 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Capture from Pan-Tilt Cameras with Unknown Orientation
Aug 30, 2019
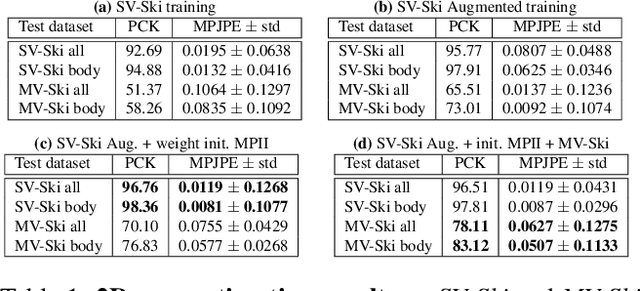
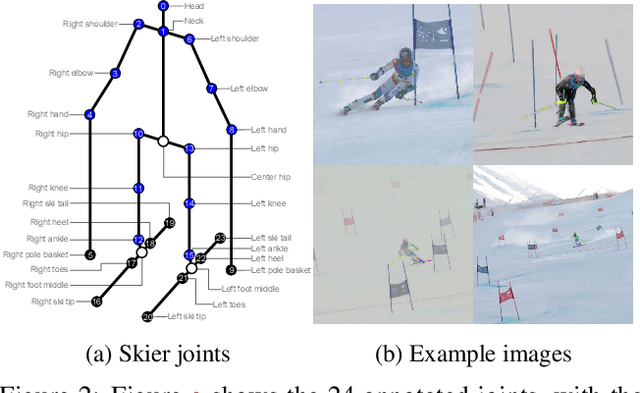
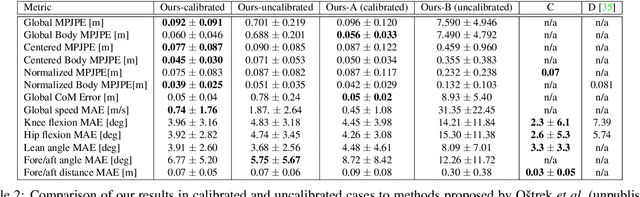
In sports, such as alpine skiing, coaches would like to know the speed and various biomechanical variables of their athletes and competitors. Existing methods use either body-worn sensors, which are cumbersome to setup, or manual image annotation, which is time consuming. We propose a method for estimating an athlete's global 3D position and articulated pose using multiple cameras. By contrast to classical markerless motion capture solutions, we allow cameras to rotate freely so that large capture volumes can be covered. In a first step, tight crops around the skier are predicted and fed to a 2D pose estimator network. The 3D pose is then reconstructed using a bundle adjustment method. Key to our solution is the rotation estimation of Pan-Tilt cameras in a joint optimization with the athlete pose and conditioning on relative background motion computed with feature tracking. Furthermore, we created a new alpine skiing dataset and annotated it with 2D pose labels, to overcome shortcomings of existing ones. Our method estimates accurate global 3D poses from images only and provides coaches with an automatic and fast tool for measuring and improving an athlete's performance.
Self-supervised Training of Proposal-based Segmentation via Background Prediction
Jul 18, 2019

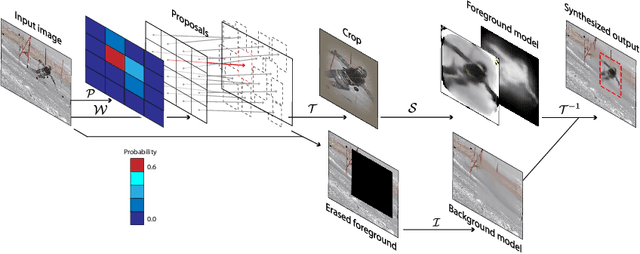
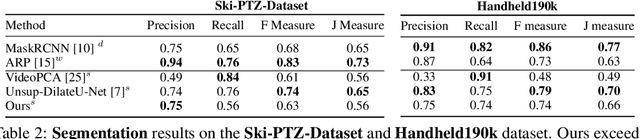
While supervised object detection methods achieve impressive accuracy, they generalize poorly to images whose appearance significantly differs from the data they have been trained on. To address this in scenarios where annotating data is prohibitively expensive, we introduce a self-supervised approach to object detection and segmentation, able to work with monocular images captured with a moving camera. At the heart of our approach lies the observation that segmentation and background reconstruction are linked tasks, and the idea that, because we observe a structured scene, background regions can be re-synthesized from their surroundings, whereas regions depicting the object cannot. We therefore encode this intuition as a self-supervised loss function that we exploit to train a proposal-based segmentation network. To account for the discrete nature of object proposals, we develop a Monte Carlo-based training strategy that allows us to explore the large space of object proposals. Our experiments demonstrate that our approach yields accurate detections and segmentations in images that visually depart from those of standard benchmarks, outperforming existing self-supervised methods and approaching weakly supervised ones that exploit large annotated datasets.
XNect: Real-time Multi-person 3D Human Pose Estimation with a Single RGB Camera
Jul 01, 2019
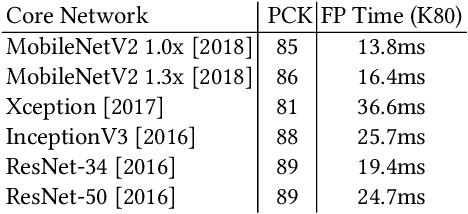
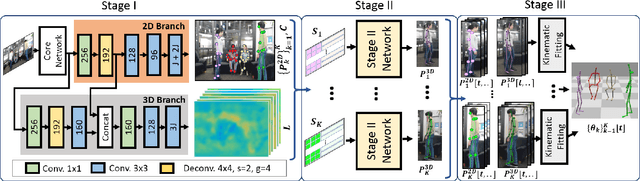
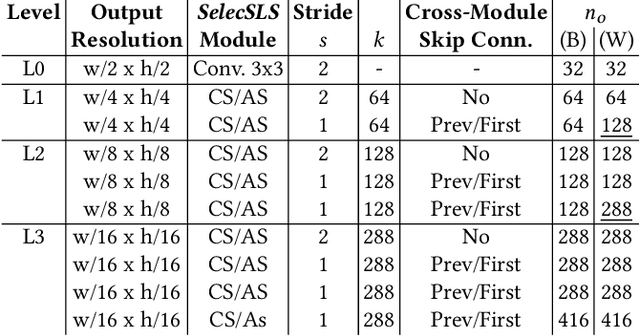
We present a real-time approach for multi-person 3D motion capture at over 30 fps using a single RGB camera. It operates in generic scenes and is robust to difficult occlusions both by other people and objects. Our method operates in subsequent stages. The first stage is a convolutional neural network (CNN) that estimates 2D and 3D pose features along with identity assignments for all visible joints of all individuals. We contribute a new architecture for this CNN, called SelecSLS Net, that uses novel selective long and short range skip connections to improve the information flow allowing for a drastically faster network without compromising accuracy. In the second stage, a fully-connected neural network turns the possibly partial (on account of occlusion) 2D pose and 3D pose features for each subject into a complete 3D pose estimate per individual. The third stage applies space-time skeletal model fitting to the predicted 2D and 3D pose per subject to further reconcile the 2D and 3D pose, and enforce temporal coherence. Our method returns the full skeletal pose in joint angles for each subject. This is a further key distinction from previous work that neither extracted global body positions nor joint angle results of a coherent skeleton in real time for multi-person scenes. The proposed system runs on consumer hardware at a previously unseen speed of more than 30 fps given 512x320 images as input while achieving state-of-the-art accuracy, which we will demonstrate on a range of challenging real-world scenes.
Neural Scene Decomposition for Multi-Person Motion Capture
Mar 13, 2019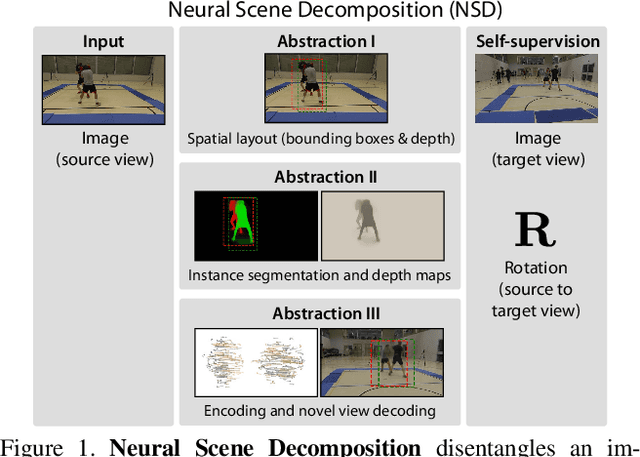
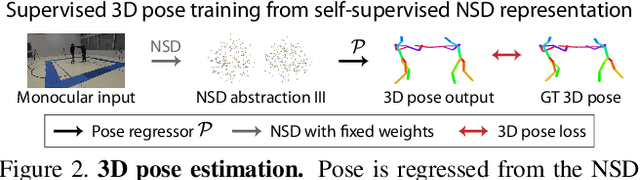
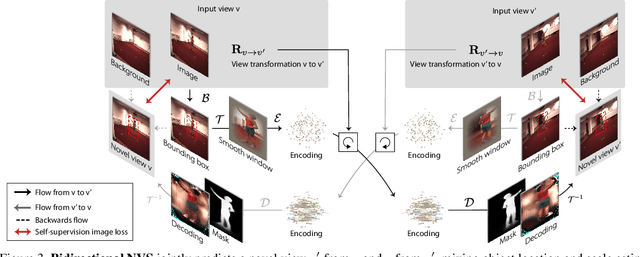

Learning general image representations has proven key to the success of many computer vision tasks. For example, many approaches to image understanding problems rely on deep networks that were initially trained on ImageNet, mostly because the learned features are a valuable starting point to learn from limited labeled data. However, when it comes to 3D motion capture of multiple people, these features are only of limited use. In this paper, we therefore propose an approach to learning features that are useful for this purpose. To this end, we introduce a self-supervised approach to learning what we call a neural scene decomposition (NSD) that can be exploited for 3D pose estimation. NSD comprises three layers of abstraction to represent human subjects: spatial layout in terms of bounding-boxes and relative depth; a 2D shape representation in terms of an instance segmentation mask; and subject-specific appearance and 3D pose information. By exploiting self-supervision coming from multiview data, our NSD model can be trained end-to-end without any 2D or 3D supervision. In contrast to previous approaches, it works for multiple persons and full-frame images. Because it encodes 3D geometry, NSD can then be effectively leveraged to train a 3D pose estimation network from small amounts of annotated data.
What Face and Body Shapes Can Tell About Height
May 25, 2018


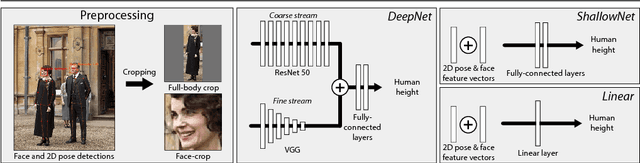
Recovering a person's height from a single image is important for virtual garment fitting, autonomous driving and surveillance, however, it is also very challenging due to the absence of absolute scale information. We tackle the rarely addressed case, where camera parameters and scene geometry is unknown. To nevertheless resolve the inherent scale ambiguity, we infer height from statistics that are intrinsic to human anatomy and can be estimated from images directly, such as articulated pose, bone length proportions, and facial features. Our contribution is twofold. First, we experiment with different machine learning models to capture the relation between image content and human height. Second, we show that performance is predominantly limited by dataset size and create a new dataset that is three magnitudes larger, by mining explicit height labels and propagating them to additional images through face recognition and assignment consistency. Our evaluation shows that monocular height estimation is possible with a MAE of 5.56cm.
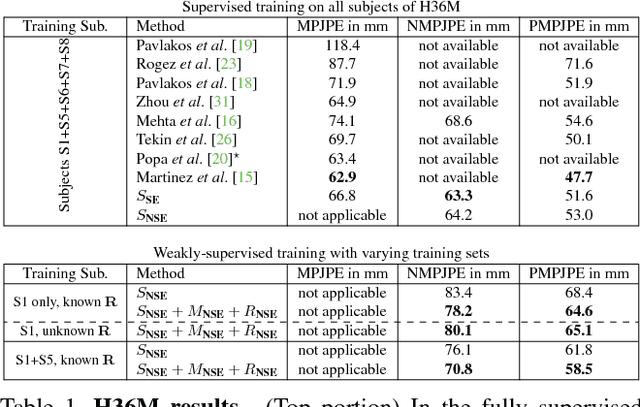
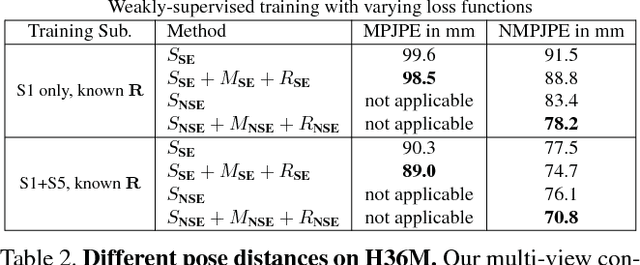
Unsupervised Geometry-Aware Representation for 3D Human Pose Estimation
Apr 03, 2018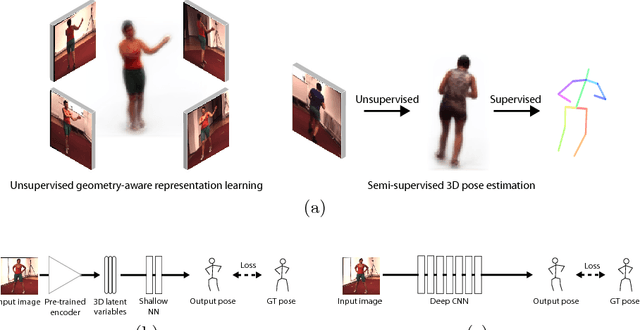

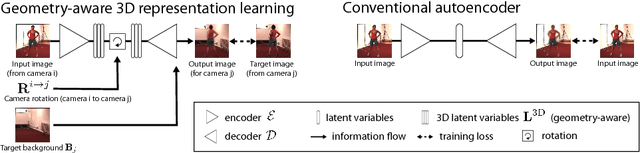

Modern 3D human pose estimation techniques rely on deep networks, which require large amounts of training data. While weakly-supervised methods require less supervision, by utilizing 2D poses or multi-view imagery without annotations, they still need a sufficiently large set of samples with 3D annotations for learning to succeed. In this paper, we propose to overcome this problem by learning a geometry-aware body representation from multi-view images without annotations. To this end, we use an encoder-decoder that predicts an image from one viewpoint given an image from another viewpoint. Because this representation encodes 3D geometry, using it in a semi-supervised setting makes it easier to learn a mapping from it to 3D human pose. As evidenced by our experiments, our approach significantly outperforms fully-supervised methods given the same amount of labeled data, and improves over other semi-supervised methods while using as little as 1% of the labeled data.
Learning Monocular 3D Human Pose Estimation from Multi-view Images
Mar 24, 2018

Accurate 3D human pose estimation from single images is possible with sophisticated deep-net architectures that have been trained on very large datasets. However, this still leaves open the problem of capturing motions for which no such database exists. Manual annotation is tedious, slow, and error-prone. In this paper, we propose to replace most of the annotations by the use of multiple views, at training time only. Specifically, we train the system to predict the same pose in all views. Such a consistency constraint is necessary but not sufficient to predict accurate poses. We therefore complement it with a supervised loss aiming to predict the correct pose in a small set of labeled images, and with a regularization term that penalizes drift from initial predictions. Furthermore, we propose a method to estimate camera pose jointly with human pose, which lets us utilize multi-view footage where calibration is difficult, e.g., for pan-tilt or moving handheld cameras. We demonstrate the effectiveness of our approach on established benchmarks, as well as on a new Ski dataset with rotating cameras and expert ski motion, for which annotations are truly hard to obtain.
Mo2Cap2: Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera
Mar 15, 2018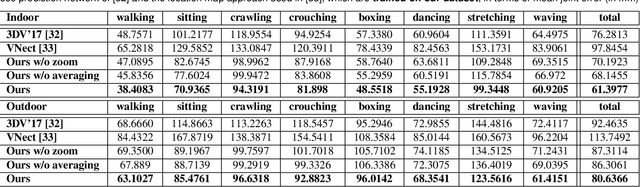


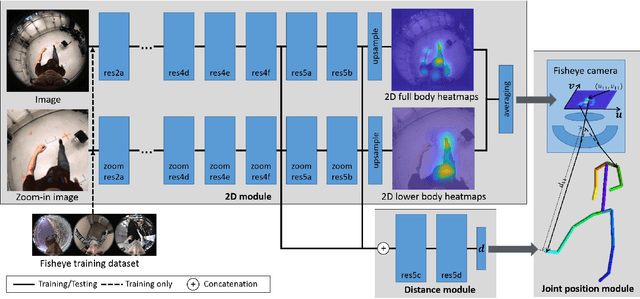
We propose the first real-time approach for the egocentric estimation of 3D human body pose in a wide range of unconstrained everyday activities. This setting has a unique set of challenges, such as mobility of the hardware setup, and robustness to long capture sessions with fast recovery from tracking failures. We tackle these challenges based on a novel lightweight setup that converts a standard baseball cap to a device for high-quality pose estimation based on a single cap-mounted fisheye camera. From the captured egocentric live stream, our CNN based 3D pose estimation approach runs at 60Hz on a consumer-level GPU. In addition to the novel hardware setup, our other main contributions are: 1) a large ground truth training corpus of top-down fisheye images and 2) a novel disentangled 3D pose estimation approach that takes the unique properties of the egocentric viewpoint into account. As shown by our evaluation, we achieve lower 3D joint error as well as better 2D overlay than the existing baselines.
MonoPerfCap: Human Performance Capture from Monocular Video
Feb 23, 2018

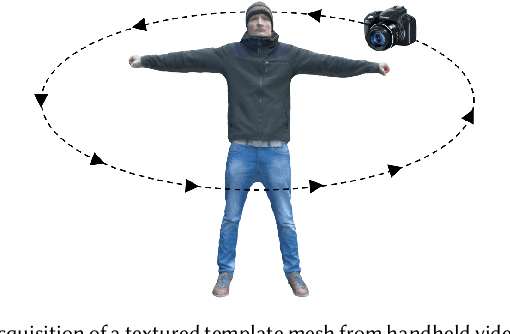
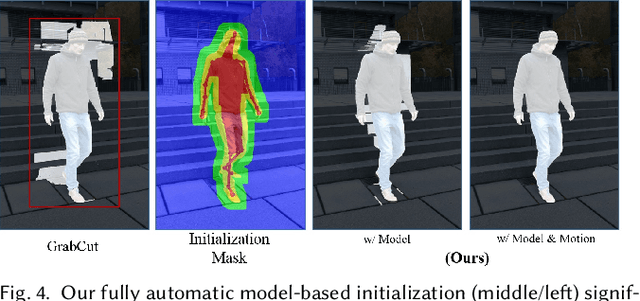
We present the first marker-less approach for temporally coherent 3D performance capture of a human with general clothing from monocular video. Our approach reconstructs articulated human skeleton motion as well as medium-scale non-rigid surface deformations in general scenes. Human performance capture is a challenging problem due to the large range of articulation, potentially fast motion, and considerable non-rigid deformations, even from multi-view data. Reconstruction from monocular video alone is drastically more challenging, since strong occlusions and the inherent depth ambiguity lead to a highly ill-posed reconstruction problem. We tackle these challenges by a novel approach that employs sparse 2D and 3D human pose detections from a convolutional neural network using a batch-based pose estimation strategy. Joint recovery of per-batch motion allows to resolve the ambiguities of the monocular reconstruction problem based on a low dimensional trajectory subspace. In addition, we propose refinement of the surface geometry based on fully automatically extracted silhouettes to enable medium-scale non-rigid alignment. We demonstrate state-of-the-art performance capture results that enable exciting applications such as video editing and free viewpoint video, previously infeasible from monocular video. Our qualitative and quantitative evaluation demonstrates that our approach significantly outperforms previous monocular methods in terms of accuracy, robustness and scene complexity that can be handled.
Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision
Oct 04, 2017
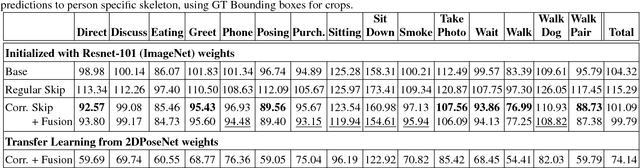
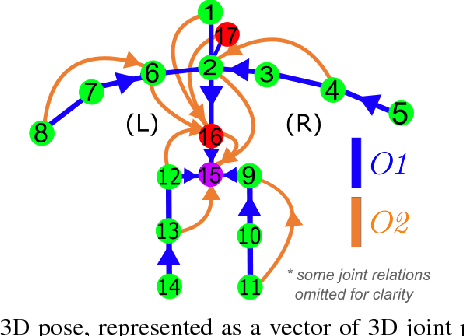
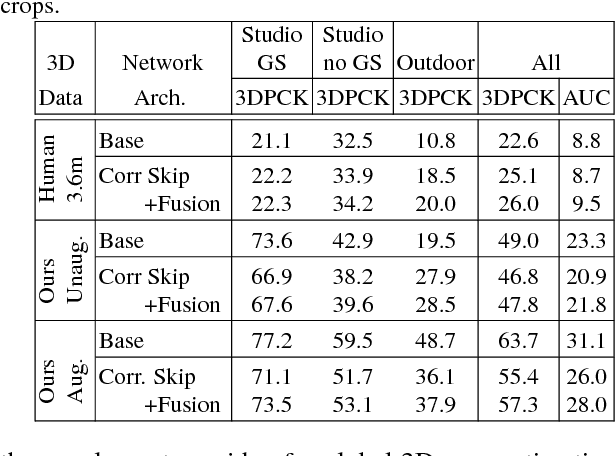
We propose a CNN-based approach for 3D human body pose estimation from single RGB images that addresses the issue of limited generalizability of models trained solely on the starkly limited publicly available 3D pose data. Using only the existing 3D pose data and 2D pose data, we show state-of-the-art performance on established benchmarks through transfer of learned features, while also generalizing to in-the-wild scenes. We further introduce a new training set for human body pose estimation from monocular images of real humans that has the ground truth captured with a multi-camera marker-less motion capture system. It complements existing corpora with greater diversity in pose, human appearance, clothing, occlusion, and viewpoints, and enables an increased scope of augmentation. We also contribute a new benchmark that covers outdoor and indoor scenes, and demonstrate that our 3D pose dataset shows better in-the-wild performance than existing annotated data, which is further improved in conjunction with transfer learning from 2D pose data. All in all, we argue that the use of transfer learning of representations in tandem with algorithmic and data contributions is crucial for general 3D body pose estimation.