 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Bayesian Optimization
Oct 15, 2023Bayesian Optimization is a popular approach for optimizing expensive black-box functions. Its key idea is to use a surrogate model to approximate the objective and, importantly, quantify the associated uncertainty that allows a sequential search of query points that balance exploitation-exploration. Gaussian process (GP) has been a primary candidate for the surrogate model, thanks to its Bayesian-principled uncertainty quantification power and modeling flexibility. However, its challenges have also spurred an array of alternatives whose convergence properties could be more opaque. Motivated by these, we study in this paper an axiomatic framework that elicits the minimal requirements to guarantee black-box optimization convergence that could apply beyond GP-related methods. Moreover, we leverage the design freedom in our framework, which we call Pseudo-Bayesian Optimization, to construct empirically superior algorithms. In particular, we show how using simple local regression, and a suitable "randomized prior" construction to quantify uncertainty, not only guarantees convergence but also consistently outperforms state-of-the-art benchmarks in examples ranging from high-dimensional synthetic experiments to realistic hyperparameter tuning and robotic applications.
Smoothed $f$-Divergence Distributionally Robust Optimization: Exponential Rate Efficiency and Complexity-Free Calibration
Jun 24, 2023

In data-driven optimization, sample average approximation is known to suffer from the so-called optimizer's curse that causes optimistic bias in evaluating the solution performance. This can be tackled by adding a "margin" to the estimated objective value, or via distributionally robust optimization (DRO), a fast-growing approach based on worst-case analysis, which gives a protective bound on the attained objective value. However, in all these existing approaches, a statistically guaranteed bound on the true solution performance either requires restrictive conditions and knowledge on the objective function complexity, or otherwise exhibits an over-conservative rate that depends on the distribution dimension. We argue that a special type of DRO offers strong theoretical advantages in regard to these challenges: It attains a statistical bound on the true solution performance that is the tightest possible in terms of exponential decay rate, for a wide class of objective functions that notably does not hinge on function complexity. Correspondingly, its calibration also does not require any complexity information. This DRO uses an ambiguity set based on a KL-divergence smoothed by the Wasserstein or Levy-Prokhorov distance via a suitable distance optimization. Computationally, we also show that such a DRO, and its generalized version using smoothed $f$-divergence, is not much harder than standard DRO problems using the $f$-divergence or Wasserstein distance, thus supporting the strengths of such DRO as both statistically optimal and computationally viable.
Optimizer's Information Criterion: Dissecting and Correcting Bias in Data-Driven Optimization
Jun 16, 2023In data-driven optimization, the sample performance of the obtained decision typically incurs an optimistic bias against the true performance, a phenomenon commonly known as the Optimizer's Curse and intimately related to overfitting in machine learning. Common techniques to correct this bias, such as cross-validation, require repeatedly solving additional optimization problems and are therefore computationally expensive. We develop a general bias correction approach, building on what we call Optimizer's Information Criterion (OIC), that directly approximates the first-order bias and does not require solving any additional optimization problems. Our OIC generalizes the celebrated Akaike Information Criterion to evaluate the objective performance in data-driven optimization, which crucially involves not only model fitting but also its interplay with the downstream optimization. As such it can be used for decision selection instead of only model selection. We apply our approach to a range of data-driven optimization formulations comprising empirical and parametric models, their regularized counterparts, and furthermore contextual optimization. Finally, we provide numerical validation on the superior performance of our approach under synthetic and real-world datasets.
Efficient Uncertainty Quantification and Reduction for Over-Parameterized Neural Networks
Jun 09, 2023



Uncertainty quantification (UQ) is important for reliability assessment and enhancement of machine learning models. In deep learning, uncertainties arise not only from data, but also from the training procedure that often injects substantial noises and biases. These hinder the attainment of statistical guarantees and, moreover, impose computational challenges on UQ due to the need for repeated network retraining. Building upon the recent neural tangent kernel theory, we create statistically guaranteed schemes to principally \emph{quantify}, and \emph{remove}, the procedural uncertainty of over-parameterized neural networks with very low computation effort. In particular, our approach, based on what we call a procedural-noise-correcting (PNC) predictor, removes the procedural uncertainty by using only \emph{one} auxiliary network that is trained on a suitably labeled data set, instead of many retrained networks employed in deep ensembles. Moreover, by combining our PNC predictor with suitable light-computation resampling methods, we build several approaches to construct asymptotically exact-coverage confidence intervals using as low as four trained networks without additional overheads.
Short-term Temporal Dependency Detection under Heterogeneous Event Dynamic with Hawkes Processes
May 28, 2023



Many event sequence data exhibit mutually exciting or inhibiting patterns. Reliable detection of such temporal dependency is crucial for scientific investigation. The de facto model is the Multivariate Hawkes Process (MHP), whose impact function naturally encodes a causal structure in Granger causality. However, the vast majority of existing methods use direct or nonlinear transform of standard MHP intensity with constant baseline, inconsistent with real-world data. Under irregular and unknown heterogeneous intensity, capturing temporal dependency is hard as one struggles to distinguish the effect of mutual interaction from that of intensity fluctuation. In this paper, we address the short-term temporal dependency detection issue. We show the maximum likelihood estimation (MLE) for cross-impact from MHP has an error that can not be eliminated but may be reduced by order of magnitude, using heterogeneous intensity not of the target HP but of the interacting HP. Then we proposed a robust and computationally-efficient method modified from MLE that does not rely on the prior estimation of the heterogeneous intensity and is thus applicable in a data-limited regime (e.g., few-shot, no repeated observations). Extensive experiments on various datasets show that our method outperforms existing ones by notable margins, with highlighted novel applications in neuroscience.
Estimate-Then-Optimize Versus Integrated-Estimation-Optimization: A Stochastic Dominance Perspective
Apr 13, 2023



In data-driven stochastic optimization, model parameters of the underlying distribution need to be estimated from data in addition to the optimization task. Recent literature suggests the integration of the estimation and optimization processes, by selecting model parameters that lead to the best empirical objective performance. Such an integrated approach can be readily shown to outperform simple ``estimate then optimize" when the model is misspecified. In this paper, we argue that when the model class is rich enough to cover the ground truth, the performance ordering between the two approaches is reversed for nonlinear problems in a strong sense. Simple ``estimate then optimize" outperforms the integrated approach in terms of stochastic dominance of the asymptotic optimality gap, i,e, the mean, all other moments, and the entire asymptotic distribution of the optimality gap is always better. Analogous results also hold under constrained settings and when contextual features are available. We also provide experimental findings to support our theory.
Hedging against Complexity: Distributionally Robust Optimization with Parametric Approximation
Dec 03, 2022Empirical risk minimization (ERM) and distributionally robust optimization (DRO) are popular approaches for solving stochastic optimization problems that appear in operations management and machine learning. Existing generalization error bounds for these methods depend on either the complexity of the cost function or dimension of the uncertain parameters; consequently, the performance of these methods is poor for high-dimensional problems with objective functions under high complexity. We propose a simple approach in which the distribution of uncertain parameters is approximated using a parametric family of distributions. This mitigates both sources of complexity; however, it introduces a model misspecification error. We show that this new source of error can be controlled by suitable DRO formulations. Our proposed parametric DRO approach has significantly improved generalization bounds over existing ERM / DRO methods and parametric ERM for a wide variety of settings. Our method is particularly effective under distribution shifts. We also illustrate the superior performance of our approach on both synthetic and real-data portfolio optimization and regression tasks.
Evaluating Aleatoric Uncertainty via Conditional Generative Models
Jun 09, 2022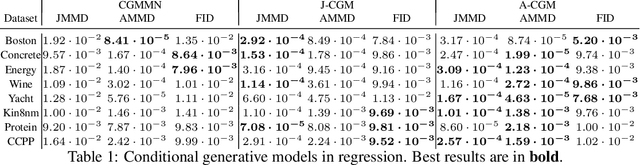

Aleatoric uncertainty quantification seeks for distributional knowledge of random responses, which is important for reliability analysis and robustness improvement in machine learning applications. Previous research on aleatoric uncertainty estimation mainly targets closed-formed conditional densities or variances, which requires strong restrictions on the data distribution or dimensionality. To overcome these restrictions, we study conditional generative models for aleatoric uncertainty estimation. We introduce two metrics to measure the discrepancy between two conditional distributions that suit these models. Both metrics can be easily and unbiasedly computed via Monte Carlo simulation of the conditional generative models, thus facilitating their evaluation and training. We demonstrate numerically how our metrics provide correct measurements of conditional distributional discrepancies and can be used to train conditional models competitive against existing benchmarks.
Test Against High-Dimensional Uncertainties: Accelerated Evaluation of Autonomous Vehicles with Deep Importance Sampling
Apr 06, 2022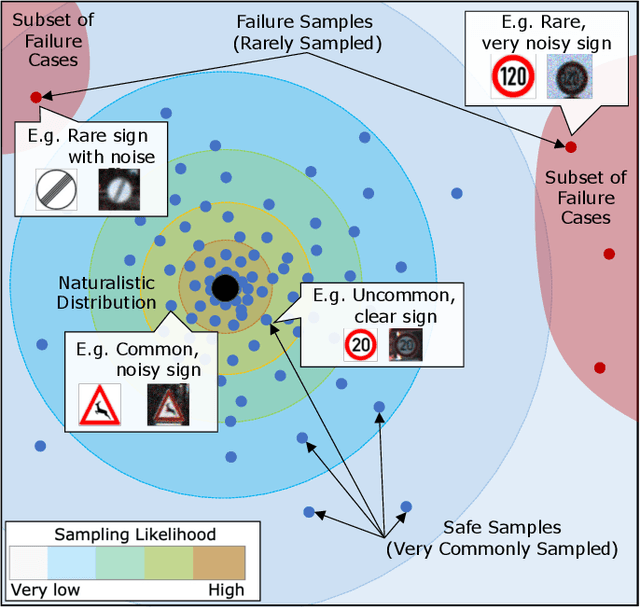


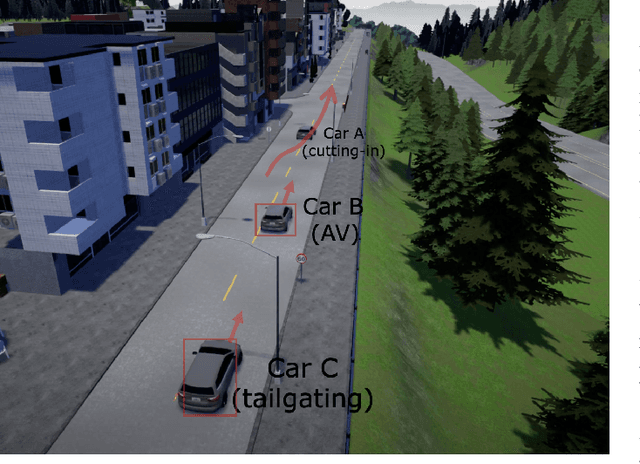
Evaluating the performance of autonomous vehicles (AV) and their complex subsystems to high precision under naturalistic circumstances remains a challenge, especially when failure or dangerous cases are rare. Rarity does not only require an enormous sample size for a naive method to achieve high confidence estimation, but it also causes dangerous underestimation of the true failure rate and it is extremely hard to detect. Meanwhile, the state-of-the-art approach that comes with a correctness guarantee can only compute an upper bound for the failure rate under certain conditions, which could limit its practical uses. In this work, we present Deep Importance Sampling (Deep IS) framework that utilizes a deep neural network to obtain an efficient IS that is on par with the state-of-the-art, capable of reducing the required sample size 43 times smaller than the naive sampling method to achieve 10% relative error and while producing an estimate that is much less conservative. Our high-dimensional experiment estimating the misclassification rate of one of the state-of-the-art traffic sign classifiers further reveals that this efficiency still holds true even when the target is very small, achieving over 600 times efficiency boost. This highlights the potential of Deep IS in providing a precise estimate even against high-dimensional uncertainties.
Generalized Bayesian Upper Confidence Bound with Approximate Inference for Bandit Problems
Jan 31, 2022



Bayesian bandit algorithms with approximate inference have been widely used in practice with superior performance. Yet, few studies regarding the fundamental understanding of their performances are available. In this paper, we propose a Bayesian bandit algorithm, which we call Generalized Bayesian Upper Confidence Bound (GBUCB), for bandit problems in the presence of approximate inference. Our theoretical analysis demonstrates that in Bernoulli multi-armed bandit, GBUCB can achieve $O(\sqrt{T}(\log T)^c)$ frequentist regret if the inference error measured by symmetrized Kullback-Leibler divergence is controllable. This analysis relies on a novel sensitivity analysis for quantile shifts with respect to inference errors. To our best knowledge, our work provides the first theoretical regret bound that is better than $o(T)$ in the setting of approximate inference. Our experimental evaluations on multiple approximate inference settings corroborate our theory, showing that our GBUCB is consistently superior to BUCB and Thompson sampling.