 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUXBench: Benchmarking User Experience in AI Assistants
Jun 09, 2026As AI assistants serve millions of users daily, evaluating user experience (UX) beyond general model capability has become increasingly important. We present UXBench, the first user-centric benchmark grounded in real user feedback signals for evaluating preference alignment and dialogue generation. The benchmark consists of three interconnected tasks, UX Judge, UX Eval, and UX Recovery, with 7,400 test instances extracted from over 70K interaction logs of a mainstream Chinese AI assistant. The dataset closely reflects real user distributions, covering 8 scenarios, 83 domains, and diverse failure patterns that pose severe challenges. Extensive experiments on 26 frontier language models provide novel insights into how well models perceive user experience and how improvements in model capability contribute to better dialogue engagement. Through comprehensive analysis of model behavior and performance gaps, we show that user feedback prediction is a learnable capability, where a reward model trained from in-the-wild feedback signals can achieve well-calibrated accuracy. We further document the systematic biases of LLM-as-a-judge evaluation protocols and compare typical response strategies that directly affect user experience. UXBench establishes a new evaluation landscape and calls for greater attention to tailored UX optimization, contributing to a user-centric scaling law that shapes the success of AI assistants.
From User Interface to Agent Interface: Efficiency Optimization of UI Representations for LLM Agents
Dec 15, 2025



While Large Language Model (LLM) agents show great potential for automated UI navigation such as automated UI testing and AI assistants, their efficiency has been largely overlooked. Our motivating study reveals that inefficient UI representation creates a critical performance bottleneck. However, UI representation optimization, formulated as the task of automatically generating programs that transform UI representations, faces two unique challenges. First, the lack of Boolean oracles, which traditional program synthesis uses to decisively validate semantic correctness, poses a fundamental challenge to co-optimization of token efficiency and completeness. Second, the need to process large, complex UI trees as input while generating long, compositional transformation programs, making the search space vast and error-prone. Toward addressing the preceding limitations, we present UIFormer, the first automated optimization framework that synthesizes UI transformation programs by conducting constraint-based optimization with structured decomposition of the complex synthesis task. First, UIFormer restricts the program space using a domain-specific language (DSL) that captures UI-specific operations. Second, UIFormer conducts LLM-based iterative refinement with correctness and efficiency rewards, providing guidance for achieving the efficiency-completeness co-optimization. UIFormer operates as a lightweight plugin that applies transformation programs for seamless integration with existing LLM agents, requiring minimal modifications to their core logic. Evaluations across three UI navigation benchmarks spanning Android and Web platforms with five LLMs demonstrate that UIFormer achieves 48.7% to 55.8% token reduction with minimal runtime overhead while maintaining or improving agent performance. Real-world industry deployment at WeChat further validates the practical impact of UIFormer.
Enhancing Agentic RL with Progressive Reward Shaping and Value-based Sampling Policy Optimization
Dec 08, 2025



Large Language Models (LLMs) empowered with Tool-Integrated Reasoning (TIR) can iteratively plan, call external tools, and integrate returned information to solve complex, long-horizon reasoning tasks. Agentic Reinforcement Learning (Agentic RL) optimizes such models over full tool-interaction trajectories, but two key challenges hinder effectiveness: (1) Sparse, non-instructive rewards, such as binary 0-1 verifiable signals, provide limited guidance for intermediate steps and slow convergence; (2) Gradient degradation in Group Relative Policy Optimization (GRPO), where identical rewards within a rollout group yield zero advantage, reducing sample efficiency and destabilizing training. To address these challenges, we propose two complementary techniques: Progressive Reward Shaping (PRS) and Value-based Sampling Policy Optimization (VSPO). PRS is a curriculum-inspired reward design that introduces dense, stage-wise feedback - encouraging models to first master parseable and properly formatted tool calls, then optimize for factual correctness and answer quality. We instantiate PRS for short-form QA (with a length-aware BLEU to fairly score concise answers) and long-form QA (with LLM-as-a-Judge scoring to prevent reward hacking). VSPO is an enhanced GRPO variant that replaces low-value samples with prompts selected by a task-value metric balancing difficulty and uncertainty, and applies value-smoothing clipping to stabilize gradient updates. Experiments on multiple short-form and long-form QA benchmarks show that PRS consistently outperforms traditional binary rewards, and VSPO achieves superior stability, faster convergence, and higher final performance compared to PPO, GRPO, CISPO, and SFT-only baselines. Together, PRS and VSPO yield LLM-based TIR agents that generalize better across domains.
Automated Proof of Polynomial Inequalities via Reinforcement Learning
Mar 09, 2025



Polynomial inequality proving is fundamental to many mathematical disciplines and finds wide applications in diverse fields. Current traditional algebraic methods are based on searching for a polynomial positive definite representation over a set of basis. However, these methods are limited by truncation degree. To address this issue, this paper proposes an approach based on reinforcement learning to find a {Krivine-basis} representation for proving polynomial inequalities. Specifically, we formulate the inequality proving problem as a linear programming (LP) problem and encode it as a basis selection problem using reinforcement learning (RL), achieving a non-negative {Krivine basis}. Moreover, a fast multivariate polynomial multiplication method based on Fast Fourier Transform (FFT) is employed to enhance the efficiency of action space search. Furthermore, we have implemented a tool called {APPIRL} (Automated Proof of Polynomial Inequalities via Reinforcement Learning). Experimental evaluation on benchmark problems demonstrates the feasibility and effectiveness of our approach. In addition, {APPIRL} has been successfully applied to solve the maximum stable set problem.
MAPLE: Micro Analysis of Pairwise Language Evolution for Few-Shot Claim Verification
Jan 29, 2024



Claim verification is an essential step in the automated fact-checking pipeline which assesses the veracity of a claim against a piece of evidence. In this work, we explore the potential of few-shot claim verification, where only very limited data is available for supervision. We propose MAPLE (Micro Analysis of Pairwise Language Evolution), a pioneering approach that explores the alignment between a claim and its evidence with a small seq2seq model and a novel semantic measure. Its innovative utilization of micro language evolution path leverages unlabelled pairwise data to facilitate claim verification while imposing low demand on data annotations and computing resources. MAPLE demonstrates significant performance improvements over SOTA baselines SEED, PET and LLaMA 2 across three fact-checking datasets: FEVER, Climate FEVER, and SciFact. Data and code are available here: https://github.com/XiaZeng0223/MAPLE
Active PETs: Active Data Annotation Prioritisation for Few-Shot Claim Verification with Pattern Exploiting Training
Aug 18, 2022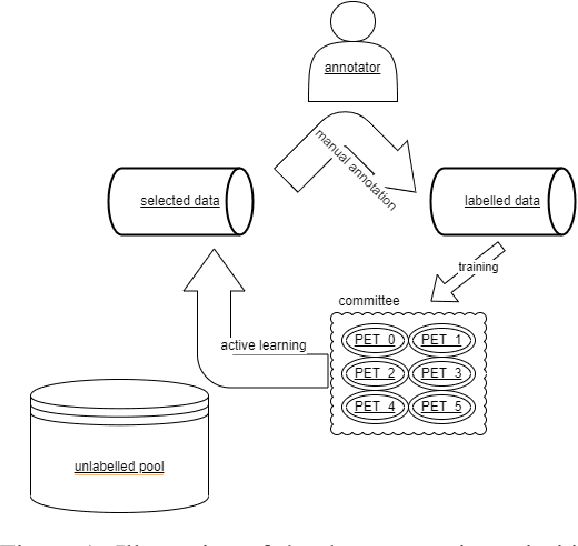
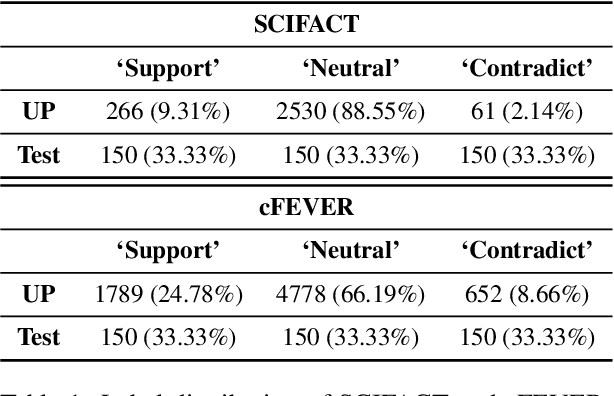
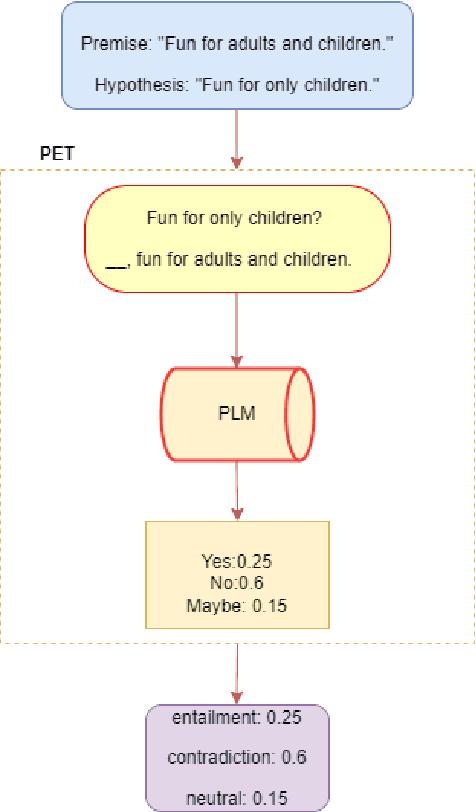
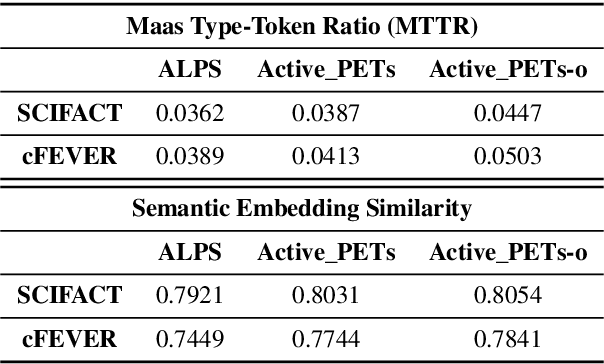
To mitigate the impact of data scarcity on fact-checking systems, we focus on few-shot claim verification. Despite recent work on few-shot classification by proposing advanced language models, there is a dearth of research in data annotation prioritisation that improves the selection of the few shots to be labelled for optimal model performance. We propose Active PETs, a novel weighted approach that utilises an ensemble of Pattern Exploiting Training (PET) models based on various language models, to actively select unlabelled data as candidates for annotation. Using Active PETs for data selection shows consistent improvement over the state-of-the-art active learning method, on two technical fact-checking datasets and using six different pretrained language models. We show further improvement with Active PETs-o, which further integrates an oversampling strategy. Our approach enables effective selection of instances to be labelled where unlabelled data is abundant but resources for labelling are limited, leading to consistently improved few-shot claim verification performance. Our code will be available upon publication.
Aggregating Pairwise Semantic Differences for Few-Shot Claim Veracity Classification
May 11, 2022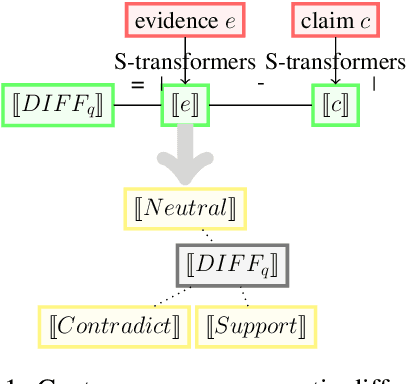
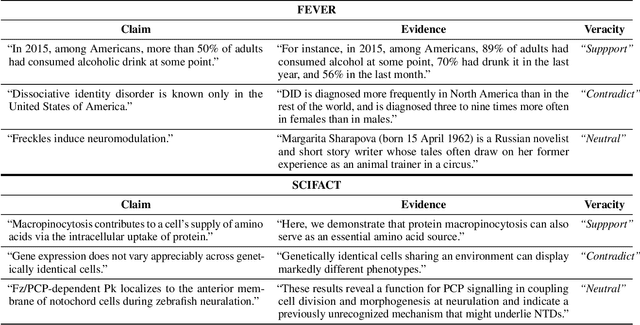
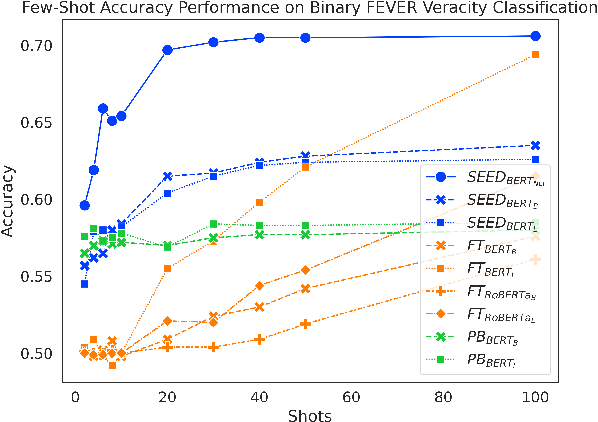
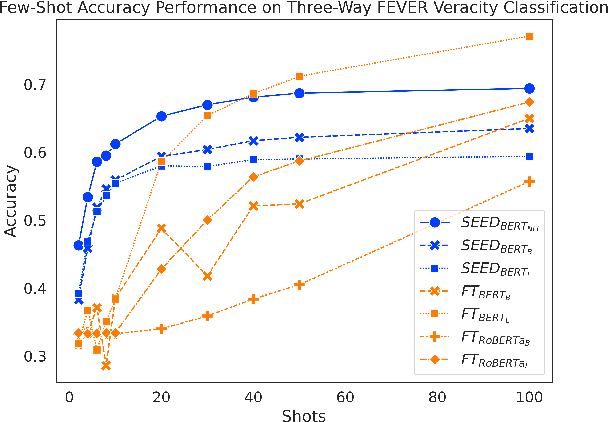
As part of an automated fact-checking pipeline, the claim veracity classification task consists in determining if a claim is supported by an associated piece of evidence. The complexity of gathering labelled claim-evidence pairs leads to a scarcity of datasets, particularly when dealing with new domains. In this paper, we introduce SEED, a novel vector-based method to few-shot claim veracity classification that aggregates pairwise semantic differences for claim-evidence pairs. We build on the hypothesis that we can simulate class representative vectors that capture average semantic differences for claim-evidence pairs in a class, which can then be used for classification of new instances. We compare the performance of our method with competitive baselines including fine-tuned BERT/RoBERTa models, as well as the state-of-the-art few-shot veracity classification method that leverages language model perplexity. Experiments conducted on the FEVER and SCIFACT datasets show consistent improvements over competitive baselines in few-shot settings. Our code is available.
Automated Fact-Checking: A Survey
Sep 23, 2021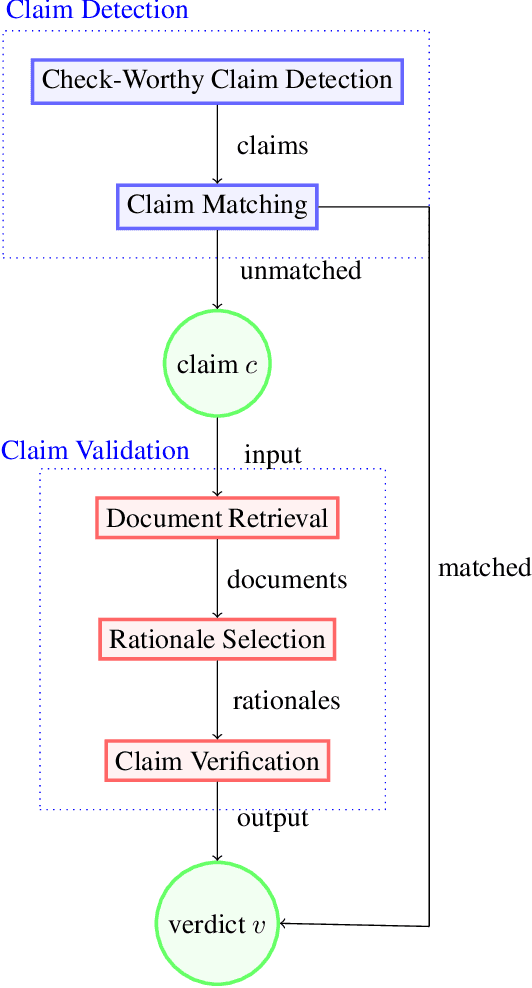
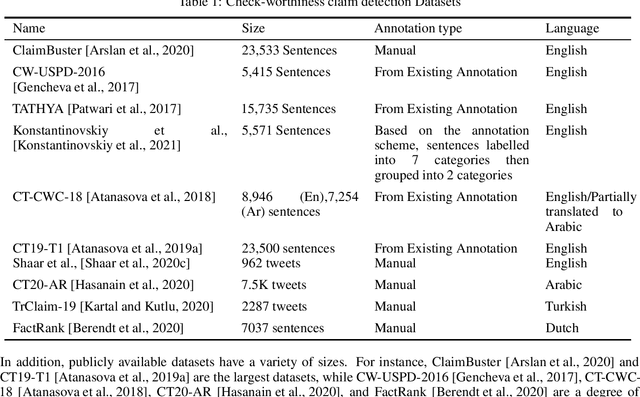
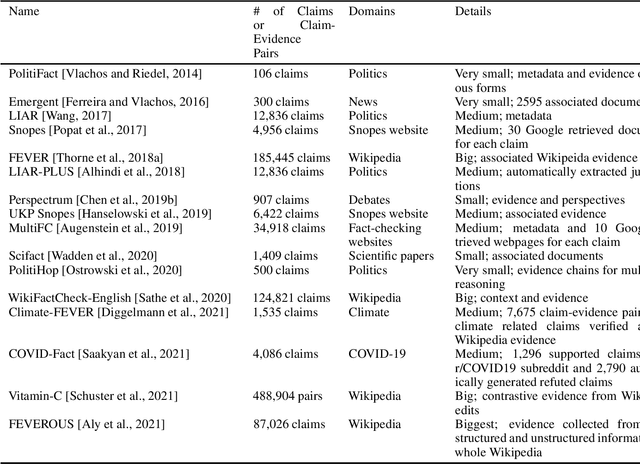
As online false information continues to grow, automated fact-checking has gained an increasing amount of attention in recent years. Researchers in the field of Natural Language Processing (NLP) have contributed to the task by building fact-checking datasets, devising automated fact-checking pipelines and proposing NLP methods to further research in the development of different components. This paper reviews relevant research on automated fact-checking covering both the claim detection and claim validation components.
QMUL-SDS at SCIVER: Step-by-Step Binary Classification for Scientific Claim Verification
Apr 23, 2021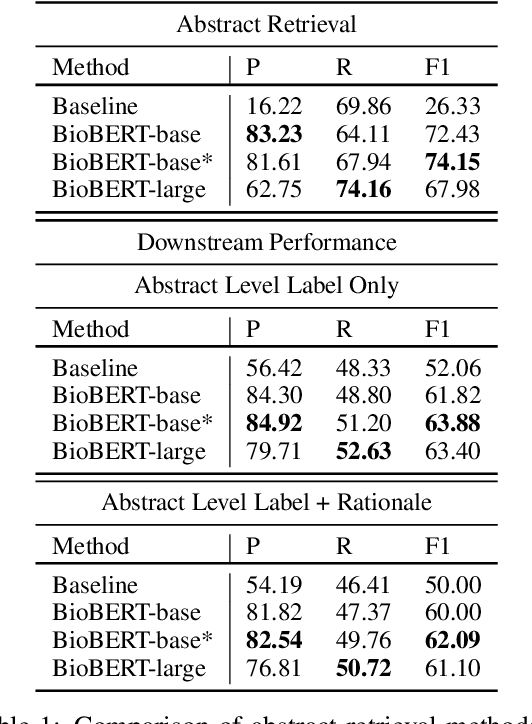
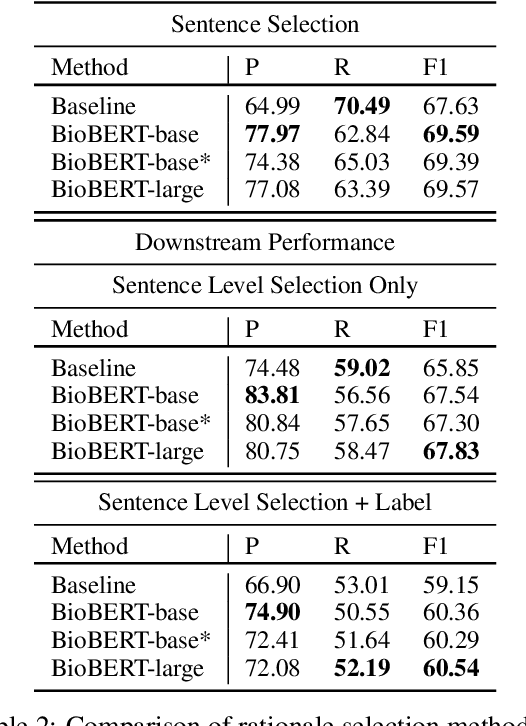
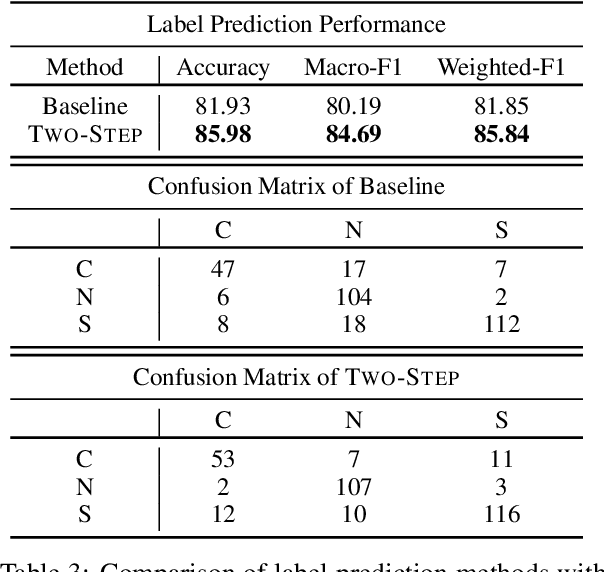
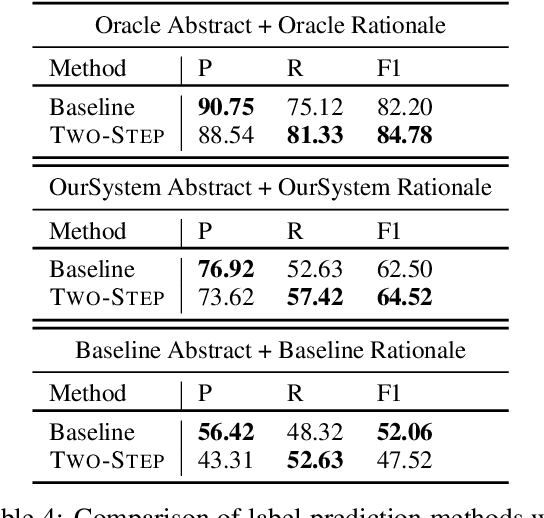
Scientific claim verification is a unique challenge that is attracting increasing interest. The SCIVER shared task offers a benchmark scenario to test and compare claim verification approaches by participating teams and consists in three steps: relevant abstract selection, rationale selection and label prediction. In this paper, we present team QMUL-SDS's participation in the shared task. We propose an approach that performs scientific claim verification by doing binary classifications step-by-step. We trained a BioBERT-large classifier to select abstracts based on pairwise relevance assessments for each <claim, title of the abstract> and continued to train it to select rationales out of each retrieved abstract based on <claim, sentence>. We then propose a two-step setting for label prediction, i.e. first predicting "NOT_ENOUGH_INFO" or "ENOUGH_INFO", then label those marked as "ENOUGH_INFO" as either "SUPPORT" or "CONTRADICT". Compared to the baseline system, we achieve substantial improvements on the dev set. As a result, our team is the No. 4 team on the leaderboard.
Learning Safe Neural Network Controllers with Barrier Certificates
Sep 18, 2020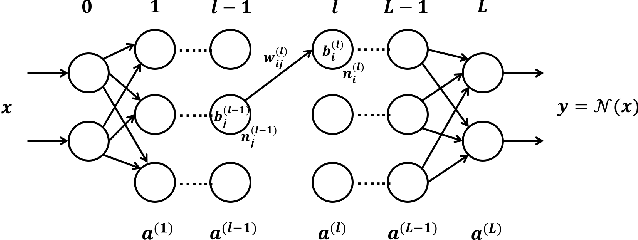

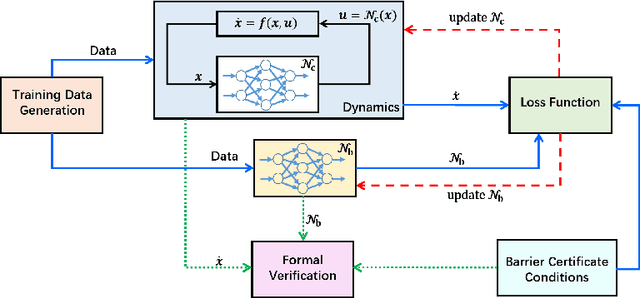
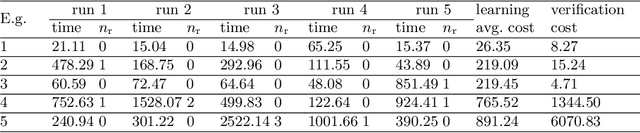
We provide a novel approach to synthesize controllers for nonlinear continuous dynamical systems with control against safety properties. The controllers are based on neural networks (NNs). To certify the safety property we utilize barrier functions, which are represented by NNs as well. We train the controller-NN and barrier-NN simultaneously, achieving a verification-in-the-loop synthesis. We provide a prototype tool nncontroller with a number of case studies. The experiment results confirm the feasibility and efficacy of our approach.