 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert-Guided POMDP Learning for Data-Efficient Modeling in Healthcare
Nov 18, 2025



Learning the parameters of Partially Observable Markov Decision Processes (POMDPs) from limited data is a significant challenge. We introduce the Fuzzy MAP EM algorithm, a novel approach that incorporates expert knowledge into the parameter estimation process by enriching the Expectation Maximization (EM) framework with fuzzy pseudo-counts derived from an expert-defined fuzzy model. This integration naturally reformulates the problem as a Maximum A Posteriori (MAP) estimation, effectively guiding learning in environments with limited data. In synthetic medical simulations, our method consistently outperforms the standard EM algorithm under both low-data and high-noise conditions. Furthermore, a case study on Myasthenia Gravis illustrates the ability of the Fuzzy MAP EM algorithm to recover a clinically coherent POMDP, demonstrating its potential as a practical tool for data-efficient modeling in healthcare.
USE-Net: incorporating Squeeze-and-Excitation blocks into U-Net for prostate zonal segmentation of multi-institutional MRI datasets
Apr 17, 2019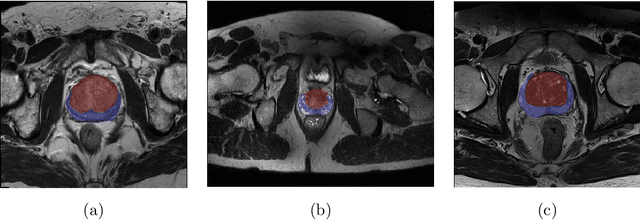
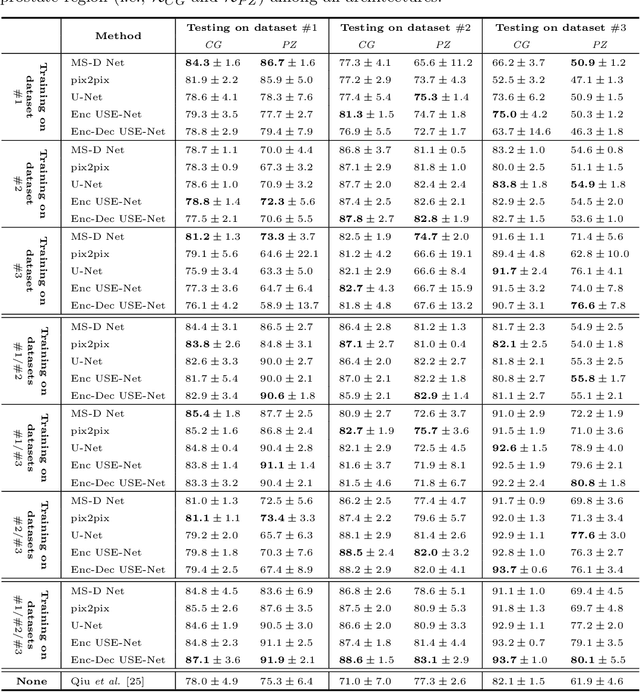
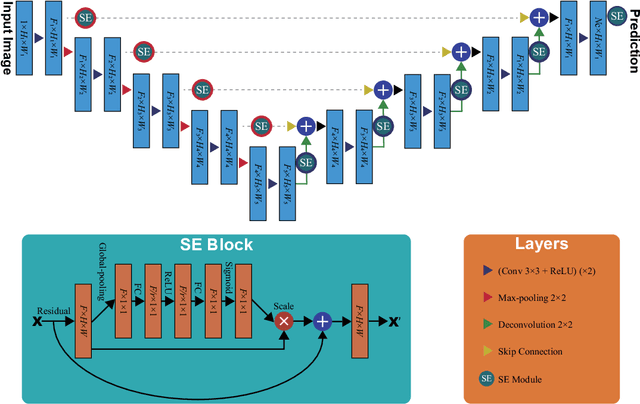
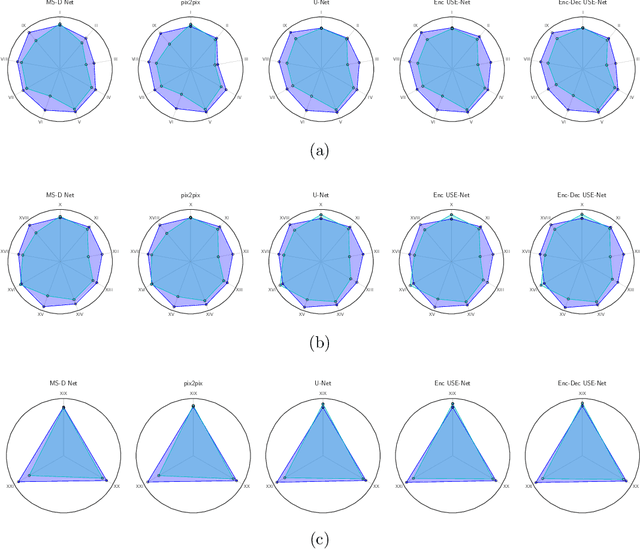
Prostate cancer is the most common malignant tumors in men but prostate Magnetic Resonance Imaging (MRI) analysis remains challenging. Besides whole prostate gland segmentation, the capability to differentiate between the blurry boundary of the Central Gland (CG) and Peripheral Zone (PZ) can lead to differential diagnosis, since tumor's frequency and severity differ in these regions. To tackle the prostate zonal segmentation task, we propose a novel Convolutional Neural Network (CNN), called USE-Net, which incorporates Squeeze-and-Excitation (SE) blocks into U-Net. Especially, the SE blocks are added after every Encoder (Enc USE-Net) or Encoder-Decoder block (Enc-Dec USE-Net). This study evaluates the generalization ability of CNN-based architectures on three T2-weighted MRI datasets, each one consisting of a different number of patients and heterogeneous image characteristics, collected by different institutions. The following mixed scheme is used for training/testing: (i) training on either each individual dataset or multiple prostate MRI datasets and (ii) testing on all three datasets with all possible training/testing combinations. USE-Net is compared against three state-of-the-art CNN-based architectures (i.e., U-Net, pix2pix, and Mixed-Scale Dense Network), along with a semi-automatic continuous max-flow model. The results show that training on the union of the datasets generally outperforms training on each dataset separately, allowing for both intra-/cross-dataset generalization. Enc USE-Net shows good overall generalization under any training condition, while Enc-Dec USE-Net remarkably outperforms the other methods when trained on all datasets. These findings reveal that the SE blocks' adaptive feature recalibration provides excellent cross-dataset generalization when testing is performed on samples of the datasets used during training.