 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Representation and Dependency Learning for Multi-Label Image Recognition
Apr 08, 2022
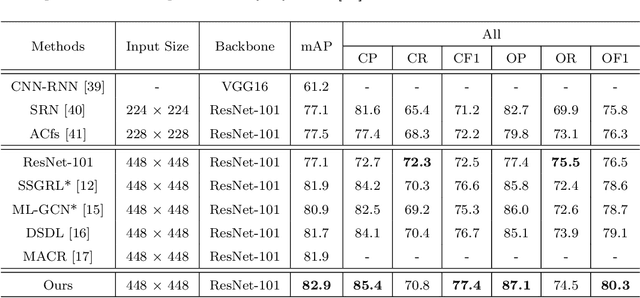
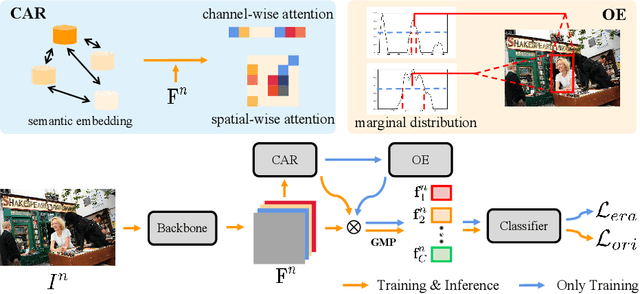
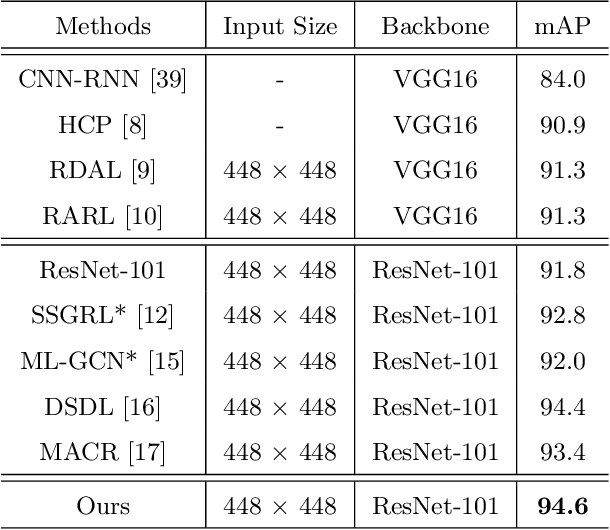
Recently many multi-label image recognition (MLR) works have made significant progress by introducing pre-trained object detection models to generate lots of proposals or utilizing statistical label co-occurrence enhance the correlation among different categories. However, these works have some limitations: (1) the effectiveness of the network significantly depends on pre-trained object detection models that bring expensive and unaffordable computation; (2) the network performance degrades when there exist occasional co-occurrence objects in images, especially for the rare categories. To address these problems, we propose a novel and effective semantic representation and dependency learning (SRDL) framework to learn category-specific semantic representation for each category and capture semantic dependency among all categories. Specifically, we design a category-specific attentional regions (CAR) module to generate channel/spatial-wise attention matrices to guide model to focus on semantic-aware regions. We also design an object erasing (OE) module to implicitly learn semantic dependency among categories by erasing semantic-aware regions to regularize the network training. Extensive experiments and comparisons on two popular MLR benchmark datasets (i.e., MS-COCO and Pascal VOC 2007) demonstrate the effectiveness of the proposed framework over current state-of-the-art algorithms.
Semantic-Aware Representation Blending for Multi-Label Image Recognition with Partial Labels
Mar 04, 2022
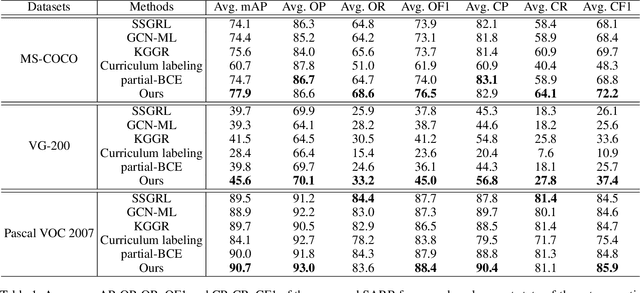
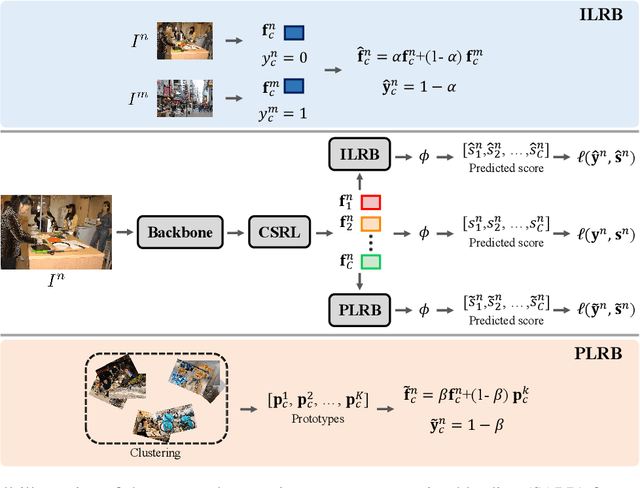
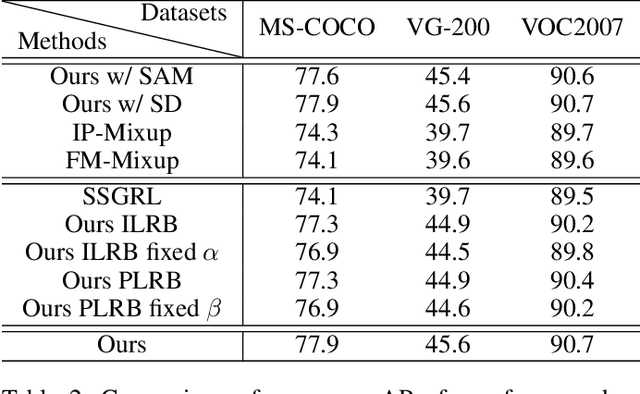
Training the multi-label image recognition models with partial labels, in which merely some labels are known while others are unknown for each image, is a considerably challenging and practical task. To address this task, current algorithms mainly depend on pre-training classification or similarity models to generate pseudo labels for the unknown labels. However, these algorithms depend on sufficient multi-label annotations to train the models, leading to poor performance especially with low known label proportion. In this work, we propose to blend category-specific representation across different images to transfer information of known labels to complement unknown labels, which can get rid of pre-training models and thus does not depend on sufficient annotations. To this end, we design a unified semantic-aware representation blending (SARB) framework that exploits instance-level and prototype-level semantic representation to complement unknown labels by two complementary modules: 1) an instance-level representation blending (ILRB) module blends the representations of the known labels in an image to the representations of the unknown labels in another image to complement these unknown labels. 2) a prototype-level representation blending (PLRB) module learns more stable representation prototypes for each category and blends the representation of unknown labels with the prototypes of corresponding labels to complement these labels. Extensive experiments on the MS-COCO, Visual Genome, Pascal VOC 2007 datasets show that the proposed SARB framework obtains superior performance over current leading competitors on all known label proportion settings, i.e., with the mAP improvement of 4.6%, 4.%, 2.2% on these three datasets when the known label proportion is 10%. Codes are available at https://github.com/HCPLab-SYSU/HCP-MLR-PL.
Structured Semantic Transfer for Multi-Label Recognition with Partial Labels
Dec 22, 2021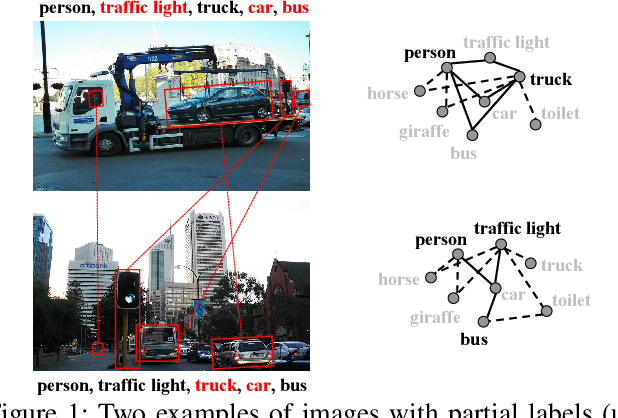
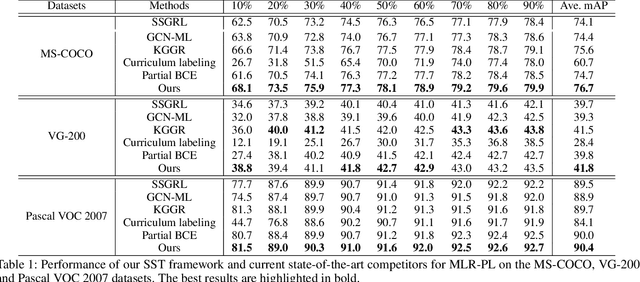
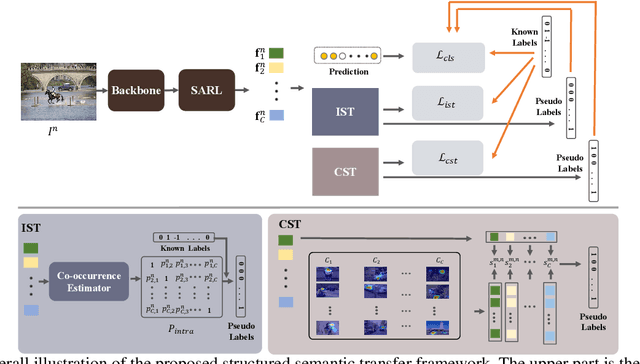
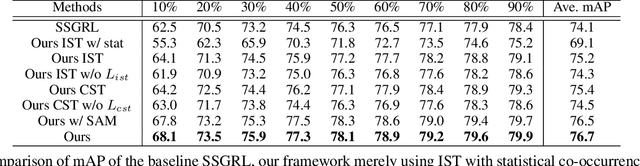
Multi-label image recognition is a fundamental yet practical task because real-world images inherently possess multiple semantic labels. However, it is difficult to collect large-scale multi-label annotations due to the complexity of both the input images and output label spaces. To reduce the annotation cost, we propose a structured semantic transfer (SST) framework that enables training multi-label recognition models with partial labels, i.e., merely some labels are known while other labels are missing (also called unknown labels) per image. The framework consists of two complementary transfer modules that explore within-image and cross-image semantic correlations to transfer knowledge of known labels to generate pseudo labels for unknown labels. Specifically, an intra-image semantic transfer module learns image-specific label co-occurrence matrix and maps the known labels to complement unknown labels based on this matrix. Meanwhile, a cross-image transfer module learns category-specific feature similarities and helps complement unknown labels with high similarities. Finally, both known and generated labels are used to train the multi-label recognition models. Extensive experiments on the Microsoft COCO, Visual Genome and Pascal VOC datasets show that the proposed SST framework obtains superior performance over current state-of-the-art algorithms. Codes are available at https://github.com/HCPLab-SYSU/HCP-MLR-PL.
AU-Expression Knowledge Constrained Representation Learning for Facial Expression Recognition
Dec 29, 2020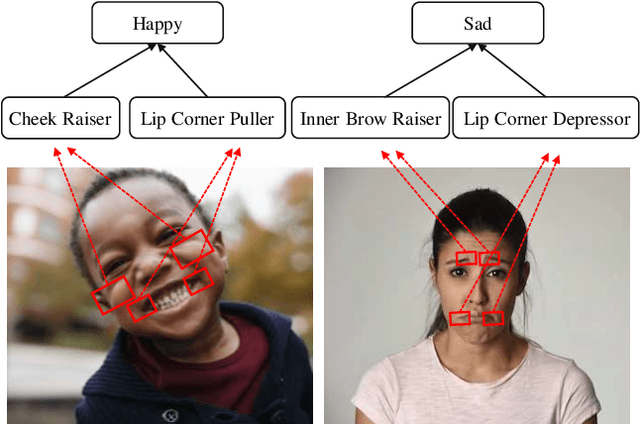
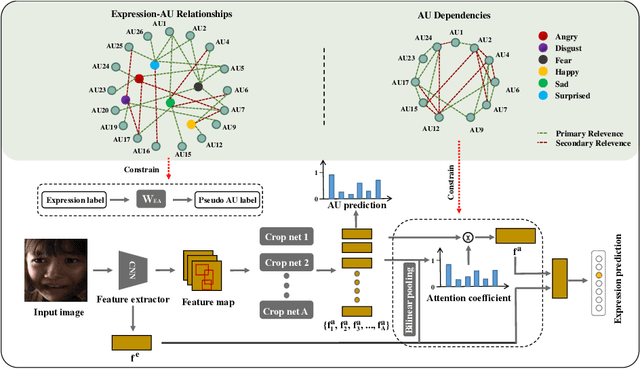
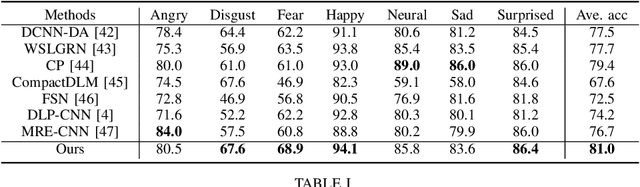

Recognizing human emotion/expressions automatically is quite an expected ability for intelligent robotics, as it can promote better communication and cooperation with humans. Current deep-learning-based algorithms may achieve impressive performance in some lab-controlled environments, but they always fail to recognize the expressions accurately for the uncontrolled in-the-wild situation. Fortunately, facial action units (AU) describe subtle facial behaviors, and they can help distinguish uncertain and ambiguous expressions. In this work, we explore the correlations among the action units and facial expressions, and devise an AU-Expression Knowledge Constrained Representation Learning (AUE-CRL) framework to learn the AU representations without AU annotations and adaptively use representations to facilitate facial expression recognition. Specifically, it leverages AU-expression correlations to guide the learning of the AU classifiers, and thus it can obtain AU representations without incurring any AU annotations. Then, it introduces a knowledge-guided attention mechanism that mines useful AU representations under the constraint of AU-expression correlations. In this way, the framework can capture local discriminative and complementary features to enhance facial representation for facial expression recognition. We conduct experiments on the challenging uncontrolled datasets to demonstrate the superiority of the proposed framework over current state-of-the-art methods.
Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting
Dec 08, 2020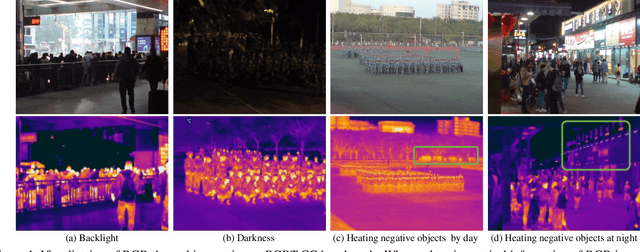
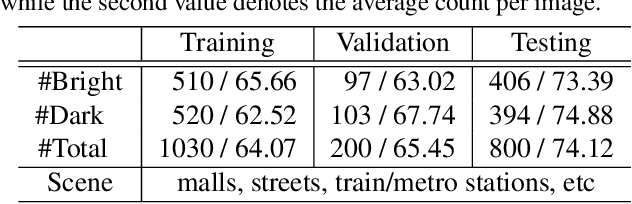
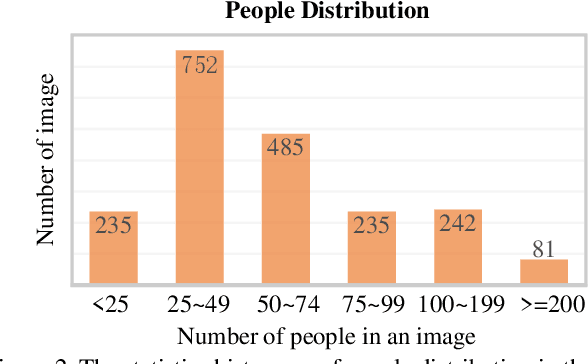
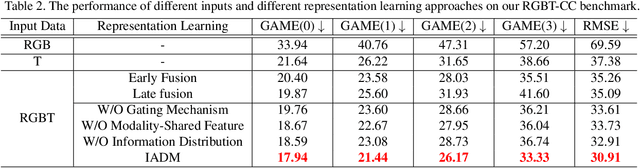
Crowd counting is a fundamental yet challenging problem, which desires rich information to generate pixel-wise crowd density maps. However, most previous methods only utilized the limited information of RGB images and may fail to discover the potential pedestrians in unconstrained environments. In this work, we find that incorporating optical and thermal information can greatly help to recognize pedestrians. To promote future researches in this field, we introduce a large-scale RGBT Crowd Counting (RGBT-CC) benchmark, which contains 2,030 pairs of RGB-thermal images with 138,389 annotated people. Furthermore, to facilitate the multimodal crowd counting, we propose a cross-modal collaborative representation learning framework, which consists of multiple modality-specific branches, a modality-shared branch, and an Information Aggregation-Distribution Module (IADM) to fully capture the complementary information of different modalities. Specifically, our IADM incorporates two collaborative information transfer components to dynamically enhance the modality-shared and modality-specific representations with a dual information propagation mechanism. Extensive experiments conducted on the RGBT-CC benchmark demonstrate the effectiveness of our framework for RGBT crowd counting. Moreover, the proposed approach is universal for multimodal crowd counting and is also capable to achieve superior performance on the ShanghaiTechRGBD dataset.
Knowledge-Guided Multi-Label Few-Shot Learning for General Image Recognition
Sep 20, 2020
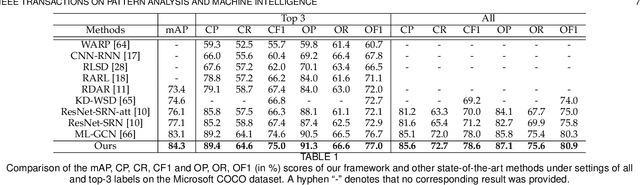
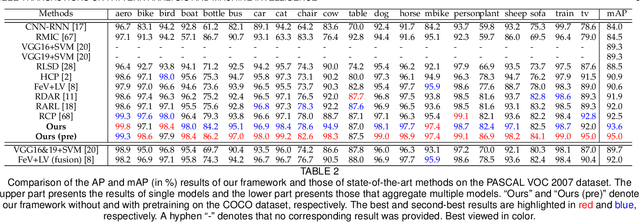
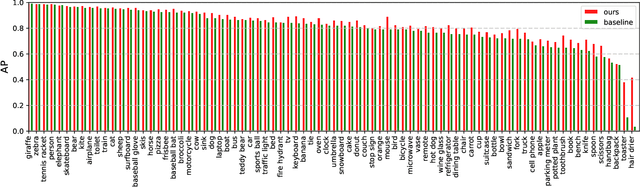
Recognizing multiple labels of an image is a practical yet challenging task, and remarkable progress has been achieved by searching for semantic regions and exploiting label dependencies. However, current works utilize RNN/LSTM to implicitly capture sequential region/label dependencies, which cannot fully explore mutual interactions among the semantic regions/labels and do not explicitly integrate label co-occurrences. In addition, these works require large amounts of training samples for each category, and they are unable to generalize to novel categories with limited samples. To address these issues, we propose a knowledge-guided graph routing (KGGR) framework, which unifies prior knowledge of statistical label correlations with deep neural networks. The framework exploits prior knowledge to guide adaptive information propagation among different categories to facilitate multi-label analysis and reduce the dependency of training samples. Specifically, it first builds a structured knowledge graph to correlate different labels based on statistical label co-occurrence. Then, it introduces the label semantics to guide learning semantic-specific features to initialize the graph, and it exploits a graph propagation network to explore graph node interactions, enabling learning contextualized image feature representations. Moreover, we initialize each graph node with the classifier weights for the corresponding label and apply another propagation network to transfer node messages through the graph. In this way, it can facilitate exploiting the information of correlated labels to help train better classifiers. We conduct extensive experiments on the traditional multi-label image recognition (MLR) and multi-label few-shot learning (ML-FSL) tasks and show that our KGGR framework outperforms the current state-of-the-art methods by sizable margins on the public benchmarks.
Look into Facial Expression Domain Adaptation: Adversarial Graph Learning and A Fair Evaluation Benchmark
Aug 27, 2020

To address the problem of data inconsistencies among different facial expression recognition (FER) datasets, many cross-domain FER methods (CD-FERs) have been extensively devised in recent years. Although each declares to achieve superior performance, fair comparisons are lacking due to the inconsistent choices of the source/target datasets and feature extractors. In this work, we first analyze the performance effect caused by these inconsistent choices, and then re-implement some well-performing CD-FER and recently published domain adaptation algorithms. We ensure that all these algorithms adopt the same source datasets and feature extractors for fair CD-FER evaluations. We find that most of the current leading algorithms use adversarial learning to learn holistic domain-invariant features to mitigate domain shifts. However, these algorithms ignore local features, which are more transferable across different datasets and carry more detailed content for fine-grained adaptation. To address these issues, we integrate graph representation propagation with adversarial learning for cross-domain holistic-local feature co-adaptation by developing a novel adversarial graph representation adaptation (AGRA) framework. Specifically, it first builds two graphs to correlate holistic and local regions within each domain and across different domains, respectively. Then, it extracts holistic-local features from the input image and uses learnable per-class statistical distributions to initialize the corresponding graph nodes. Finally, two stacked graph convolution networks (GCNs) are adopted to propagate holistic-local features within each domain to explore their interaction and across different domains for holistic-local feature co-adaptation. We conduct extensive and fair evaluations on several popular benchmarks and show that the proposed AGRA framework outperforms previous state-of-the-art methods.
Adversarial Graph Representation Adaptation for Cross-Domain Facial Expression Recognition
Aug 04, 2020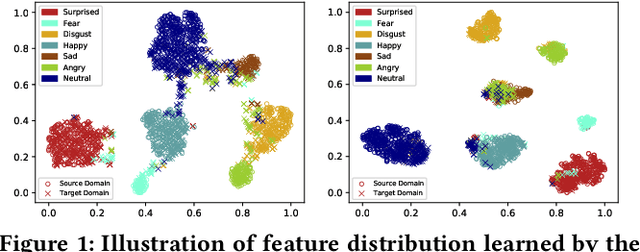
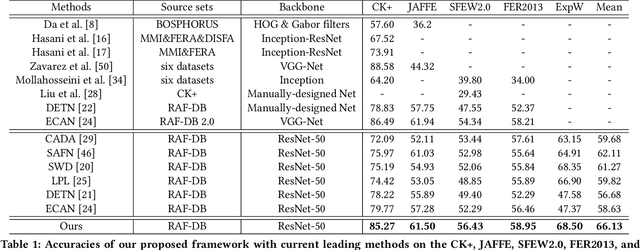
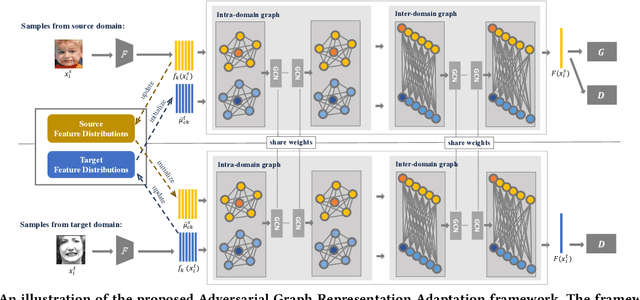
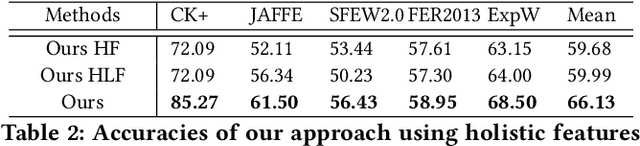
Data inconsistency and bias are inevitable among different facial expression recognition (FER) datasets due to subjective annotating process and different collecting conditions. Recent works resort to adversarial mechanisms that learn domain-invariant features to mitigate domain shift. However, most of these works focus on holistic feature adaptation, and they ignore local features that are more transferable across different datasets. Moreover, local features carry more detailed and discriminative content for expression recognition, and thus integrating local features may enable fine-grained adaptation. In this work, we propose a novel Adversarial Graph Representation Adaptation (AGRA) framework that unifies graph representation propagation with adversarial learning for cross-domain holistic-local feature co-adaptation. To achieve this, we first build a graph to correlate holistic and local regions within each domain and another graph to correlate these regions across different domains. Then, we learn the per-class statistical distribution of each domain and extract holistic-local features from the input image to initialize the corresponding graph nodes. Finally, we introduce two stacked graph convolution networks to propagate holistic-local feature within each domain to explore their interaction and across different domains for holistic-local feature co-adaptation. In this way, the AGRA framework can adaptively learn fine-grained domain-invariant features and thus facilitate cross-domain expression recognition. We conduct extensive and fair experiments on several popular benchmarks and show that the proposed AGRA framework achieves superior performance over previous state-of-the-art methods.
Fine-Grained Image Captioning with Global-Local Discriminative Objective
Jul 21, 2020

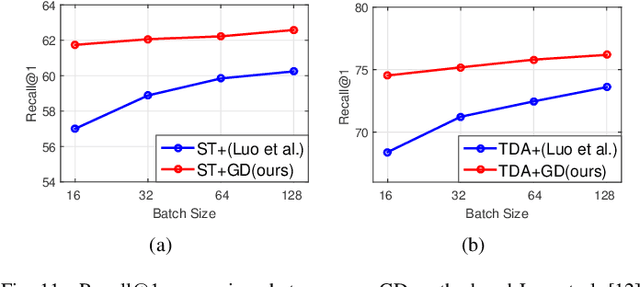
Significant progress has been made in recent years in image captioning, an active topic in the fields of vision and language. However, existing methods tend to yield overly general captions and consist of some of the most frequent words/phrases, resulting in inaccurate and indistinguishable descriptions (see Figure 1). This is primarily due to (i) the conservative characteristic of traditional training objectives that drives the model to generate correct but hardly discriminative captions for similar images and (ii) the uneven word distribution of the ground-truth captions, which encourages generating highly frequent words/phrases while suppressing the less frequent but more concrete ones. In this work, we propose a novel global-local discriminative objective that is formulated on top of a reference model to facilitate generating fine-grained descriptive captions. Specifically, from a global perspective, we design a novel global discriminative constraint that pulls the generated sentence to better discern the corresponding image from all others in the entire dataset. From the local perspective, a local discriminative constraint is proposed to increase attention such that it emphasizes the less frequent but more concrete words/phrases, thus facilitating the generation of captions that better describe the visual details of the given images. We evaluate the proposed method on the widely used MS-COCO dataset, where it outperforms the baseline methods by a sizable margin and achieves competitive performance over existing leading approaches. We also conduct self-retrieval experiments to demonstrate the discriminability of the proposed method.
Efficient Crowd Counting via Structured Knowledge Transfer
Apr 26, 2020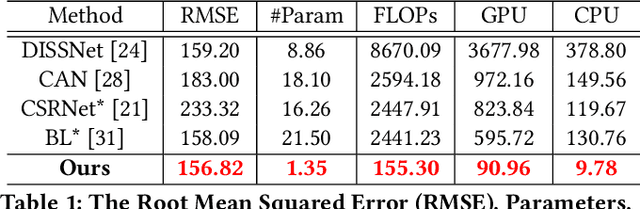
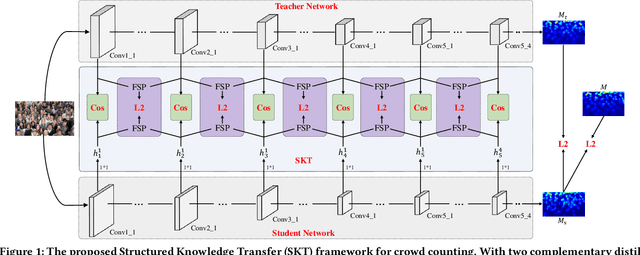

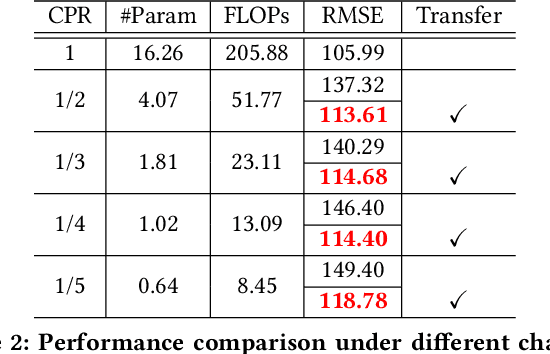
Crowd counting is an application-oriented task and its inference efficiency is crucial for real-world applications. However, most previous works relied on heavy backbone networks and required prohibitive run-time consumption, which would seriously restrict their deployment scopes and cause poor scalability. To liberate these crowd counting models, we propose a novel Structured Knowledge Transfer (SKT) framework, which fully exploits the structured knowledge of a well-trained teacher network to generate a lightweight but still highly effective student network. Specifically, it is integrated with two complementary transfer modules, including an Intra-Layer Pattern Transfer which sequentially distills the knowledge embedded in layer-wise features of the teacher network to guide feature learning of the student network and an Inter-Layer Relation Transfer which densely distills the cross-layer correlation knowledge of the teacher to regularize the student's feature evolution. In this way, our student network can derive the layer-wise and cross-layer knowledge from the teacher network to learn compact yet effective features. Extensive evaluations on three benchmarks well demonstrate the effectiveness of our SKT for extensive crowd counting models. In particular, only using around $6\%$ of the parameters and computation cost of original models, our distilled VGG-based models obtain at least 6.5$\times$ speed-up on an Nvidia 1080 GPU and even achieve state-of-the-art performance.