 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention Free Transformer
May 28, 2021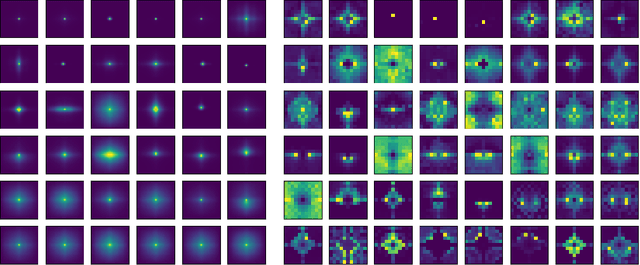

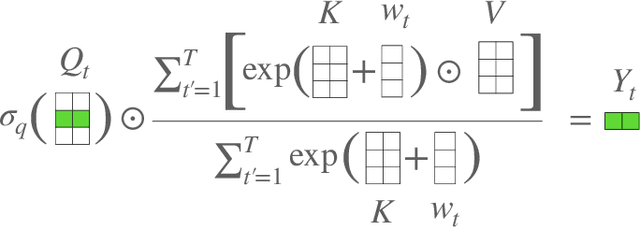
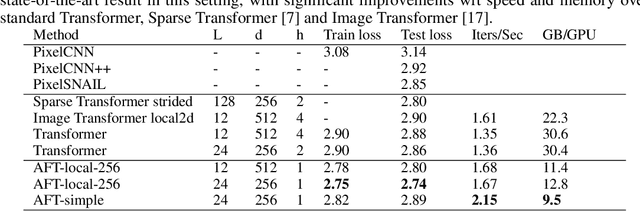
We introduce Attention Free Transformer (AFT), an efficient variant of Transformers that eliminates the need for dot product self attention. In an AFT layer, the key and value are first combined with a set of learned position biases, the result of which is multiplied with the query in an element-wise fashion. This new operation has a memory complexity linear w.r.t. both the context size and the dimension of features, making it compatible to both large input and model sizes. We also introduce AFT-local and AFT-conv, two model variants that take advantage of the idea of locality and spatial weight sharing while maintaining global connectivity. We conduct extensive experiments on two autoregressive modeling tasks (CIFAR10 and Enwik8) as well as an image recognition task (ImageNet-1K classification). We show that AFT demonstrates competitive performance on all the benchmarks, while providing excellent efficiency at the same time.
Uncertainty Weighted Actor-Critic for Offline Reinforcement Learning
May 17, 2021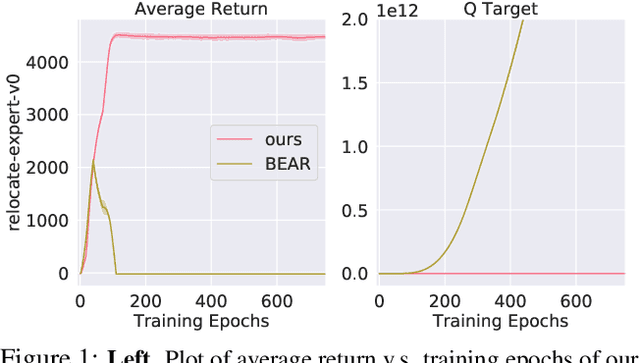
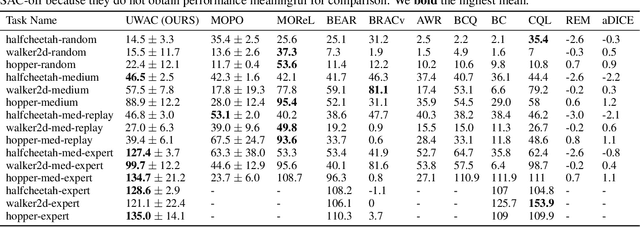
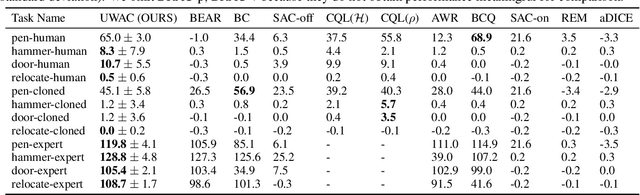
Offline Reinforcement Learning promises to learn effective policies from previously-collected, static datasets without the need for exploration. However, existing Q-learning and actor-critic based off-policy RL algorithms fail when bootstrapping from out-of-distribution (OOD) actions or states. We hypothesize that a key missing ingredient from the existing methods is a proper treatment of uncertainty in the offline setting. We propose Uncertainty Weighted Actor-Critic (UWAC), an algorithm that detects OOD state-action pairs and down-weights their contribution in the training objectives accordingly. Implementation-wise, we adopt a practical and effective dropout-based uncertainty estimation method that introduces very little overhead over existing RL algorithms. Empirically, we observe that UWAC substantially improves model stability during training. In addition, UWAC out-performs existing offline RL methods on a variety of competitive tasks, and achieves significant performance gains over the state-of-the-art baseline on datasets with sparse demonstrations collected from human experts.
Subject-Aware Contrastive Learning for Biosignals
Jun 30, 2020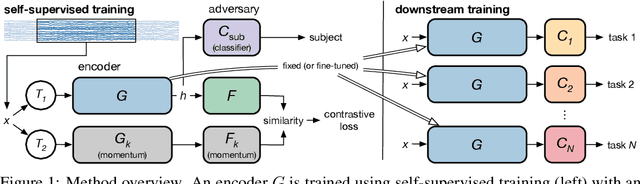

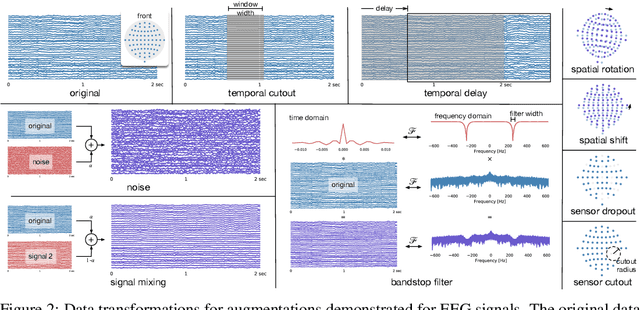
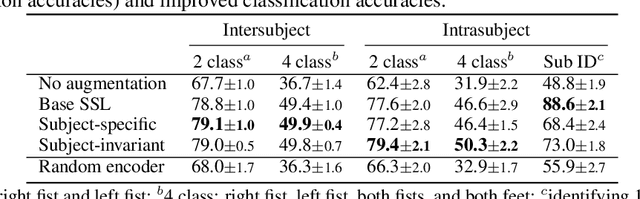
Datasets for biosignals, such as electroencephalogram (EEG) and electrocardiogram (ECG), often have noisy labels and have limited number of subjects (<100). To handle these challenges, we propose a self-supervised approach based on contrastive learning to model biosignals with a reduced reliance on labeled data and with fewer subjects. In this regime of limited labels and subjects, intersubject variability negatively impacts model performance. Thus, we introduce subject-aware learning through (1) a subject-specific contrastive loss, and (2) an adversarial training to promote subject-invariance during the self-supervised learning. We also develop a number of time-series data augmentation techniques to be used with the contrastive loss for biosignals. Our method is evaluated on publicly available datasets of two different biosignals with different tasks: EEG decoding and ECG anomaly detection. The embeddings learned using self-supervision yield competitive classification results compared to entirely supervised methods. We show that subject-invariance improves representation quality for these tasks, and observe that subject-specific loss increases performance when fine-tuning with supervised labels.
Capsules with Inverted Dot-Product Attention Routing
Feb 26, 2020
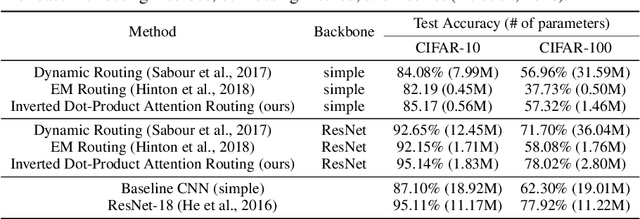
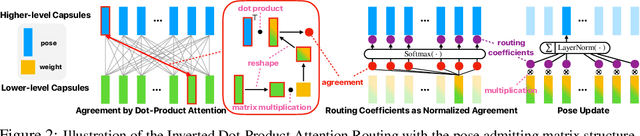
We introduce a new routing algorithm for capsule networks, in which a child capsule is routed to a parent based only on agreement between the parent's state and the child's vote. The new mechanism 1) designs routing via inverted dot-product attention; 2) imposes Layer Normalization as normalization; and 3) replaces sequential iterative routing with concurrent iterative routing. When compared to previously proposed routing algorithms, our method improves performance on benchmark datasets such as CIFAR-10 and CIFAR-100, and it performs at-par with a powerful CNN (ResNet-18) with 4x fewer parameters. On a different task of recognizing digits from overlayed digit images, the proposed capsule model performs favorably against CNNs given the same number of layers and neurons per layer. We believe that our work raises the possibility of applying capsule networks to complex real-world tasks. Our code is publicly available at: https://github.com/apple/ml-capsules-inverted-attention-routing An alternative implementation is available at: https://github.com/yaohungt/Capsules-Inverted-Attention-Routing/blob/master/README.md
Geometric Capsule Autoencoders for 3D Point Clouds
Dec 06, 2019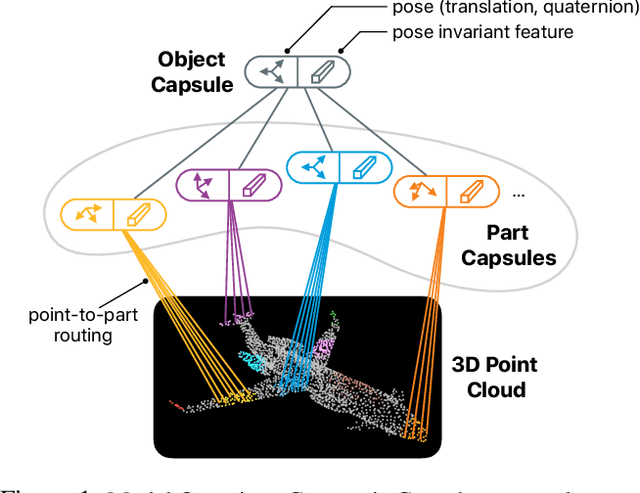

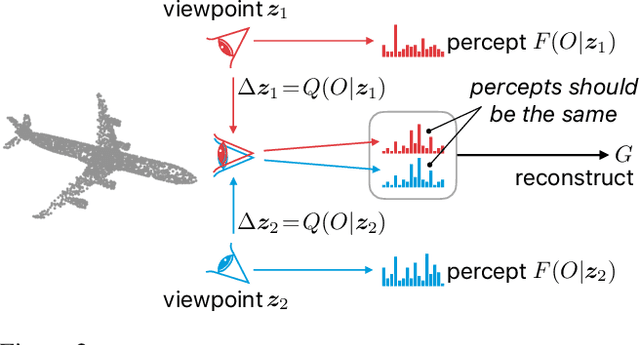
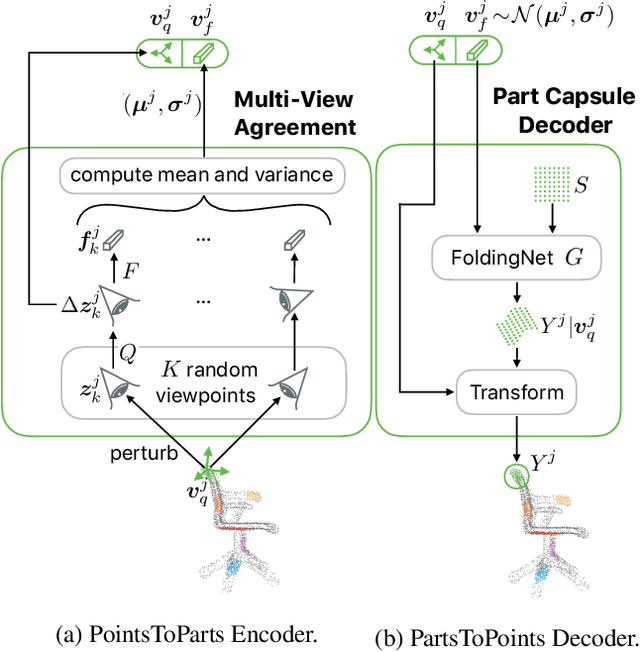
We propose a method to learn object representations from 3D point clouds using bundles of geometrically interpretable hidden units, which we call geometric capsules. Each geometric capsule represents a visual entity, such as an object or a part, and consists of two components: a pose and a feature. The pose encodes where the entity is, while the feature encodes what it is. We use these capsules to construct a Geometric Capsule Autoencoder that learns to group 3D points into parts (small local surfaces), and these parts into the whole object, in an unsupervised manner. Our novel Multi-View Agreement voting mechanism is used to discover an object's canonical pose and its pose-invariant feature vector. Using the ShapeNet and ModelNet40 datasets, we analyze the properties of the learned representations and show the benefits of having multiple votes agree. We perform alignment and retrieval of arbitrarily rotated objects -- tasks that evaluate our model's object identification and canonical pose recovery capabilities -- and obtained insightful results.
A Practical Guide to CNNs and Fisher Vectors for Image Instance Retrieval
Aug 25, 2015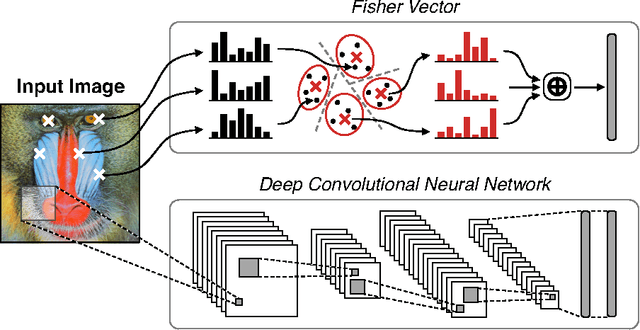
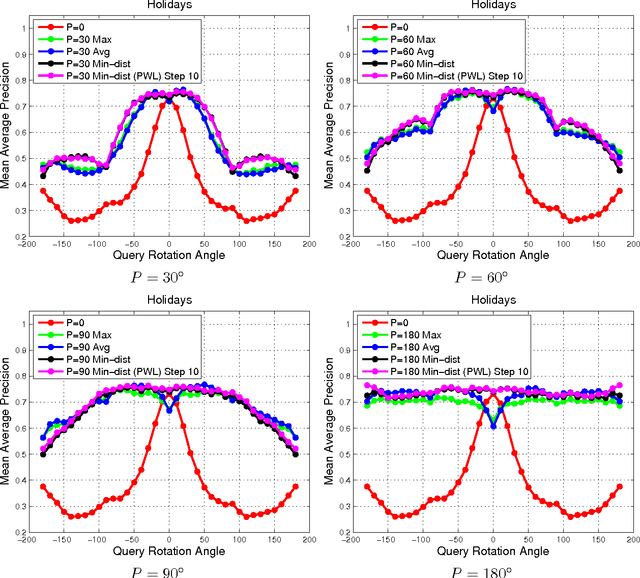
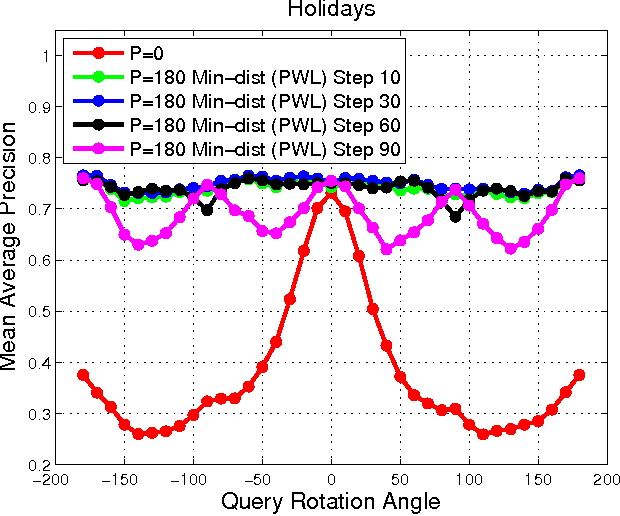
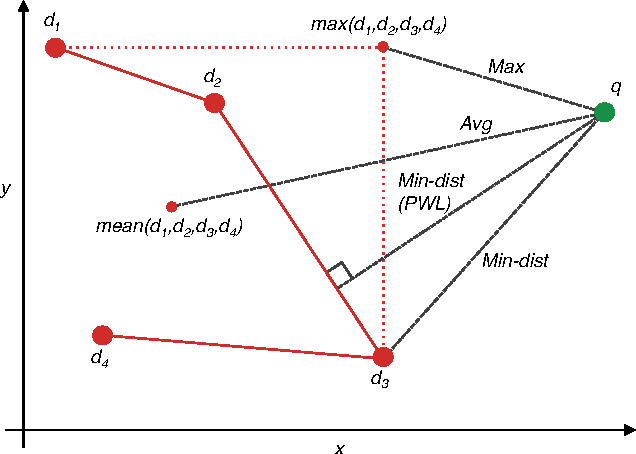
With deep learning becoming the dominant approach in computer vision, the use of representations extracted from Convolutional Neural Nets (CNNs) is quickly gaining ground on Fisher Vectors (FVs) as favoured state-of-the-art global image descriptors for image instance retrieval. While the good performance of CNNs for image classification are unambiguously recognised, which of the two has the upper hand in the image retrieval context is not entirely clear yet. In this work, we propose a comprehensive study that systematically evaluates FVs and CNNs for image retrieval. The first part compares the performances of FVs and CNNs on multiple publicly available data sets. We investigate a number of details specific to each method. For FVs, we compare sparse descriptors based on interest point detectors with dense single-scale and multi-scale variants. For CNNs, we focus on understanding the impact of depth, architecture and training data on retrieval results. Our study shows that no descriptor is systematically better than the other and that performance gains can usually be obtained by using both types together. The second part of the study focuses on the impact of geometrical transformations such as rotations and scale changes. FVs based on interest point detectors are intrinsically resilient to such transformations while CNNs do not have a built-in mechanism to ensure such invariance. We show that performance of CNNs can quickly degrade in presence of rotations while they are far less affected by changes in scale. We then propose a number of ways to incorporate the required invariances in the CNN pipeline. Overall, our work is intended as a reference guide offering practically useful and simply implementable guidelines to anyone looking for state-of-the-art global descriptors best suited to their specific image instance retrieval problem.
Co-Regularized Deep Representations for Video Summarization
Jan 30, 2015
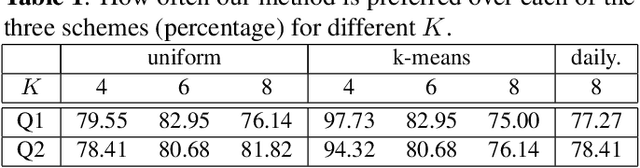
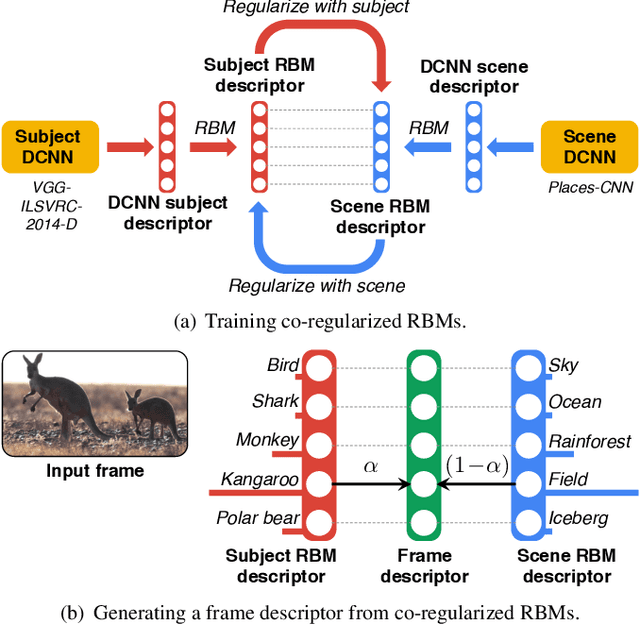
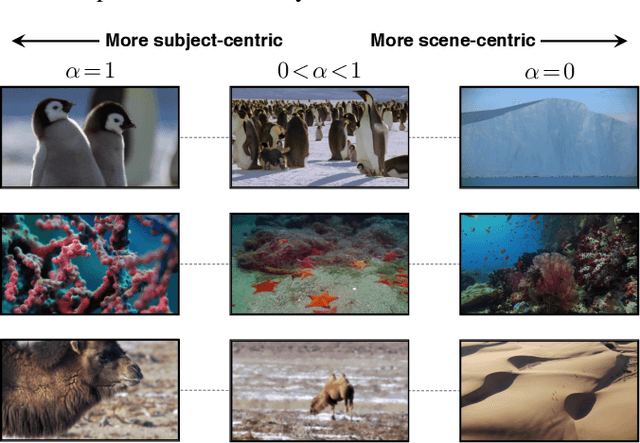
Compact keyframe-based video summaries are a popular way of generating viewership on video sharing platforms. Yet, creating relevant and compelling summaries for arbitrarily long videos with a small number of keyframes is a challenging task. We propose a comprehensive keyframe-based summarization framework combining deep convolutional neural networks and restricted Boltzmann machines. An original co-regularization scheme is used to discover meaningful subject-scene associations. The resulting multimodal representations are then used to select highly-relevant keyframes. A comprehensive user study is conducted comparing our proposed method to a variety of schemes, including the summarization currently in use by one of the most popular video sharing websites. The results show that our method consistently outperforms the baseline schemes for any given amount of keyframes both in terms of attractiveness and informativeness. The lead is even more significant for smaller summaries.
DeepHash: Getting Regularization, Depth and Fine-Tuning Right
Jan 20, 2015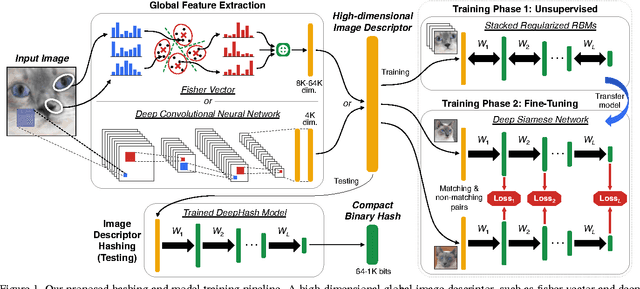
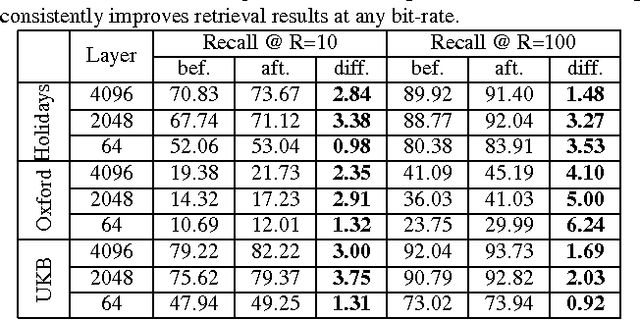
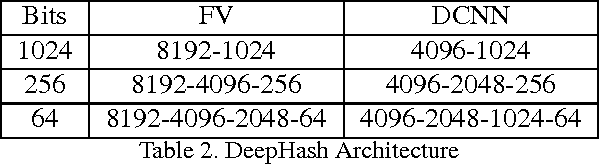
This work focuses on representing very high-dimensional global image descriptors using very compact 64-1024 bit binary hashes for instance retrieval. We propose DeepHash: a hashing scheme based on deep networks. Key to making DeepHash work at extremely low bitrates are three important considerations -- regularization, depth and fine-tuning -- each requiring solutions specific to the hashing problem. In-depth evaluation shows that our scheme consistently outperforms state-of-the-art methods across all data sets for both Fisher Vectors and Deep Convolutional Neural Network features, by up to 20 percent over other schemes. The retrieval performance with 256-bit hashes is close to that of the uncompressed floating point features -- a remarkable 512 times compression.