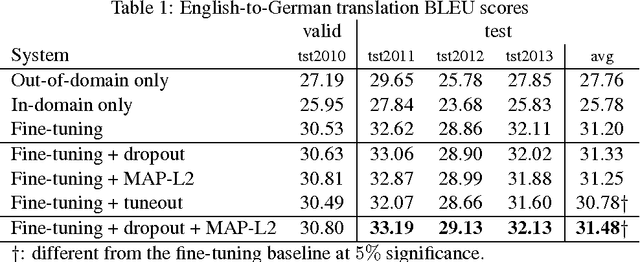
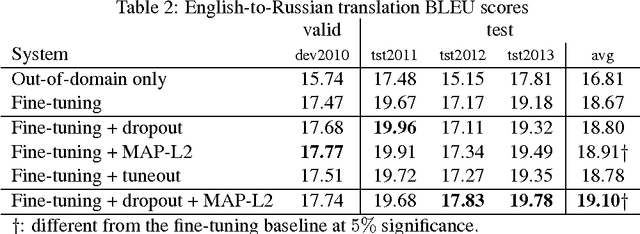
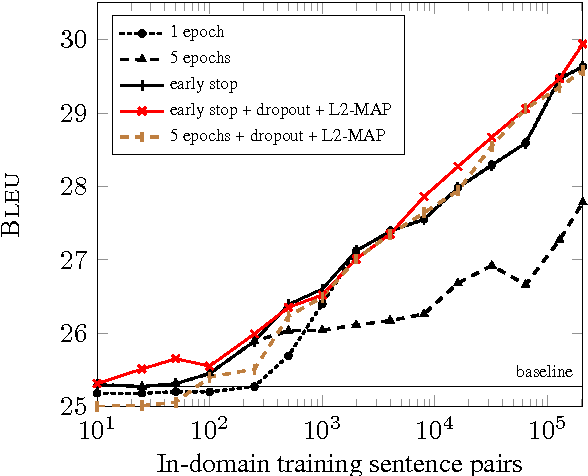
We investigate techniques for supervised domain adaptation for neural machine translation where an existing model trained on a large out-of-domain dataset is adapted to a small in-domain dataset. In this scenario, overfitting is a major challenge. We investigate a number of techniques to reduce overfitting and improve transfer learning, including regularization techniques such as dropout and L2-regularization towards an out-of-domain prior. In addition, we introduce tuneout, a novel regularization technique inspired by dropout. We apply these techniques, alone and in combination, to neural machine translation, obtaining improvements on IWSLT datasets for English->German and English->Russian. We also investigate the amounts of in-domain training data needed for domain adaptation in NMT, and find a logarithmic relationship between the amount of training data and gain in BLEU score.
Bilingual Document Alignment with Latent Semantic Indexing
Jul 29, 2017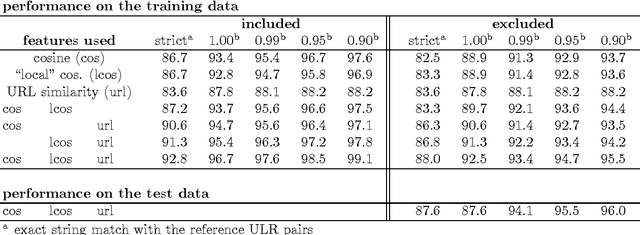

We apply cross-lingual Latent Semantic Indexing to the Bilingual Document Alignment Task at WMT16. Reduced-rank singular value decomposition of a bilingual term-document matrix derived from known English/French page pairs in the training data allows us to map monolingual documents into a joint semantic space. Two variants of cosine similarity between the vectors that place each document into the joint semantic space are combined with a measure of string similarity between corresponding URLs to produce 1:1 alignments of English/French web pages in a variety of domains. The system achieves a recall of ca. 88% if no in-domain data is used for building the latent semantic model, and 93% if such data is included. Analysing the system's errors on the training data, we argue that evaluating aligner performance based on exact URL matches under-estimates their true performance and propose an alternative that is able to account for duplicates and near-duplicates in the underlying data.