 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
May 14, 2026Memory is essential for large vision-language models (LVLMs) to handle long, multimodal interactions, with two method directions providing this capability: long-context LVLMs and memory-augmented agents. However, no existing benchmark conducts a systematic comparison of the two on questions that genuinely require multimodal evidence. To close this gap, we introduce MEMLENS, a comprehensive benchmark for memory in multimodal multi-session conversations, comprising 789 questions across five memory abilities (information extraction, multi-session reasoning, temporal reasoning, knowledge update, and answer refusal) at four standard context lengths (32K-256K tokens) under a cross-modal token-counting scheme. An image-ablation study confirms that solving MEMLENS requires visual evidence: removing evidence images drops two frontier LVLMs below 2% accuracy on the 80.4% of questions whose evidence includes images. Evaluating 27 LVLMs and 7 memory-augmented agents, we find that long-context LVLMs achieve high short-context accuracy through direct visual grounding but degrade as conversations grow, whereas memory agents are length-stable but lose visual fidelity under storage-time compression. Multi-session reasoning caps most systems below 30%, and neither approach alone solves the task. These results motivate hybrid architectures that combine long-context attention with structured multimodal retrieval. Our code is available at https://github.com/xrenaf/MEMLENS.
Statistical Inference with Stochastic Gradient Algorithms
Jul 25, 2022
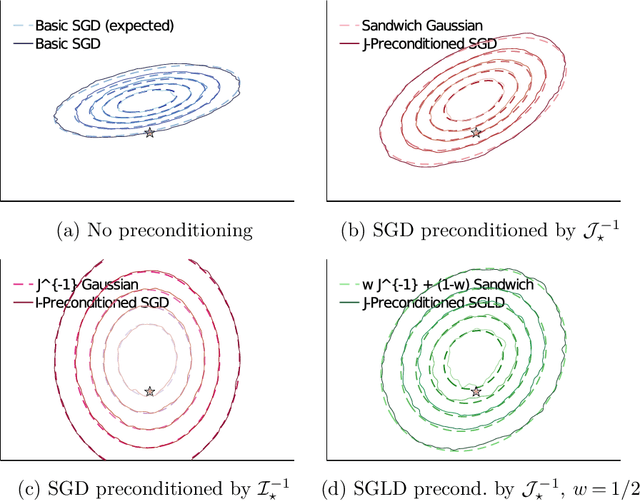
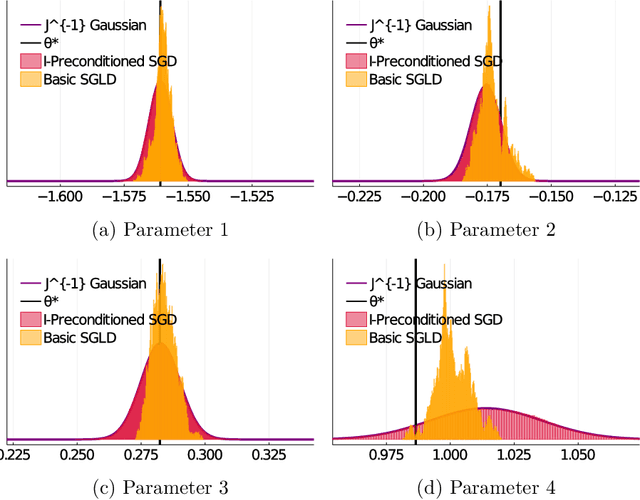
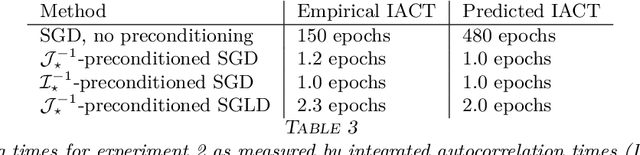
Stochastic gradient algorithms are widely used for both optimization and sampling in large-scale learning and inference problems. However, in practice, tuning these algorithms is typically done using heuristics and trial-and-error rather than rigorous, generalizable theory. To address this gap between theory and practice, we novel insights into the effect of tuning parameters by characterizing the large-sample behavior of iterates of a very general class of preconditioned stochastic gradient algorithms with fixed step size. In the optimization setting, our results show that iterate averaging with a large fixed step size can result in statistically efficient approximation of the (local) M-estimator. In the sampling context, our results show that with appropriate choices of tuning parameters, the limiting stationary covariance can match either the Bernstein--von Mises limit of the posterior, adjustments to the posterior for model misspecification, or the asymptotic distribution of the MLE; and that with a naive tuning the limit corresponds to none of these. Moreover, we argue that an essentially independent sample from the stationary distribution can be obtained after a fixed number of passes over the dataset. We validate our asymptotic results in realistic finite-sample regimes via several experiments using simulated and real data. Overall, we demonstrate that properly tuned stochastic gradient algorithms with constant step size offer a computationally efficient and statistically robust approach to obtaining point estimates or posterior-like samples.