 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Diverse Lung Nodules Wherever Massively: 3D Multi-Conditional GAN-based CT Image Augmentation for Object Detection
Jun 12, 2019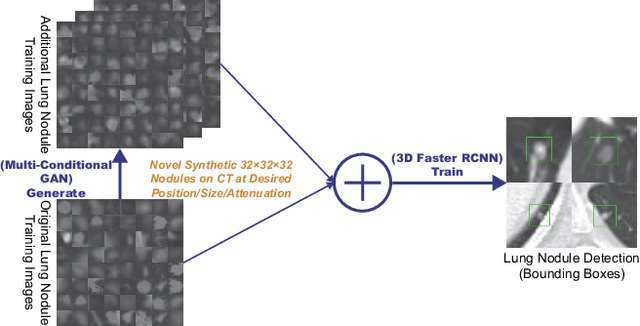
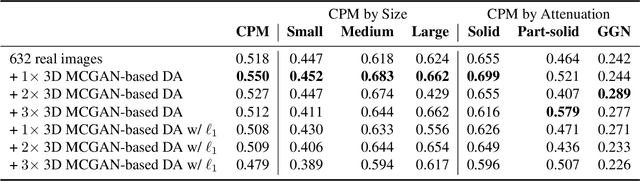
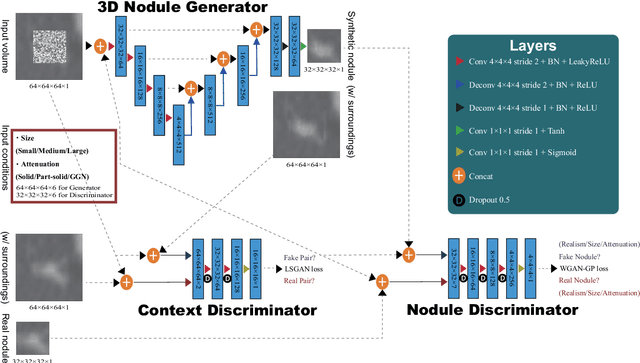
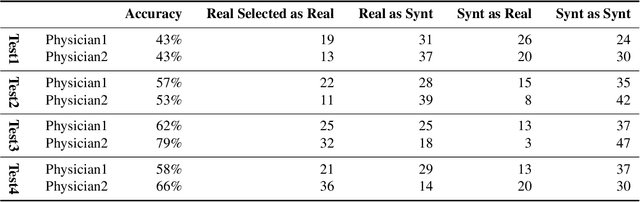
Accurate computer-assisted diagnosis, relying on large-scale annotated pathological images, can alleviate the risk of overlooking the diagnosis. Unfortunately, in medical imaging, most available datasets are small/fragmented. To tackle this, as a Data Augmentation (DA) method, 3D conditional Generative Adversarial Networks (GANs) can synthesize desired realistic/diverse 3D images as additional training data. However, no 3D conditional GAN-based DA approach exists for general bounding box-based 3D object detection, while it can locate disease areas with physicians' minimum annotation cost, unlike rigorous 3D segmentation. Moreover, since lesions vary in position/size/attenuation, further GAN-based DA performance requires multiple conditions. Therefore, we propose 3D Multi-Conditional GAN (MCGAN) to generate realistic/diverse 32 x 32 x 32 nodules placed naturally on lung Computed Tomography images to boost sensitivity in 3D object detection. Our MCGAN adopts two discriminators for conditioning: the context discriminator learns to classify real vs synthetic nodule/surrounding pairs with noise box-centered surroundings; the nodule discriminator attempts to classify real vs synthetic nodules with size/attenuation conditions. The results show that 3D Convolutional Neural Network-based detection can achieve higher sensitivity under any nodule size/attenuation at fixed False Positive rates and overcome the medical data paucity with the MCGAN-generated realistic nodules---even expert physicians fail to distinguish them from the real ones in Visual Turing Test.
Combining Noise-to-Image and Image-to-Image GANs: Brain MR Image Augmentation for Tumor Detection
May 31, 2019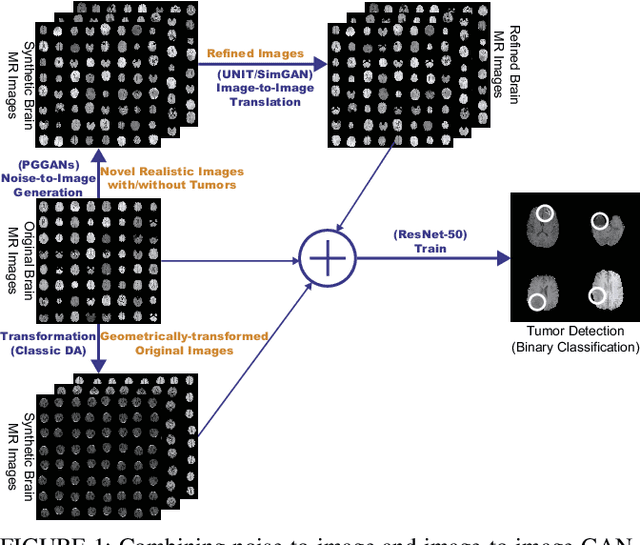
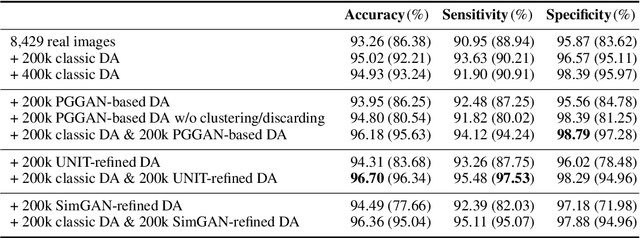
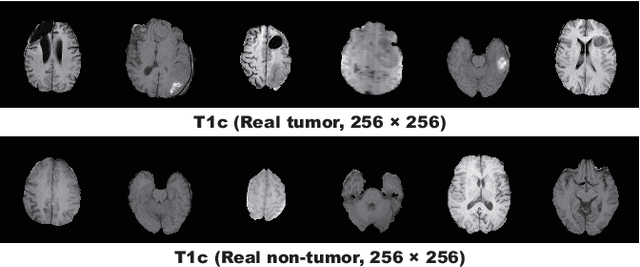
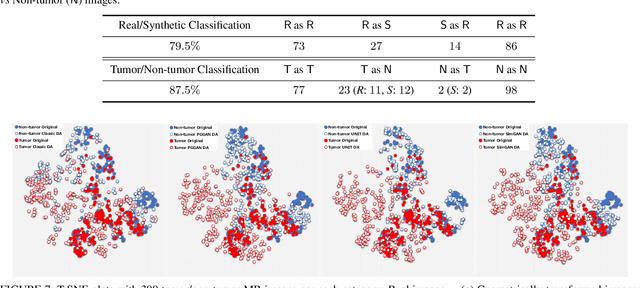
Convolutional Neural Networks (CNNs) can achieve excellent computer-assisted diagnosis performance, relying on sufficient annotated training data. Unfortunately, most medical imaging datasets, often collected from various scanners, are small and fragmented. In this context, as a Data Augmentation (DA) technique, Generative Adversarial Networks (GANs) can synthesize realistic/diverse additional training images to fill the data lack in the real image distribution; researchers have improved classification by augmenting images with noise-to-image (e.g., random noise samples to diverse pathological images) or image-to-image GANs (e.g., a benign image to a malignant one). Yet, no research has reported results combining (i) noise-to-image GANs and image-to-image GANs or (ii) GANs and other deep generative models, for further performance boost. Therefore, to maximize the DA effect with the GAN combinations, we propose a two-step GAN-based DA that generates and refines brain MR images with/without tumors separately: (i) Progressive Growing of GANs (PGGANs), multi-stage noise-to-image GAN for high-resolution image generation, first generates realistic/diverse 256 x 256 images--even a physician cannot accurately distinguish them from real ones via Visual Turing Test; (ii) UNsupervised Image-to-image Translation or SimGAN, image-to-image GAN combining GANs/Variational AutoEncoders or using a GAN loss for DA, further refines the texture/shape of the PGGAN-generated images similarly to the real ones. We thoroughly investigate CNN-based tumor classification results, also considering the influence of pre-training on ImageNet and discarding weird-looking GAN-generated images. The results show that, when combined with classic DA, our two-step GAN-based DA can significantly outperform the classic DA alone, in tumor detection (i.e., boosting sensitivity from 93.63% to 97.53%) and also in other tasks.
Learning More with Less: GAN-based Medical Image Augmentation
May 07, 2019

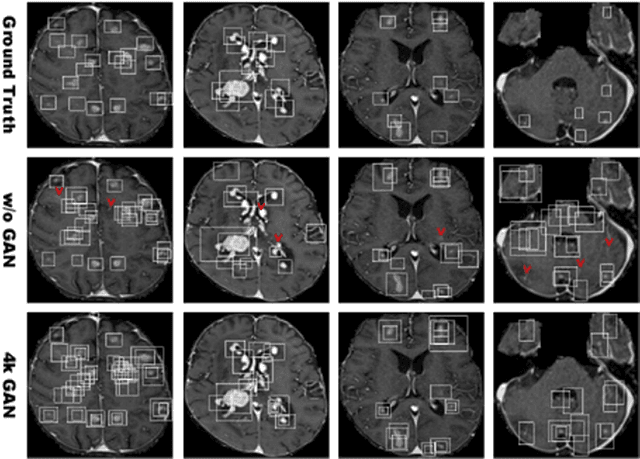
Convolutional Neural Network (CNN)-based accurate prediction typically requires large-scale annotated training data. In Medical Imaging, however, both obtaining medical data and annotating them by expert physicians are challenging; to overcome this lack of data, Data Augmentation (DA) using Generative Adversarial Networks (GANs) is essential, since they can synthesize additional annotated training data to handle small and fragmented medical images from various scanners--those generated images, realistic but completely novel, can further fill the real image distribution uncovered by the original dataset. As a tutorial, this paper introduces GAN-based Medical Image Augmentation, along with tricks to boost classification/object detection/segmentation performance using them, based on our experience and related work. Moreover, we show our first GAN-based DA work using automatic bounding box annotation, for robust CNN-based brain metastases detection on 256 x 256 MR images; GAN-based DA can boost 10% sensitivity in diagnosis with a clinically acceptable number of additional False Positives, even with highly-rough and inconsistent bounding boxes.
USE-Net: incorporating Squeeze-and-Excitation blocks into U-Net for prostate zonal segmentation of multi-institutional MRI datasets
Apr 17, 2019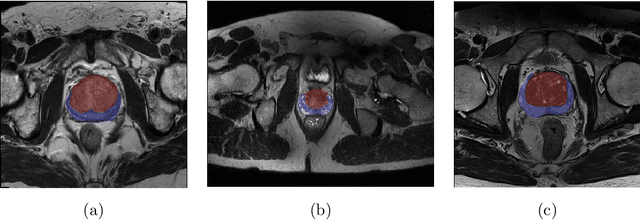
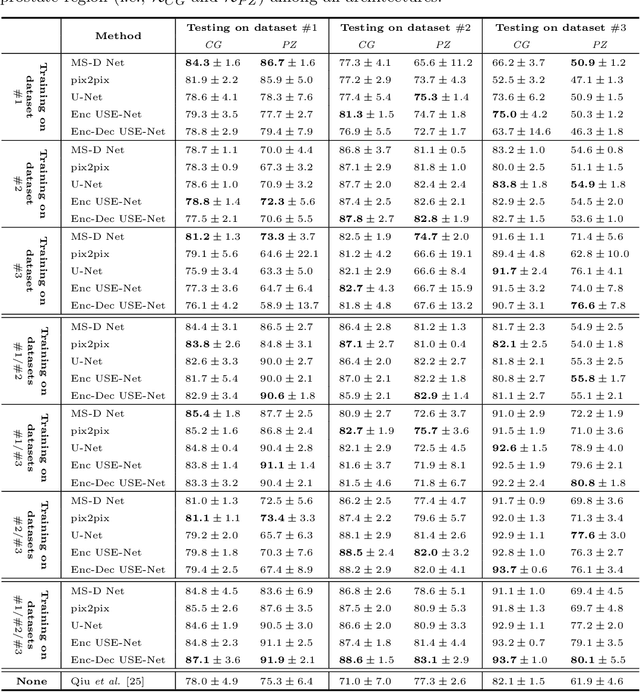
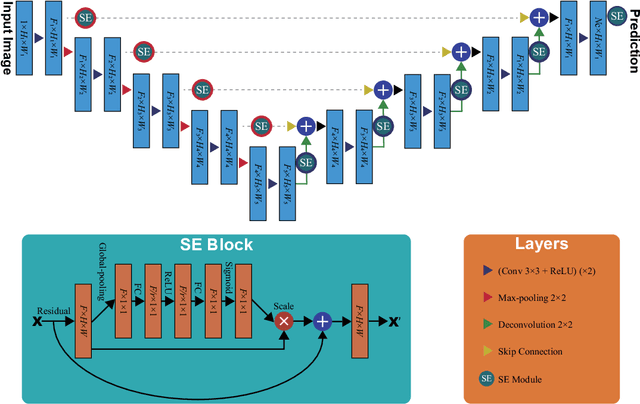
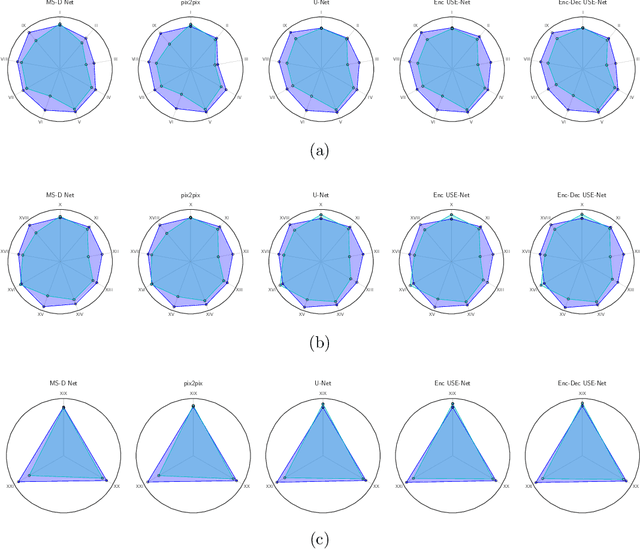
Prostate cancer is the most common malignant tumors in men but prostate Magnetic Resonance Imaging (MRI) analysis remains challenging. Besides whole prostate gland segmentation, the capability to differentiate between the blurry boundary of the Central Gland (CG) and Peripheral Zone (PZ) can lead to differential diagnosis, since tumor's frequency and severity differ in these regions. To tackle the prostate zonal segmentation task, we propose a novel Convolutional Neural Network (CNN), called USE-Net, which incorporates Squeeze-and-Excitation (SE) blocks into U-Net. Especially, the SE blocks are added after every Encoder (Enc USE-Net) or Encoder-Decoder block (Enc-Dec USE-Net). This study evaluates the generalization ability of CNN-based architectures on three T2-weighted MRI datasets, each one consisting of a different number of patients and heterogeneous image characteristics, collected by different institutions. The following mixed scheme is used for training/testing: (i) training on either each individual dataset or multiple prostate MRI datasets and (ii) testing on all three datasets with all possible training/testing combinations. USE-Net is compared against three state-of-the-art CNN-based architectures (i.e., U-Net, pix2pix, and Mixed-Scale Dense Network), along with a semi-automatic continuous max-flow model. The results show that training on the union of the datasets generally outperforms training on each dataset separately, allowing for both intra-/cross-dataset generalization. Enc USE-Net shows good overall generalization under any training condition, while Enc-Dec USE-Net remarkably outperforms the other methods when trained on all datasets. These findings reveal that the SE blocks' adaptive feature recalibration provides excellent cross-dataset generalization when testing is performed on samples of the datasets used during training.
CNN-based Prostate Zonal Segmentation on T2-weighted MR Images: A Cross-dataset Study
Mar 29, 2019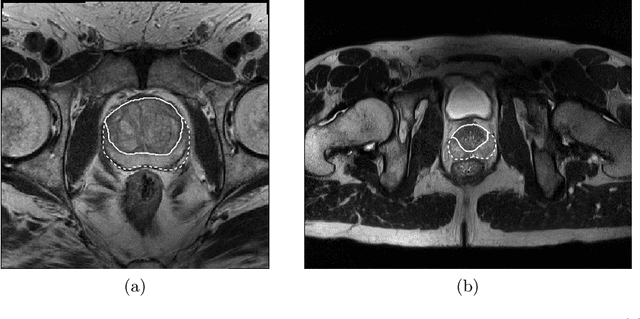
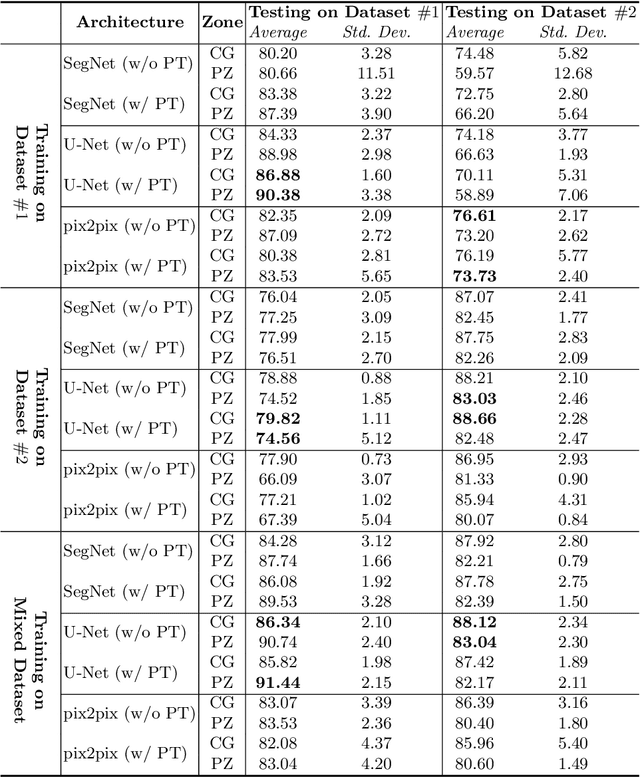
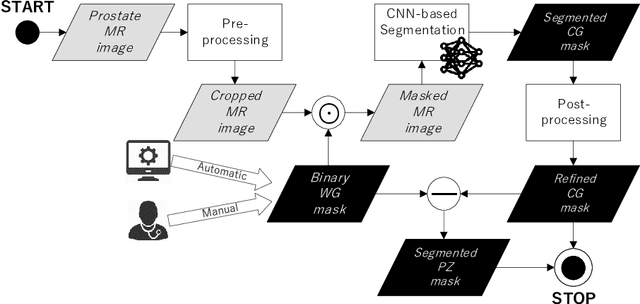
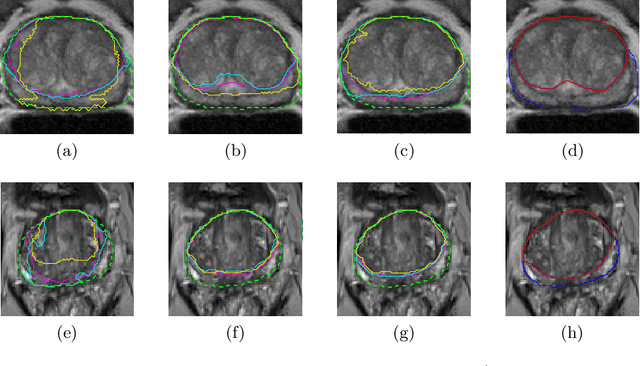
Prostate cancer is the most common cancer among US men. However, prostate imaging is still challenging despite the advances in multi-parametric Magnetic Resonance Imaging (MRI), which provides both morphologic and functional information pertaining to the pathological regions. Along with whole prostate gland segmentation, distinguishing between the Central Gland (CG) and Peripheral Zone (PZ) can guide towards differential diagnosis, since the frequency and severity of tumors differ in these regions; however, their boundary is often weak and fuzzy. This work presents a preliminary study on Deep Learning to automatically delineate the CG and PZ, aiming at evaluating the generalization ability of Convolutional Neural Networks (CNNs) on two multi-centric MRI prostate datasets. Especially, we compared three CNN-based architectures: SegNet, U-Net, and pix2pix. In such a context, the segmentation performances achieved with/without pre-training were compared in 4-fold cross-validation. In general, U-Net outperforms the other methods, especially when training and testing are performed on multiple datasets.
Infinite Brain MR Images: PGGAN-based Data Augmentation for Tumor Detection
Mar 29, 2019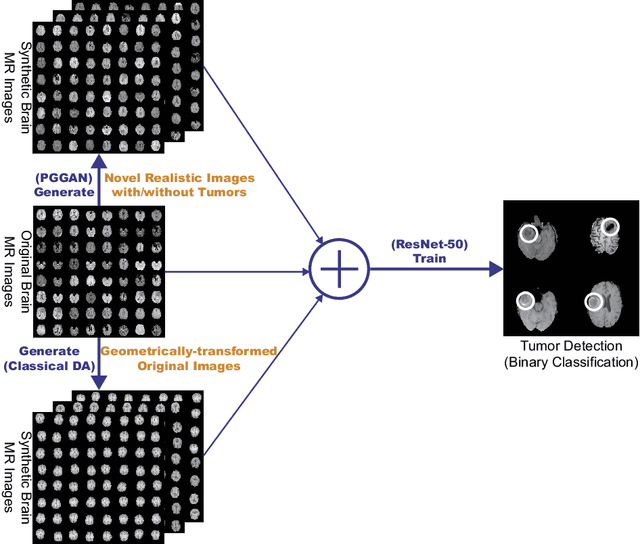

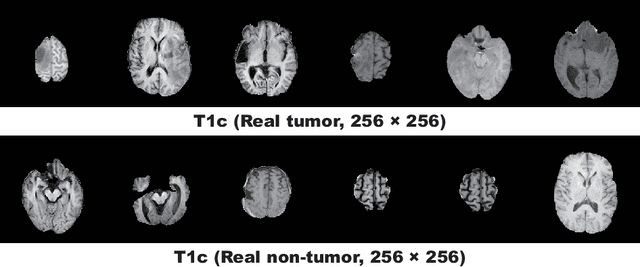
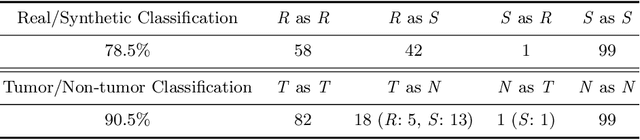
Due to the lack of available annotated medical images, accurate computer-assisted diagnosis requires intensive Data Augmentation (DA) techniques, such as geometric/intensity transformations of original images; however, those transformed images intrinsically have a similar distribution to the original ones, leading to limited performance improvement. To fill the data lack in the real image distribution, we synthesize brain contrast-enhanced Magnetic Resonance (MR) images---realistic but completely different from the original ones---using Generative Adversarial Networks (GANs). This study exploits Progressive Growing of GANs (PGGANs), a multi-stage generative training method, to generate original-sized 256 X 256 MR images for Convolutional Neural Network-based brain tumor detection, which is challenging via conventional GANs; difficulties arise due to unstable GAN training with high resolution and a variety of tumors in size, location, shape, and contrast. Our preliminary results show that this novel PGGAN-based DA method can achieve promising performance improvement, when combined with classical DA, in tumor detection and also in other medical imaging tasks.
Learning More with Less: Conditional PGGAN-based Data Augmentation for Brain Metastases Detection Using Highly-Rough Annotation on MR Images
Mar 03, 2019
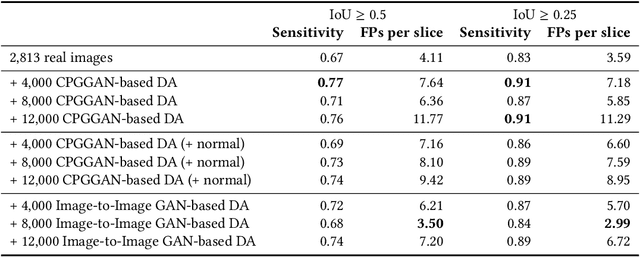

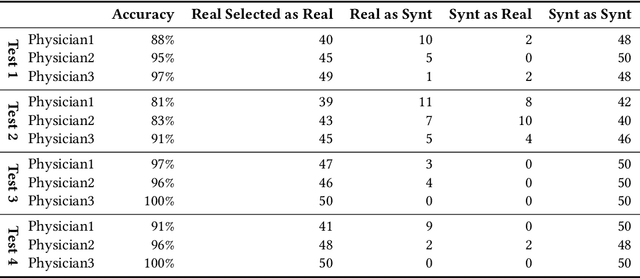
Accurate computer-assisted diagnosis can alleviate the risk of overlooking the diagnosis in a clinical environment. Towards this, as a Data Augmentation (DA) technique, Generative Adversarial Networks (GANs) can synthesize additional training data to handle small/fragmented medical images from various scanners; those images are realistic but completely different from the original ones, filling the data lack in the real image distribution. However, we cannot easily use them to locate the position of disease areas, considering expert physicians' annotation as time-expensive tasks. Therefore, this paper proposes Conditional Progressive Growing of GANs (CPGGANs), incorporating bounding box conditions into PGGANs to place brain metastases at desired position/size on 256 x 256 Magnetic Resonance (MR) images, for Convolutional Neural Network-based tumor detection; this first GAN-based medical DA using automatic bounding box annotation improves the robustness during training. The results show that CPGGAN-based DA can boost 10% sensitivity in diagnosis with an acceptable amount of additional False Positives---even with physicians' highly-rough and inconsistent bounding box annotation. Surprisingly, further realistic tumor appearance, achieved with additional normal brain MR images for CPGGAN training, does not contribute to detection performance, while even three expert physicians cannot accurately distinguish them from the real ones in Visual Turing Test.
Real-time Neural-based Input Method
Oct 19, 2018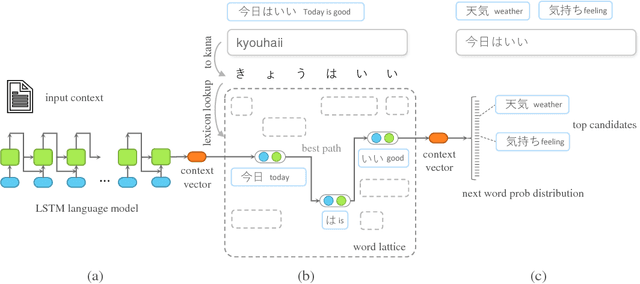
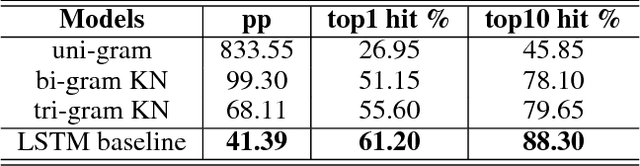
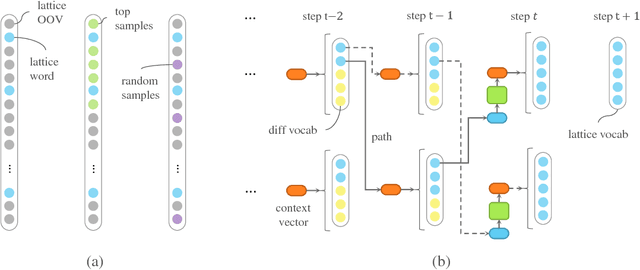
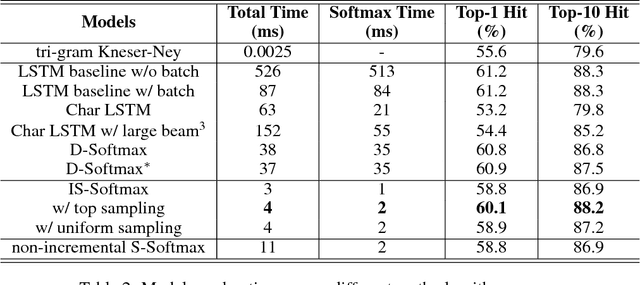
The input method is an essential service on every mobile and desktop devices that provides text suggestions. It converts sequential keyboard inputs to the characters in its target language, which is indispensable for Japanese and Chinese users. Due to critical resource constraints and limited network bandwidth of the target devices, applying neural models to input method is not well explored. In this work, we apply a LSTM-based language model to input method and evaluate its performance for both prediction and conversion tasks with Japanese BCCWJ corpus. We articulate the bottleneck to be the slow softmax computation during conversion. To solve the issue, we propose incremental softmax approximation approach, which computes softmax with a selected subset vocabulary and fix the stale probabilities when the vocabulary is updated in future steps. We refer to this method as incremental selective softmax. The results show a two order speedup for the softmax computation when converting Japanese input sequences with a large vocabulary, reaching real-time speed on commodity CPU. We also exploit the model compressing potential to achieve a 92% model size reduction without losing accuracy.
Semantic Aware Attention Based Deep Object Co-segmentation
Oct 16, 2018

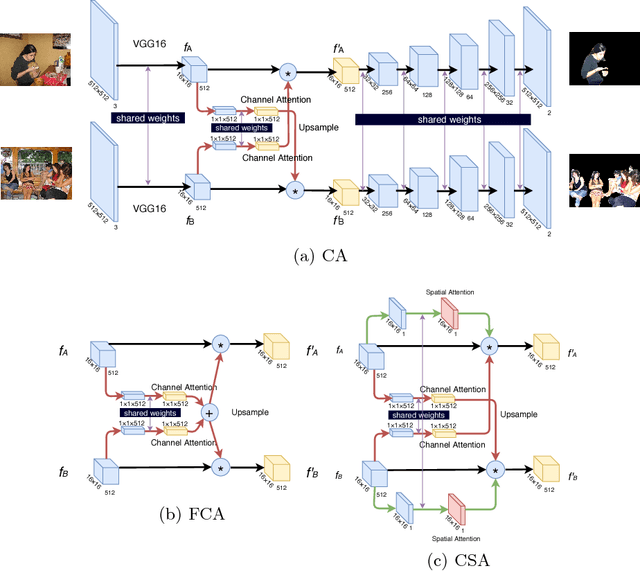
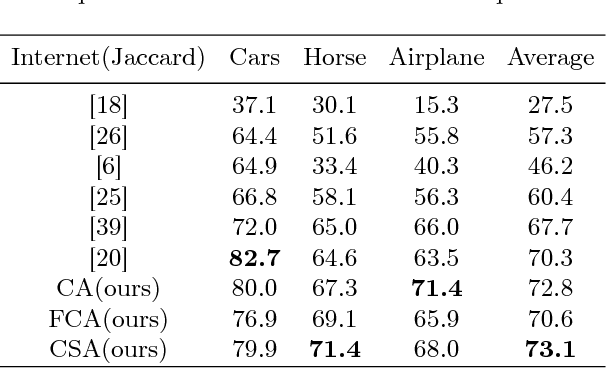
Object co-segmentation is the task of segmenting the same objects from multiple images. In this paper, we propose the Attention Based Object Co-Segmentation for object co-segmentation that utilize a novel attention mechanism in the bottleneck layer of deep neural network for the selection of semantically related features. Furthermore, we take the benefit of attention learner and propose an algorithm to segment multi-input images in linear time complexity. Experiment results demonstrate that our model achieves state of the art performance on multiple datasets, with a significant reduction of computational time.
Discrete Structural Planning for Neural Machine Translation
Aug 14, 2018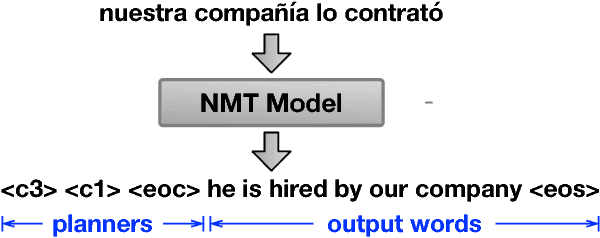
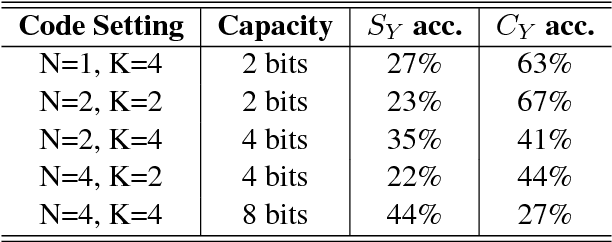
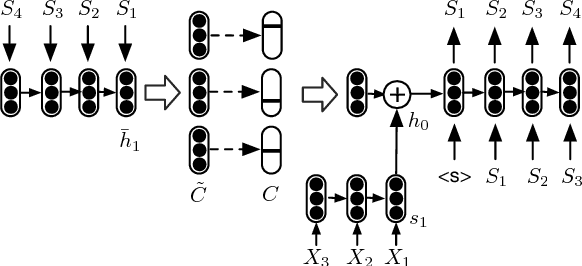
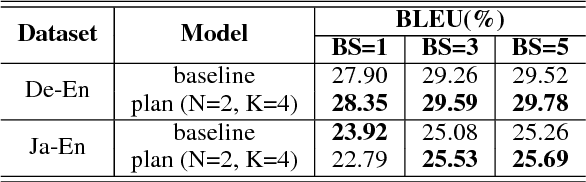
Structural planning is important for producing long sentences, which is a missing part in current language generation models. In this work, we add a planning phase in neural machine translation to control the coarse structure of output sentences. The model first generates some planner codes, then predicts real output words conditioned on them. The codes are learned to capture the coarse structure of the target sentence. In order to obtain the codes, we design an end-to-end neural network with a discretization bottleneck, which predicts the simplified part-of-speech tags of target sentences. Experiments show that the translation performance are generally improved by planning ahead. We also find that translations with different structures can be obtained by manipulating the planner codes.