 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom User Interface to Agent Interface: Efficiency Optimization of UI Representations for LLM Agents
Dec 15, 2025



While Large Language Model (LLM) agents show great potential for automated UI navigation such as automated UI testing and AI assistants, their efficiency has been largely overlooked. Our motivating study reveals that inefficient UI representation creates a critical performance bottleneck. However, UI representation optimization, formulated as the task of automatically generating programs that transform UI representations, faces two unique challenges. First, the lack of Boolean oracles, which traditional program synthesis uses to decisively validate semantic correctness, poses a fundamental challenge to co-optimization of token efficiency and completeness. Second, the need to process large, complex UI trees as input while generating long, compositional transformation programs, making the search space vast and error-prone. Toward addressing the preceding limitations, we present UIFormer, the first automated optimization framework that synthesizes UI transformation programs by conducting constraint-based optimization with structured decomposition of the complex synthesis task. First, UIFormer restricts the program space using a domain-specific language (DSL) that captures UI-specific operations. Second, UIFormer conducts LLM-based iterative refinement with correctness and efficiency rewards, providing guidance for achieving the efficiency-completeness co-optimization. UIFormer operates as a lightweight plugin that applies transformation programs for seamless integration with existing LLM agents, requiring minimal modifications to their core logic. Evaluations across three UI navigation benchmarks spanning Android and Web platforms with five LLMs demonstrate that UIFormer achieves 48.7% to 55.8% token reduction with minimal runtime overhead while maintaining or improving agent performance. Real-world industry deployment at WeChat further validates the practical impact of UIFormer.
Data Sanity Check for Deep Learning Systems via Learnt Assertions
Sep 28, 2019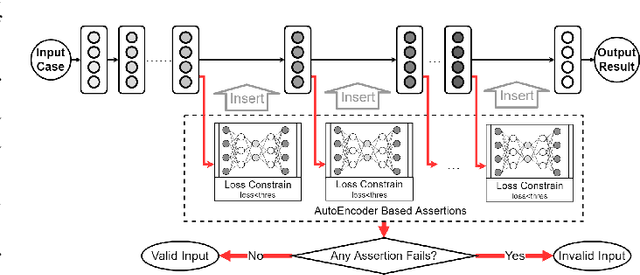
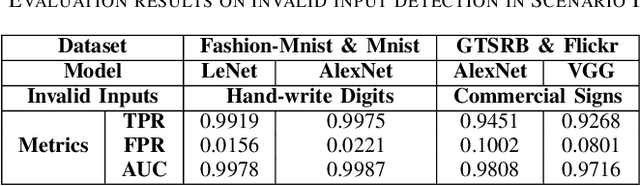
Reliability is a critical consideration to DL-based systems. But the statistical nature of DL makes it quite vulnerable to invalid inputs, i.e., those cases that are not considered in the training phase of a DL model. This paper proposes to perform data sanity check to identify invalid inputs, so as to enhance the reliability of DL-based systems. We design and implement a tool to detect behavior deviation of a DL model when processing an input case. This tool extracts the data flow footprints and conducts an assertion-based validation mechanism. The assertions are built automatically, which are specifically-tailored for DL model data flow analysis. Our experiments conducted with real-world scenarios demonstrate that such an assertion-based data sanity check mechanism is effective in identifying invalid input cases.